
Paras tapa parantaa systeemin suorituskykyä ja kapasiteettia on johtaa vaihtelua. Vaihtelu on johtamisen vaakakupin toisella puolella, jolla voidaan hallita toisen puolen hukkien lisääntymistä – alhaista läpimenoa, alhaista käyttöastetta ja pitkiä läpimenoaikoja (Kuva 1). Yhdellä sanalla: parantaa heikkoa tuottavuutta.

Kun vaihtelu lisääntyy, hukat vaakakupin toisella puolella lisääntyvät ja päinvastoin. Kun vaihtelu pienenee, hukat ja kustannukset alenevat. Parhaat organisaatiot, kuten esimerkiksi Toyota tai GE, ovat ottaneet vaihtelun minimoinnin keskeiseksi strategiakseen luomalla erilaisia jatkuvan parantamisen ohjelmia kuten Six Sigma, Lean, Lean Six Sigma jne. päämääränä 0-vaihtelu, 0-virhettä.
Tarvitaanko mitattua dataa vaihtelun hallintaa?
Törmään aina silloin tällöin tilanteeseen, jossa asiakas toteaa, että meillä ei voida käyttää Six Sigmaa, koska meillä ei ole mitattua dataa tai meidän prosessista ei voida mitata mitään. Mitä asiakas tällä toteamuksella voisi tarkoittaa?
Hänellä ei ole massoittain numeroita tai muistiinpanoja tai ehkä hän rajaa mittauksen käsitteen kovin kapeaksi. Kaikki, mikä aisteilla havaitaan (näkö, kuulo, haju, maku, tunto), voidaan muuttaa tai muuttuu dataksi. Voi olla, että tapahtumaa on vahvistettava tai muutettava jollain välineellä ihmisen aistien ulottuville ja herkkyysalueelle (esim. mikroskooppi, erilaiset mittarit jne.).
Käytännössä jokaisella on yllin kyllin dataa jokaisesta asiasta/palvelusta/tuotteesta. Jokaisesta prosessista (tuotanto ja palvelu) voidaan kerätä dataa massoittain. Tarvitaan vain muisti ja muistiinpanoja.
Ongelma ei ole data vaan sen muuttaminen informaatioksi ja tiedoksi. Ongelma on datan hirvittävä määrä, jota on rajattava oikein! Kaikkihan tunnemme Googlen – on vain keksittävä oikea rajaus – hakusana tai sanat – ja vastaus löytyy!
Data ja informaatio ovat avainasemassa tehtäessä tietoperusteisia tutkimuksia ja päätöksiä vaihtelun johtamisessa, mutta onko kaikki data tarpeen ja kuinka dataa tulisi kerätä? Itse asiassa asiakkaiden huoli – erityisesti palvelupuolella – kääntyykin päinvastaiseksi. Kuinka rajaamme ja vähennämme datan määrää, jotta voimme muodostaa siitä informaation?
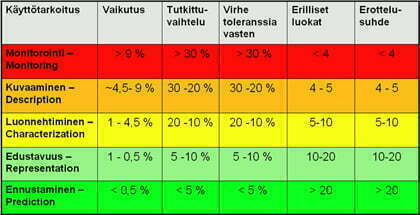
Käytämme käsitettä rationaalinen näytteenotto tai yleisemmin datan keräyksen strategiat. Artikkelissa ”Kuinka lähestyä tiedon – datan – keräämistä?”/1/ käsitellään viittä erilaista datan käyttötarkoitusta – monitorointi, kuvaaminen, luonnehtiminen, edustavuus ja ennustaminen – ja niiden vaatimaa datan oikeellisuutta.
Datan keräyksen ja rationaalisen näytteenoton ongelmaa voidaan tarkastella myös toisesta suunnasta. Christine M. Anderson-Cook ja Connie M. Borror esittävät erinomaisessa artikkelissa ”Paving The Way – Seven data collection strategies to enhance your quality analyses”/2/ taulukon seitsemästä erilaisesta datan keräysstrategiasta, joita käytetään Lean Six Sigmassa. Taulukko 1
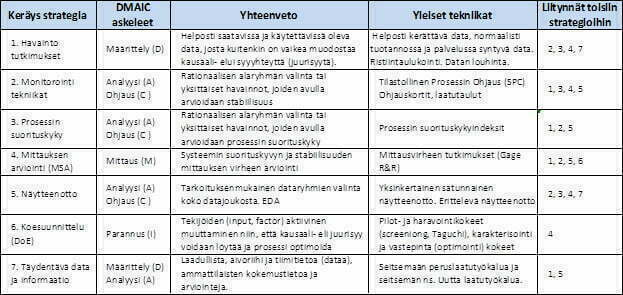
Leanissa ja Six Sigmassa edetään suorituskyvyn parannuksessa, vaihtelun johtamisessa, askelittain kohteen määrittelyvaiheesta mittauksen, analysoinnin ja parannuksen kautta ohjausvaiheeseen (DMAIC, Define, Measure, Analysis, Improve, Control). Jokaisessa vaiheessa esitetään ”kysymys tai kysymyksiä”, joihin vastataan datasta muodostetun informaation avulla. Molemmat Lean ja Six Sigma parannusstrategiat muodostuvat viidestä kysymyssarjasta, jotka ovat lähes identtiset. Kuva 2.
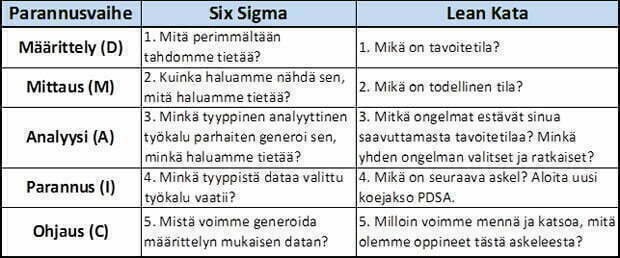
Näin muodostuu prosessi, joka mahdollistaa parannuksen ja innovaation. Jokainen parannus on vähintään pienimuotoinen innovaatio, mutta usein kuitenkin radikaali uusi oivallus muuttaa juurisyytä. Juurisyyn kaivamiseksi ja todistamiseksi tarvitsemme tämän prosessin, joka huipentuu koesuunnitteluun (taulukko 1, kohta 6 ja kuva 2, kohta 4), jolle ei ole olemassa rinnakkaisstrategioita. DOE/PDCA on ainoa tapa todistaa syy-seuraus suhde.
Seuraavassa lyhyet selitykset ja kommentit 7:ään datan keräyksen strategiaan.
1. Havaintotutkimukset (Observational studies)
Havaintotutkimukset tai tuotanto-/palveludata on kaikkein yleisintä dataa, jota kerätään yrityksissä hyvin erilaisilla menetelmillä ja kirjaustavoilla. Joissain yrityksissä (paperitehtaat, sellutehtaat, kemian tehtaat jne) tietoa tulee mittalaitteilta hirvittävät määrät. Toisessa äärilaidassa on pienet konepajat ja palveluyrittäjät, joille kirjautuu vain tulevat ja lähtevät laskut ja tietysti henkilöstön muistiin taltioituva kokemusdata. Data voi olla mitä vaan sanallisesta datasta jatkuvaan numerodataan.
Havaintodatan keskeisenä roolina on antaa yleiskuva ja määritellä, missä suunnassa olisi parannusmahdollisuus tai ongelma. Tämän datan perusteella ei pitäisi tehdä päätelmiä syistä tai korjaavista toimenpiteistä. Tähän dataan liittyy lukuisia vaaroja ja ongelmia:
- Otaksutaan, että havainnot edustavat koko joukkoa tuotteista tai palveluista ja yleistys tehdään myös tuleviin tapahtumiin (yleistysongelma).
- Otaksutaan, että on olemassa kausaalisuus eli syy inputtien ja ulostulojen välillä esimerkiksi reklamaatioiden syytutkimuksessa.
- Ei huomata puuttuvaa ei-mitattua tekijää, joka vaikuttaa ulostuloon enemmän kuin ne seikat, joita mitataan ja joiden muutos näytti virheellisesti aiheuttaneen ongelman.
- Otetaan näyte osasta koko joukkoa, joka onkin biasoitunut (jotenkin erilainen) ja vääristää tuloksen.
Esitin edellisessä artikkelissani ”Kuinka hallitsen tuotanto- ja palveluprosesseja – Ohjaanko toleranssirajoilla vai SPC-rajoilla” /3/ datan louhinnan (data mining) mahdollistavaa datankeräysmallia tietueittain. Kuva 3.
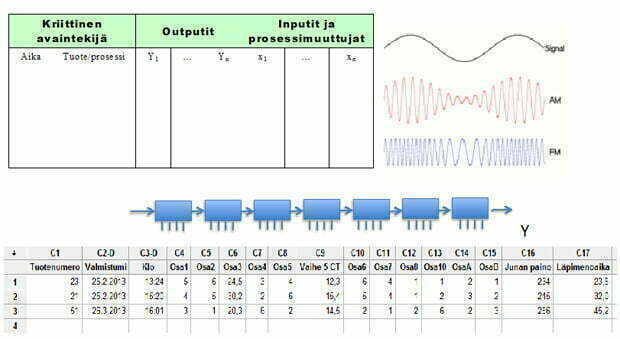
Tämän tyyppisen havaintodatan keräys on tänä päivänä mahdollista ja edullista, kun muistitila ja tietokoneet eivät juuri maksa mitään.
Oleellista havaintodatassa on, että
- Näyte todella edustaa ja on käyttökelpoinen tutkimuksen tarpeeseen. Voidaanko datan perusteella määrittää avainerot ajan, tuotteen ja prosessin eri kuvioiden välillä.
- Datan laatu. Kuinka yksiköt (käytätkö yhtä tapahtumaa vai 10 tapahtuman keskiarvoa) on valittu? Kerätäänkö kaikki oleelliset input -tekijät ja niiden muuttujat niin, että ne eivät sekoitu keskenään?
- Kuinka dataa voi käyttää tehtäessä johtopäätöksiä, jotka ovat oikeita ja johtavat kausaliteetin eli syyn määrittämiseen oikein.
2. Monitorointitekniikat (Monitoring techniques)
Vaihtelua esiintyy kaikissa prosesseissa riippumatta siitä, kuinka hyvin niitä ohjataan ja johdetaan. Vaihtelua on kahden tyyppistä:
- Satunnainen eli systeemin aiheuttama vaihtelu (common causes), joka on luonteenomaista prosessille ja on satunnaista. Tämä muodostaa prosessin suorituskyvyn, jota Lean Six Sigmalla pienennetään (parannetaan). Suomeksi sanottuna syytä ei tästä datasta voida löytää. Krooninen sairaus!
- Erityissyyvaihtelu (assignable cause), jonka on aiheuttanut jokin häiriö tai ulkoinen syy, joka täytyy tunnistaa ja poistaa. Epästabiilisuuden lähde. Syy voidaan tunnistaa. Erityissyy poistetaan ongelmanratkaisulla (hoidetaan) Akuutti sairaus!
Erityissyyvaihtelu on kaikkein ongelmallisin vaihtelun lähde. Se aiheuttaa epästabiilisuutta ja ohjauksen menetyksen. Se on myös ennustamatonta. Ohjauskorteilla ja laatutauluilla erityissyyt saadaan suodatettua, diagnostisoitua, näkyviin (tunnistettua) ja toivon mukaan ratkaistua. Kyseessä on ongelmanratkaisu.
Six Sigman DMAIC-prosessissa ohjauskortit ovat hyvin yleisessä käytössä monessa vaiheessa. Ohjausvaiheessa ne ovat päätyökalu. Käsittelin syvemmin ohjauskortteja edellisessä artikkelissa/3/.
3. Prosessin suorituskyky (Process capability)
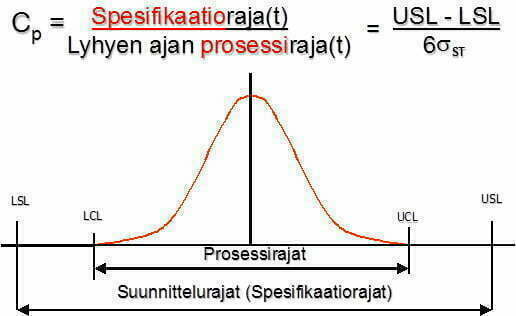
Sen jälkeen, kun prosessi on löydetty ja sen keskeiset inputit on tunnistettu ja prosessi on stabiili, voidaan prosessin suorituskyky määrittää. Prosessin suorituskyvyllä ilmaistaan, kuinka hyvin prosessi täyttää laadullisesti asetetut vaatimukset (luonteeltaan satunnainen vaihtelu, systeemi). Vaatimuksia (spesifikaatioita) ei välttämättä tarvita, mutta usein ne kuitenkin on jossain muodossa ilmaistu ja liittyvät tuotteen tai palvelun suoritusarvoon. On huomattava, että ohjausrajat (UCL, LCL) ja spesifikaatiorajat/toleranssirajat (USL, LSL) ovat eri asia. Ohjausrajat lasketaan tilastollisesti prosessin tuottamasta datasta ja spesifikaatiot asiakas/yritys määrittää suunnitteluvaiheessa ”mielivaltaisesti”.
Lean Six Sigmassa prosessin suorituskyvyn määritys on kekseistä ja liittyy mittaus-, analyysi- ja parannusvaiheisiin. Prosessin suorituskyky ilmaistaan erilaisin indeksein, joista yleisimpiä ovat Cp, Cpk -indeksit (Capability) ja Pp, Ppk-indeksit (Performance) Kuva 4.
Suorituskykymittareiden laskenta ja analysointi on kohtuullisen hankalaa ja suoritetaan usein ohjelmistolla (esim. Minitab), joka tulostaa graafin ja suuren määrän erilaisia indeksejä ja lukuja. Kuva 5.

Suorituskykyindeksillä ilmaistaan prosessin kykyä täyttää asiakasvaatimukset. Se on eräänlainen kapasiteettimittarin käänteisarvo, jolla mitataan prosessin laadullista kapasiteetin käyttöastetta. Six Sigmassa vaadittava Cp>2 eli laadullinen kapasiteetin käyttöaste saa olla korkeintaan 50 % (1/Cp *100%). Japanilaisilla laadullisen kapasiteetin käyttöaste on 20-30%.
Kun tehdään prosessin suorituskykytutkimusta, on datan keräykseen kiinnitettävä erityistä huomiota ja suunniteltava rationaalinen näytteenotto huolella:
- Aikaikkuna, josta data kerätään. Aikaikkunan on katettava niin lyhyenajan kuin pitkänajan vaihtelu ja prosessin on oltava stabiili. Prosessiteollisuudessa auto-korrelaatio (liian tiheä näytteenotto) johtaa virheellisiin tuloksiin. Datan on oltava stokastista toisistaan riippumatonta.
- Näytteenottomenetelmä. Data on valittava niin, että se edustaa prosessin suoritusarvoa. Tärkeää on määrittää sopiva näytteenkoko, taajuus ja alaryhmien koko. Kaikkea tätä nimitetään rationaaliseksi ryhmittelyksi.
- Tulosten esittäminen. Data on esitettävä oikealla tavalla niin, että jakauma tulee esille ja indeksit oikein ja luotettavasti määritettyä. Yleensä tarvitaan yli 300 datapistettä.
4. Mittaussysteemin suorituskyky (Measurement System Capability Studies)
Suoritettaessa prosessin suorituskykymääritystä on tärkeää, että mittaussysteemin virhe on mahdollisimman pieni. Mikä on pieni, mikä on suuri, tähän tarvitaan mittauksen virheen arviointia (evaluointia, MSA, EMP) ja tuloksen vertaamista eri datan käyttö- ja analysointitapoihin. Karkea peukalosääntö on, että mittauksen pitäisi olla 10x niin hyvä kuin pienin käytettävä desimaali. Jos mittaat jotain ±0,1 tarkkuudella niin mittaus pitäisi olla oikein ±0,01 tarkkuudella. Silloin voit luottaa 67,1 kun 67,11 tai 67,15 on oikein. Seuraavassa kuvassa 6 on esitetty mittauksilta vaadittavat minimi suorituskyvyt eri määritystavoilla:
Mittaussysteemin suorituskyvyn arvioinnissa voidaan havaita seuraavaa:
- Toistomittausten perusteella voidaan määrittää mittaussysteemin vaihtelun (virheen) suuruus.
- Voidaan tunnistaa ja eristää mittaussysteemin vaihtelun lähteet eli syyt. Siksi mittaussysteemin datankeräystapa onkin koesuunnittelua (DoE, full-matriisi) ja vaatii erityisen laskennan.
- Tulosten perusteella arvioidaan mittaussysteemin virhettä datan käyttötarkoitukseen.
Mittaussysteemin datankeräyssuunnitelma (rationaalinen näytteenotto) on mahdollista tehdä manuaalisesti, mutta helpommin ja luotettavammin suunnitelman luonti tapahtuu ohjelmalla (Minitab) ja samalla myös analyysi. Minitabin versiossa 16 on erillinen assistant -osio, joka ohjaa ja analysoi tulokset ja antaa analyysiraportit eri tilanteista. Kuva 7.

Karkeasti noin puolessa kaikista teollisuuden mittauksista on suuria ongelmia mittauksen suorituskyvyn kanssa. Välttämättä ongelma ei ole itse mittarissa vaan mittauksen suorituksessa. Seurauksena on virheellisiä prosessisäätöjä, turhia hyvien tuotteiden hylkäyksiä ja romutuksia ja virheellisten tuotteiden päätymistä asiakkaille. Kustannuksia ja taas kustannuksia!
5. Näytteenotto (Sampling)
Kun tavoitteena on ymmärtää prosessia ja sen käyttäytymistä, näytteenotto on kustannustehokas ja nopea tapa selvittää populaation, prosessin, tila. Mittauksissa rikkoutuville kappaleille näytteenotto on ainoa järkevä tapa selvittää asia. Keskeinen idea näytteenotossa on huolellinen suunnittelu, jotta saadaan riittävän tarkka estimaatti populaatiosta kohtuullisilla kustannuksilla. DMAIC-prosessissa näytteenottoa käytetään analyysivaiheessa nykytilan selvittämiseksi ja ohjausvaiheessa parannustoimenpiteiden testaamisessa.
Näytteenotossa on huomioitava viisi keskeistä seikkaa:
- Populaation kehysten määrittäminen. Tämä tarkoittaa tarkkaa populaation asettamista ja nimeämistä – mitkä tuotteet/palvelut kuuluvat populaatioon ja mitkä ei. Tuotannossa ongelma voidaan rajata yhteen koneeseen, tuotteeseen, prosessiin, koko tehtaaseen tai palveluketjuun.
- Edustava näyte. Näytteen edustavuudella voidaan tulokset yleistää koskemaan koko populaatiota. Edustavuus taataan yleensä mahdollistamalla jokaiselle yksikölle yhtäläinen mahdollisuus tulla näytteeseen. Näytteenoton apuna käytetään satunnaistaulukoita.
- Näyteyksikkö ja näytekoko. Näyteyksikössä voi olla joko yksi tai useampia yksiköitä ja näiden näyteyksiköiden määrä on määritettävä. Minitab tarjoaa lukuisia eri mahdollisuuksia näytemäärien laskentaan erilaisissa olosuhteissa.
- Lisäinformaation käyttömahdollisuus. Jos populaatiosta on tiedossa lisäinformaatiota, voidaan tätä käyttää tulosten ja estimaattien tarkkuuden lisäämiseen ja bias-efektien korjaamiseen, kuten esim. eduskuntavaalien ennustelaskennassa.
- Puuttuvien tietojen tai ei-vastetta käsittely. Joissain tilanteissa mittaus epäonnistuu tai mittausta ei voida suorittaa. Tällöin puuttuva data on korvattava tai uusittava riittävän tarkkuuden tai balanssisuuden saavuttamiseksi. Minitabissa puuttuva tieto voidaan korvata *-merkinnällä ja jos mahdollista, laskenta suoritetaan puuttuvalla datalla.
Näytteenotto voi koskea myös hyväksymis-/hylkäystarkastusta, jolloin voidaan suunnitteluparametrien avulla määrittää tarkastusnäytteen koko, hyväksyttävä määrä ja näihin liittyvät tilastolliset parametrit. Kuvassa Minitabin tuloste, jos AQL=0,65%, LTPD=4,5% ja populaatio 1000 (Kuva 8).
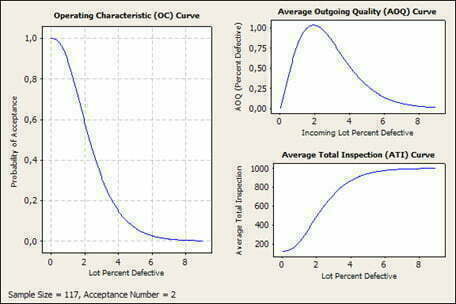
6. Koesuunnittelu (Design of Experiments,DoE)
Koesuunnittelu (DoE, Taguchi) on kaikkein tehokkain strateginen datankeräys, jolla voidaan selvittää JUURISYY, kausaliteetti. Menetelmän keskeisenä kehittäjänä oli Ronald Fisher 1930-luvulla.
Keskeinen etu käytettäessä koesuunnittelua on, että kokeilija ohjaa tutkittavien inputtien yhdistelmää, joka mahdollistaa koko muutosalueen tutkimisen ja samalla mahdollistaa kausaalin yhteyden luomisen inputtien ja ulostulojen välillä. Koesuunnittelu on täysin vastakkainen menetelmä havaintotutkimukselle, jossa tutkijalla ei ole suoraan inputtien ohjausmahdollisuutta.
Six Sigman DMAIC-prosessissa koesuunnittelu (DoE) on tärkein menetelmä ja työkalu parannusvaiheessa. Itse asiassa DoE on parantamisen ydin, joka tunnetaan myös Demingin ympyränä (Deming cycle, PDCA, PDSA). Sama ympyrä on myös Leanin keskeisin työkalu. Mikään Lean-työkalu – VSM, kanban, 5S, imuohjaus jne. – ei ”pomminvarmasti” paranna toimintaa, vähennä vaihtelua, vaan parannus on testattava.
Keskeiset periaatteet, johon koesuunnittelu perustuu ovat:
- Hyvin määritelty tavoite (Well-defined objective): Kokeen tavoite on oltava selkeästi määritelty. Mieluiten suunnitellun toimenpiteen asetuksena (statement) tulokseen.
- Perättäinen lähestymistapa (Sequential approach): Kokeet pitäisi suorittaa perättäin, jossa tieto kasvaa edellisessä kokeessa, jonka perusteella suunnitellaan seuraava koe ja seuraava.
- Vaihtelun jakaminen (Partitioning variation): Kokeen pitäisi mahdollistaa vasteen (ulostulon) vaihtelun jakaminen selkeästi komponentteihin, jotka ovat aiheuttaneet 1. tekijät, 2. taustamuuttujat ja 2. häiriömuuttujat.
- Luottamuksen aste (Degree of belief): Johtopäätösten tekeminen kokeesta pitäisi tapahtua riittävällä luottamuksen asteella. Tutkimus pitäisi suorittaa laajalla olosuhteiden alueella, jotta luottamuksen aste lisääntyy tuloksia sovellettaessa tulevaisuuteen.
- Suorituksen yksinkertaisuus (Simplicity of execution): Suunnitelman pitäisi olla niin yksinkertainen kuin mahdollista kuitenkin tyydyttäen edellä olevat neljä kohtaa.
R. A. Fisher kuvasi neljä työkalua, jotka auttavat varmistamaan, että kokeessa seurataan näitä periaatteita. Kuva 9.
- Koekuvio, matriisi (Experimental pattern): Tekijöiden tasojen järjestys ja suunnitelman koeyksikkö. Ortogonaalimatriisi tai vastaava.
- Suunniteltu ryhmittely (Planned groupping): koeyksiköiden blokkaus
- Satunnaistaminen (Randomization): tietyn tekijäyhdistelmän ja tasojen objektiivinen määrittäminen tietylle testiyksikölle.
- Toisto (replication): kokeiden, koeyksiköiden, mittausten, käsittelyjen ja muiden komponenttien toisto osana suunniteltua koetta.
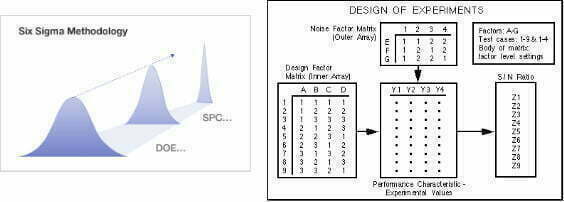
Koesuunnittelua olen käsitellyt artikkelissa ”Muutanko yhtä tekijää vai useita tekijöitä – OFAT vai DoE” /4/ ja kirjoissani /5, 6/.
Koesuunnittelu ja sen osaaminen on aivan oleellista laadun – parantamisen ja kehittämisen – ammattilaisille. Se mahdollistaa ohjatun input -tekijöiden ja output -tekijöiden yhteyden tutkimisen. Avainkysymykset, joilla päätät, millainen koe olisi suoritettava, ovat
- Onko koe suunnattu haravointiin (screening), karakterisointiin, mallintamiseen DoE vai parannuksen vahvistamiseen OFAT?
- Mitä input -tekijöitä kokeeseen on otettava?
- Mikä on input -tekijöiden tasomuutos, joka on mahdollista tehdä ja joka kiinnostaa (vaihteluväli, range)?
- Mikä matriisi, koesuunnitelma valitaan?
- Minkä kokoinen koesuunnitelma valitaan, jotta koekustannukset ja tulosten tarkkuus ja luotettavuus voidaan tasapainottaa?
7. Täydentävä data ja informaatio (Complementary Data and Information)
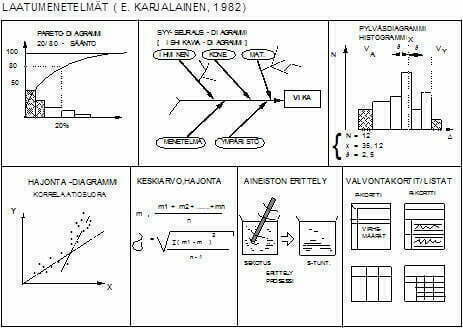
Parannuksessa tarvitaan hyvin usein täydentävää kvalitatiivista dataa ja informaatiota, jotka liittyvät tutkittavaan prosessiin tai tuotteeseen. Erilaisia laatutyökaluja, joilla kvalitatiivinen data muutetaan informaatioksi on suuret määrät. Kaoru Ishikawa on kuitenkin todennut, että 85% tarvittavasta datasta voidaan luoda ja esittää 7:llä laadun perustyökalulla. Kuvassa 10 on vuonna 1982 luomani kuva näistä työkaluista ja niiden käytöstä.
Yhteenveto: Tarkasteltaessa yritystä systeeminä huomaamme, kuinka tärkeää on vähentää vaihtelun osuutta prosessissa. Tehdään se sitten Lean tai Six Sigma -menetelmillä tai vielä paremmin yhdistämällä molemmat menetelmät Lean Six Sigmaksi.
Leanin ja Six Sigman yhdistämiseksi tarvitsemme dynaamisen yritysmallin ja kaksi jonoteorian keskeistä kaavaa – Littlen lain ja Kingmanin kaavan. Antti Piirainen on käsitellyt lakeja artikkelissa ”Onko kaikki erilaista vai ei”/7/.
Muutama kommentti näistä laeista ja niiden käytöstä.
Littlen lain (1) mukaan läpimeno on
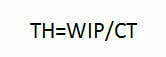
Tämän hyvin yleisen ja kaikkialla pätevän lain mukaan tehollista kapasiteettia, läpimenoa (TH=throughput), voidaan lisätä vain kahdella tavalla. Lisäämällä keskeneräistä työtä (WIP=work in process) tai lyhentämällä läpimenoaikaa (CT=cycle time) tai mieluimmin molempia samanaikaisesti ja oikeasuuntaisesti. WIP:n lisääminen kuitenkin indikoi virtausongelman olemassaolosta, joka olisi ratkaistava. Muita mahdollisuuksia ei ole. Kun teet parannustoimenpiteitä, näihin tekijöihin tai molempiin on vaikutettava. Littlen laki on keskiarvon laki.
Maailmassa kuitenkin kaikki vaihtelee. Tarvitsemme malliin dynaamisen vaikutuksen, vaihtelun, jonka antaa Kingmanin laki (2), joka kuvaa jonon muodostumisen teorian eli odotusajan.
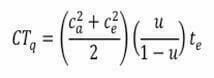
Odotusaika CTq muodostuu kolmesta tekijästä. Vaihtelusta, kapasiteetin käyttöasteesta ja prosessointiajasta. Kun vaihtelu (hajonta/keskiarvo) kasvaa c, odotus-/läpimenoaika CT kasvaa neliöllisenä. Kun kapasiteetin käyttöaste u kasvaa, odotus-/läpimenoaika kasvaa lähes neliöllisenä. 50 % kapasiteetin käyttöaste vaikuttaa läpimenoon 0,5/(1-0,5)= 1. Kun kapasiteetin käyttöaste on 70 %, läpimeno kasvaa 2,3 kertaiseksi ja kun kapasiteetin käyttöaste on 95 %, läpimenoaika on jo 19 kertainen. Tämänhän näemme liikenteen ruuhkana ja pitkinä autojonoina!
Johtopäätökset, jotka on tiivistetty oivallisesti artikkelissa/8, 9/:
- Jos vaihtelua ei ole, ei ole jonotusaikaa ja maksimi kapasiteetti voidaan saavuttaa (100 % käyttöaste). Nolla-virhettä (so. Six Sigma laatutasoa) kannattaa tavoitella
- Vaihtelua pienentämällä voidaan pienentää odotusaikaa (joka normaalisti on 99% läpimenoajasta) ja lyhentää läpimenoaikaa, joka lisää läpimenoa, tuottavuutta (Kingmanin kaavan ensimmäinen termi). Tämä on syy, miksi vaihtelun pienentäminen on keskeinen avaintekijä uusissa tuotanto-systeemeissä (lean) ja parannusstrategioissa kuten jatkuva parantaminen (continuous improvement), Lean Kaizen ja Six Sigma.
- Lisäämällä käyttöastetta lisäämme dramaattisesti läpimenoaikaa jopa 20 kertaiseksi. Jo kohtuullinenkin käyttöasteen lisääminen lisää läpimenoaikaa ja Littlen lain mukaan romahduttaa läpimenon. Valitettavan usein tätä ei tiedetä ja tunneta ”säästö ja kustannus” -projekteissa leikattaessa henkilöstöä kapasiteetin käyttöasteen nostamisessa ja joudutaan tuhon kierteeseen. Säästö ja tuottavuusprojektista tuleekin tappiokierre!
- 100 % käyttöaste tarkoittaa systeemin romahtamista. Useat ovat varmaan kokeneet tämän liikenteessä ruuhkassa tai tietokoneen kovalevyn täyttyessä ja fragmentoituessa. Kaikilla systeemeillä on rajansa. Myös ihmisellä. Sydämen lyöntitaajuus on n. 220-ikä. Kun tämä raja lähestyy ja sen ylittää, on seurauksena ”collaps”, dead!
- Tavoiteltaessa käyttöasteen maksimointia lisätään aina kustannuksia, vähennetään tehokkuutta ja tavallisesti päädytään systeemin romahtamiseen. Hyvä sääntö on, että älä ylitä määrän ja laadun 50 % kapasiteetin käyttöastetta. Lisää tarvittaessa kapasiteettia.
Parannettaessa toimintaa, on tasapainotettava ja optimoitava läpimeno, läpimenoaika, keskeneräinen tuotanto, kapasiteetti ja kapasiteetin käyttöaste ja näihin vaikuttava vaihtelu. Vaihtelu on tasapainon toisella puolella ja lisääntyvät hukat (waste) toisella puolella. Kun vaihtelu lisääntyy, niin
- Läpimenoaika/odotusaika lisääntyy
- On käytettävä alempaa kapasiteetin käyttöastetta (tehollinen WIP )
- Läpimeno (ulostulo aikayksikössä) alenee
Vaihtelua esiintyy kaikissa prosesseissa, josta maksetaan kova hinta nykyisissä johtamisjärjestelmissä. Rationaalisen johtajan on päätettävä, minkä hinnan se haluaa vaihtelusta maksaa tuottavuuden menetyksenä.
Erilaisia uusia keinoja on kehitetty vaihtelun pienentämiseksi kuten kysynnän tasapainottaminen, linja-balansointi, yhden kappaleen virtaus, Kanban, JOT, vakio WIP-tuotanto jne.
Keskeinen vaihtelun pienentämisen strategia, jolla on tilastollisesti ja tieteellisesti todistettu vaikutus on kuitenkin Lean Six Sigma, johon on yhdistetty niin Lean Kaizenin kuin faktajohtamisen parhaat elementit.
Lähteet:
1. Antti Piirainen: ”Kuinka lähestyä tiedon – datan – keräämistä?” Artikkelit 2008
2. Christine M. Anderson-Cook, Connie M. Borror: ”Paving The Way – Seven data collection strategies to enhance your quality analyses”, Quality Progress, April 2013.
Artikkelissa on erinomainen referenssiluettelo 56 referenssiä.
3. Eero E. Karjalainen: ”Kuinka hallitsen tuotanto- ja palveluprosesseja – Ohjaanko toleranssirajoilla vai SPC-rajoilla” Artikkelit 2013
4. Eero E. Karjalainen: ”Muutanko yhtä tekijää vai useita tekijöitä – OFAT vai DoE –” Artikkeli 2013
5. Eero E. Karjalainen: ”Tuotteen ja prosessin optimointi Taguchi- menetelmällä” 1989
6. Eero E. Karjalainen: ”Teollinen koesuunnittelu – Esimerkkejä Suomessa toteutetusta kokeellisesta tuotteen ja prosessin suunnittelusta Taguchi-menetelmällä” 1992
7. Antti Piirainen: ”Onko kaikki erilaista vai ei” Artikkeli 2013
8. Robert M. Grest: ”Full House – Understanding and expanding capasity in healthcare”: Six sigma Forum Magazine, May 2013
9. Niklas Modig, Pär Åhlström: ”Tätä on Lean – Ratkaisu tehokkuusparadoksiin”, 2013
10. Taguchi, Chowdhury, Wu: ”Taguchi’s Quality Engineering Handbook”, 2005

Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.