
Laatu 4.0, tekoäly (AI) ja koneoppiminen (ML), mullistavat kaiken. Laatuteknologia on uusien haasteiden ja muutosten edessä. Miksi? Tuotteiden ja palveluiden rakenteet ja komponenttien määrät ovat monimutkaistuneet ja kasvaneet räjähdysmäisesti viimeisten vuosikymmenien aikana, tuotantoteknologiat ovat muuttuneet yhä automaattisimmiksi ja datavaltaisiksi. ”Vanhan” laatuteknologian suorituskyky ei enää riitä. Asiakkaat vaativat yhä parempaa laatua ja nopeampia toimitusketjuja.
Uusi tekoälyyn ja koneoppimiseen perustuva Oppiva Laadunohjaus (LQC) tuo nopean ja tehokkaan ennustavan laadun ohjauksen nykyisen tilastollisen ohjauksen rinnalle tai jopa korvaa sen. (Machine Learning + Quality Control = Learning Quality Control, LQC)/1/
On aika tarkastella tuotanto- ja palveluprosessien (loppu)tarkastusta ja reklamaatioita (asiakasvalituksia, takuukustannuksia jne.). Reklamaatiot ovat yritykselle kuin Venäjä Suomelle. Kolme sanaa kuvaa yrityksen laatuorganisaatiota ja sen tarkoitusta ja olemassaoloa: reklamaatio, reklamaatio, reklamaatio. Yrityksen ja sitä avustavan laatuorganisaation visio ja päämäärä on oltava 0 reklamaatiota. Kaikki asiakkaalle toimitettavat tuotteet ja palvelut on oltava virhe- ja vikavapaita! Tämä aika ei kestä virheitä ja vikoja!
Laaduttomuuden so. reklamaatioiden, takuiden ja asiakasvalitusten lisääntyvä läpinäkyvyys haastaa ”vanhaa” laatutekniikkaa. Läpinäkyvyyttä lisää internet, hakukoneet, tekoäly ja agentit, jotka löytävät yrityksen kuin yrityksen tuote- ja palvelureklamaatiot ja laatuarviot. Yritykset eivät voi ”vanhaan tapaan” piilotella huonoa laatua sisäisiin ja salattuihin reklamaatiotilastoihin.
On ainakin epäeettistä pitää yrityksen visiona ja päämääränä huonoja asiakaskokemuksia ja viallisia tuotteita ja palveluita. Näin on käynyt lukuisille yrityksille. Pyyhe on heitetty laadun osalta kehään! Käytännön ”visioksi” on tullut virheet ja asiakasvalitukset ja mandraksi sisäisen hukan vähentäminen! Asiakas ansaitsee yritykseltä Nollavirhe-vision ja päämäärän, jota kohti se pyrkii kaikin keinoin.
Oppiva Laadunohjaus (LQC) antaa uudet tehokkaat menetelmät prosessin virheiden ja vikojen luokitteluun ja paljastamiseen ennen niiden ajautumista tarkastuksen läpi asiakkaille reklamaatio-, takuu- ja asiakasvalitusprosessiin. LQC:ssa siirrytään reaktiivisesta ohjauksesta proaktiiviseen ohjaukseen, joka tarkoittaa ennustamista (predict) ja ennaltaehkäisyä (prevention) jälkikäteisen ohjauksen ja korjauksen sijaan.
Oppiva laadunohjaus (LQC) on osa Laatu 4.0, joka muodostaa uuden lähestymistavan. Laatu 4.0 yhdistää neljännen teollisen vallankumouksen (Industry 4.0) teknologiat, valmistuksen Big Datan (MBD, Manufacturing Big Data), teollisen esineiden internetin (IIoT, Industrial Internet of Things), pilvitallennuksen ja -laskennan (CSC, Cloud Storage and Computing) ja tekoälyn (AI, Artifical Intelligency) perinteisiin laadunhallintakäytäntöihin. Uudet tuotteet ja valmistustavat ovat luoneet uusia ongelmia, joita perinteisillä laaduntarkastuksen ja ohjauksen menetelmin ei voida ratkaista.
Uusi laadunohjauksen ratkaisu, LQC, käyttää valmistus- ja palveluprosessista saatavaa havaintodataa, josta koneoppimisen algoritmi oppii ja ennustaa – luokittelee – tuotteen ja palvelun hyväksi tai vialliseksi. Uusi ratkaisu on suorituskyvyltään heikon (loppu)tarkastuksen tukena tai korvaa sen. Tavoitteena on NOLLA reklamaatiota, asiakasvalitusta ja takuuta. Luokittelu perustuu binäärisiin koneoppimisen algoritmeihin, joilla palvelu- ja valmistusprosessin virheet voidaan ennustaa ja havaita ennen tarkastusta ja/tai reklamaatiota/asiakasvalitusta.
Ensimmäinen onnistunut raportoitu LQC-projekti oli GM Chevrolet Volt -akkujen kehityksessä käyttöön otettu konsepti vuodelta 2016./2/ Yksikin vika akkupaketin sadoissa liitoksissa pysäyttää auton. Kun tämä innovaatio tuli julki, tieteellisten Laatu 4.0 (Quality 4.0) artikkelien määrän kasvuprosentti on ollut valtava verrattuna Six Sigman kasvuprosenttiin (kuva 1), joka sekin on vielä merkittävä.
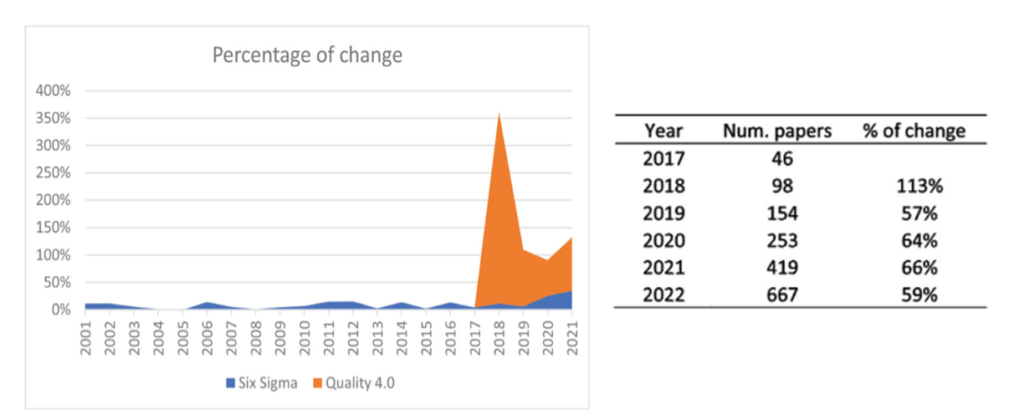
Seuraavassa esittelen uuden LQC laatutekniikan perusteita ja käytännön tuloksia.
Sisältö:
- Johdanto
- Laatuteknologian ja ongelmanratkaisun kehitys
- Six Sigmaa täydentävä Laatu 4.0
- Luokittelumalli (LQC) prosessin ohjaukseen
4.1. Perinteinen laadun tarkastus ja luokittelu ja sen ongelmia
4.2. Laatu 4.0 -aloite – Laadun binäärinen luokittelu koneoppisella (LQC)
4.3. LQC-mallin luomisesta
4.4. LQC-koneoppimismallin laskennasta
4.5. Satunnainen metsä (Random Forests) - Case Chevrolet Volta – uuden laatuteknologian (MQC≈LQC) synty
- Yhteenveto
1. Johdanto
Laatu 4.0 (Quality 4.0) on ASQ:n hanke (Amerikan laatuyhdistys), joka käynnistyi vuonna 2019./4/ Laatu 4.0 on termi, joka viittaa laadun ja organisaation huippuosaamisen tulevaisuuteen Teollisuus 4.0:n tarpeiden ja suorituskykyodotusten kontekstissa. Laadun ammattilaiset ovat keskeisessä roolissa johtaessaan organisaatioitaan soveltamaan todistettuja laatuperiaatteita uusiin, digitaalisiin ja mullistaviin teknologioihin. (https://asq.org/quality-resources/quality-4-0 ). Tri Carlos Escobar/3/ täydentää määritelmää: ”Laatu 4.0 perustuu uuteen paradigmaan, joka mahdollistaa älykkäät päätökset empiirisen oppimisen, empiirisen tiedon löytämisen ja reaaliaikaisen tiedon tuottamisen, keräämisen ja analysoinnin avulla”.
Laatu 4.0 hyödyntää teollisuuden Big Dataa, teollista esineiden internetiä, pilvitallennusta ja -laskentaa sekä tekoälyä ratkaistakseen kokonaan uudenlaisia monimutkaisia teknisiä ongelmia. Uusi ongelmajoukko viittaa tilastollisen prosessinohjauksen (SPC/SQC) ratkaisemattomiin teknisiin ongelmiin./5/ Prosessi- ja lopputarkastus vaatii onnistuakseen hyvän ymmärryksen prosessista, havaittavat relevantit laatuominaisuudet (feature) ja niihin liittyvät laatukriteerit ja strategiat ja prosessin kriteerien havaitsemiseksi prosessista.
Jos tuote on yksinkertainen sorvattava akseli, prosessi on sorvaus, laatuominaisuus on akselin halkaisija, kriteeri on prosessissa SPC-ohjausrajat (UCL, LCL) ja tarkastuksessa tuotetoleranssit (LSL, USL) ja kriteerien havaitsemiseksi ohjauskortit ja/tai laatutaulu prosessille ja kyvykäs mittaus/mittakone/lopputarkastusasema, joka on kyvykäs erottelemaan/luokittelemaan hyvät huonoista. Kaikki neljä keskeistä ehtoa täyttyy sorvatussa kappaleessa, jos mittauksen kriittinen tarkkuus ja toistettavuus täyttää ehdot. (Katso MSA Gage R&R, artikkeli: Mihin tietoon voi luottaa?).
Jos tuote tai palvelu sisältää paljon osia ja vaiheita ja on monimutkainen, niin prosessi on yleensä myös monimutkainen. Tuotteessa ja palveluissa on lukuisia mittoja ja ominaisuuksia, joita kaikkia ei voi suoraan mitata, jolloin tarkastuskriteerejä ei voida enää toteuttaa riittävällä tarkkuudella ja luotettavuudella. Esim. jos mitattavia kohteita on 10 ja yhden mitan/mittauksen luotettavuus/oikeellisuus on 95 % (virhe 5 %), silloin 10 rinnakkaisen mittauksen kokonaisluotettavuus/oikeellisuus on 0,9510= 0,6 (60 %) ja virheellisyys 1-0,6 = 0, 4 (40 %). Mittaus/luokittelu on vain 60 %:sti oikei! Useat yritykset ovat menneet tämän SPC/SQC rajan läpi huomaamatta, että tarkastuskonseptia ei voi enää käyttää luotettavasti. Tällöin visuaalinen ja/tai manuaalisten ohjausjärjestelmä on korvattava koneoppimis- (ML) tai syväoppimis- (DL) algoritmeilla (LQC).
Chevrolet Volt -akkupaketin liitokseen tekemisessä ultraäänihitsausprosessi oli selkeä, mutta teknisesti tuntematon, keskeiset laatuominaisuudet olivat tunnetut (lujuus ja johtavuus), mutta ei mitattavissa ilman rikkovaa testiä. Tunnistettuja muuttujia, jotka voisivat vaikuttaa/muuttaa lujuutta ja johtavuutta, oli paljon 53 kpl, joille ei ollut kriteeriä eikä selkeää tapaa havaita. Yhteyttä vikaantumiseen ei voitu tunnistaa jne. LQC:llä luotu empiirinen koneoppimismalli ratkaisi ongelman.
2. Laatuteknologian ja ongelmanratkaisun kehitys
Laatuteknologian/-filosofian kehityskulun ymmärtäminen on laadun tekemisessä tärkeää. Miksi? Laatuteknologian kehitykselle tunnusomaista on, että vanha hyväksi havaittu toiminta ei korvaudu, vaan täydentyy uudella laatuteknologialla. Uusi teknologia ”korjaa, täydentää” aikaisemmassa teknologiassa olevia puutteita. Usein puutteet ovat syntyneet, kun valmistusympäristö ja valmistustavat ovat muuttuneet. Laatuteknologiaa käytettäessä on käytettävä vanhoja hyväksi todistettuja menetelmiä ja uusia menetelmiä.
Laatuteknologian kehitys on siis ensi sijassa evoluutio kuin revoluutio, joka mieluimmin kehittyy ja täydentyy uusien tuotteiden ja tuotantoteknologioiden vaatimusten mukaan kuin hylkäisi entiset hyvät laatuteknologiat. Taulukossa 1 keskeiset muutokset ajattelutavassa ja ongelmanratkaisussa kautta aikain.
Taulukko 1. Laatufilosofia ja ongelmanratkaisu kautta aikain. /6/
| LAATUFILOSOFIA ja ONGELMANRATKAISU | ||||||
| a) TARKISTA | b) SPESIFIOI | c) SQC/SPC | d) TQM | e) Six Sigma | f) DFSS | g) Laatu 4.0 |
| 500-400 eaa-> | 1800-> | 1924-> | 1980-> | 1986-> | 2000-> | 2016-> |
| Tarkastus (Inspect) | Spesifiointi (Specification) | Ohjaus (Controlling) | Johtaminen (Managing) | Reagointi (Reactive) | Ennakoiva (Proactive) | Ennustava (Predective) |
| Tarkastus | Toleranssit (Tolerance) | Spesifiointi (Specification) | Suunnittelu (Plan) | Määrittely (Define) | Määrittely (Define) | Tunnista (Identify) |
| Tuotanto (Production) | Tekeminen (Do) | Mittaus (Measure) | Mittaus (Measure) | Aavistaa (Acsensorize) | ||
| Tarkastus (Inspection) | Tarkastus (Check) | Analysointi (Analyze) | Analysointi (Analyze) | Löytää (Discover) | ||
| Toiminta (Do) | Parannus (Improve) | Suunnittelu (Design) | Oppia (Learn) | |||
| Ohjaus (Control) | Optimointi (Optimize) | Ennustaa (Predict) | ||||
| Verifioi (Verify) | Uudelleen suunnitella (Redesign) | |||||
| Uudelleen oppia (Relearn) | ||||||
Laadun kehityspolkua seuratessa voidaan aloittaa jopa Vanhan testamentin ensimmäisestä kirjasta. Ensimmäisen Mooseksen kirjan 31. jae kuuluu: Ja Jumala katsoi kaikkea, mitä hän oli tehnyt, ja katso, se oli erittäin hyvää. Ja tuli ehtoo, ja tuli aamu, kuudes päivä.” (Biblia 1776, 1. Moos. 1:31). Tarkastus (≈katso) oli todellakin ainoa johtava laatumalli monien vuosisatojen ajan.
Tärkeä virstanpylväs on, kun osien spesifikaatiot asetetaan ennen lopullista kokoonpanoa. Tämä askel oli yhdysvaltalaisen keksijän, koneinsinöörin ja valmistajan Eli Whitneyn (1765–1825) ansiota. Whitney muistetaan puuvillakoneen keksijänä, joka kehitti keskenään vaihdettavien osien ja massatuotannon konseptin./10/ Syntyi sallitut toleranssit ja niiden suunnittelu konseptit. Tähän perustuu Philip Crosbyn laadun määritelmä ”Yhdenmukaisuus vaatimuksiin” (Conformance Specifications). Toleranssit olivat unohtuneet ja niiden vaatimusta ja noudattamista pidettiin kalliina 1970-luvulla. Nämä ajatukset on julkaistu kuuluisassa ”best seller” kirjassa ”Quality is Free: The Art of Making Quality Certain ” 1979. Kirja/7/ esittelee ajatuksen, että laatuun panostaminen ei lisää kustannuksia, vaan vähentää niitä poistamalla virheitä ja hukkaa. Teos toi tunnetuksi käsitteet Nollavirhe (Zero Defects) ja Tee se oikein ensimmäisellä kerralla (Do it right the first time). Kirja käännettiin Laatuyhdistyksen toimesta suomeksi nimellä ”Laatu on ilmaista” (1986)/8/. Kirja oli ensimmäisiä laatukirjoja, jonka silloin toimitin. Nyt nämä ajatukset yhdenmukaisuudesta ja Nolla virheestä ovat tulossa takaisin Quality 4.0 muodossa! Kirja ”Machine Learning in Manufacturing – Quality 4.0 and Zero Defects Vision” (2024).
Kolmas tärkeä kehitysvaihe on, kun tri Walter A. Shewhart kehitti vuonna 1926 kuuluisan laatuteorian (SQC/SPC) erotellessaan tilastollisesti satunnaissyyt ja erityissyyt – stabiilin ja ei-stabiilin prosessin – toisistaan. Hän ehdotti kolmivaiheista ongelmanratkaisustrategiaa (spesifikaatio, tuotanto, tarkastus), joka muodosti ympyrän aikaisemman perättäisen järjestyksen sijaan. Tähän perustuvat tieteelliset laatumenetelmät. Tieteelliselle menetelmälle oleellista on, että se on itse itsensä korjaava ympyrä tai jakso. Tämä ongelman ratkaisumenetelmä tunnetaan Shewhartin oppimis- ja parannussyklinä. Hän käänsi laadun huomion tuotteesta ja tarkastuksesta prosessiin ja jatkuvaan parantamiseen. Tällä oli ja on edelleen valtava vaikutus valmistavalle teollisuudelle ja tuottavuuden kehitykselle. SPC mahdollisti laadunohjausjärjestelmien muuttamisen reaktiivisesta tuotteiden spesifikaation/toleranssin mukaisuuden tarkastamisesta – tarkastusvetoisesta – proaktiiviseksi prosessin stabiilisuuden ei-stabiilisuuden havainnoimiseksi, jossa keskeistä on erityissyiden – mustien joutsenten – estäminen. Shewhart siis keksi, kuinka parantaa tuotteita – tunnistamalla ja poistamalla erityissyyt prosessista eli lisäämällä aikavakautta (stabiilisuutta) prosessissa.
TQM (Total Quality Management)-filosofia syntyi 1980-luvulla, kun tri W. Edwards Deming tarkensi ja laajensi Shewhartin ongelmanratkaisustrategiaa, joka tunnetaan myös Demingin laatuympyränä. Laatuympyrä muodostaa kokonaisvaltaisen ongelmanratkaisumenetelmän (suunnittele, tee, tarkista/tutki, toimi – PDCA tai PDSA). Deming siirsi laadun painopisteen työntekijöistä johtajiin ja yritti useilla demoilla (punaisen helmen koe, suppilokoe) vakuuttaa johtajat oikeaan parantamisen tapaan – erityissyyt, satunnaissyyt (The 14 Points for Management, The System of Profound Knowledge (SoPK), The Deming Cycle (PDSA)). Samanaikaisesti tri J. M. Juran kehitti kattavan johtamisjärjestelmän, jota kutsutaan termillä Juranin Trilogia (The Juran’s Trilogy). Trilogiaan kuuluu suunnittelu, parantaminen ja ohjaus yhteen kytkettynä.
Muutamaa vuotta myöhemmin, vuonna 1986, Bill Smith esitteli Motorolalla Six Sigman. Six Sigma on reaktiivinen lähestymistapa, joka perustuu viisivaiheiseen ongelmanratkaisustrategiaan (määrittele, mittaa, analysoi, paranna, ohjaa – DMAIC) ja jonka tarkoituksena parantaa satunnaistekijöiden suorituskykyä mallintamalla prosessi koesuunnittelulla (DoE). DMAIC-prosessi on laajennus PDSA:sta. Six Sigma laajennettuna Leanilla on siis kokeellinen mallinnustekniikka. Huomaa, että Shewhart ei vaatinut tehdä mitään satunnaissyille (ei osannut?!)! Hän kehitti SPC:n ennen DoE:n keksimistä (tri R. A. Fisher 1935). DoE:lla voidaan satunnaissyyt ”pilkkoa” vaikuttaviin kausaalitekijöihin.
Design for Six Sigma (DFSS) syntyi pian Six Sigman jälkeen täydennyksenä. Se on ennakoiva, proaktiivinen lähestymistapa, jonka tavoitteena on suunnitella robusteja tuotteita ja prosesseja siten, että vikoja ei koskaan synny. Suunnitteltu Nollavirhe-menetelmä! Se perustuu optimointitekniikoihin, joita yleensä sovelletaan kuusivaiheisen ongelmanratkaisustrategian kautta (määrittele, mittaa, analysoi, suunnittele, optimoi, verifioi – DMADOV).
Viimeisin laadun muutos on Laatu 4.0 aloite, joka sisältää uuden tekoälyyn ja koneoppimiseen liittyvän ongelmanratkaisustrategian tai menetelmän, Oppivan Laadun Ohjauksen, LQC (ML+ QC =LQC). LQC prosessi muodostuu 5 vaiheesta kuten Six Sigma, mutta eri sisällöllä – Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen – Identify, Observe, Data, Learn, Redesign (IODLR). Kuva 3.
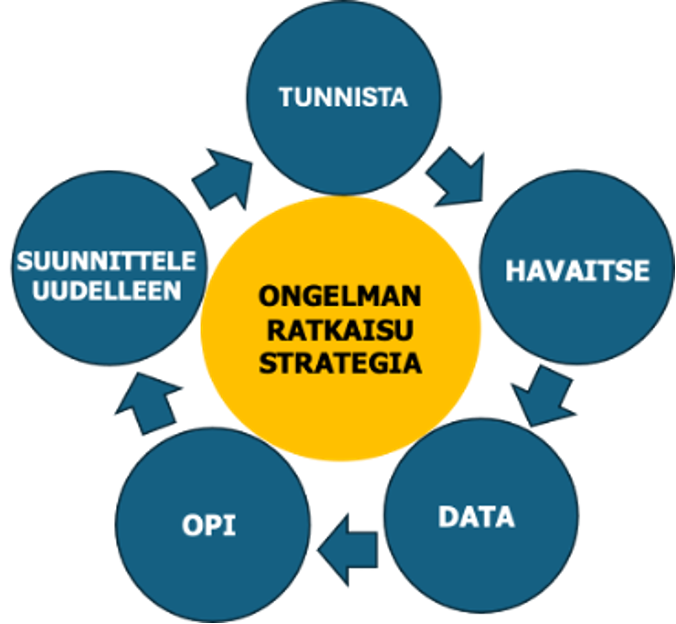
5-vaiheinen ongelmanratkaisustrategia edesauttaa järjestelmällisestä innovointia, prosessien hallintaa ja parantamista havaintointodatan avulla. Se auttaa tunnistamaan ja valitsemaan arvokkaita projekteja, jotka voidaan muotoilla koneoppimisongelmiksi, joilla on suuri onnistumisen todennäköisyys onnistua ja tuottaa voittoa. Tavoitteena Nolla virhettä (Zero Defect)/1/.
3. Six Sigmaa täydentävä Laatu 4.0
Laatu 4.0 on seuraava luonnollinen askel laadun kehityksessä Six Sigman ja DFSS:n jälkeen. Perinteiseen tilastotieteeseen ja tilastolliseen otantaan perustuva Six Sigma -paradigma ei ole suunniteltu tehokkaasti/vaikuttavasti vastaamaan Teollisuus 4.0 asettamiin haasteisiin. Miksi?
Tilastotiede (Lean) Six Sigma) tekee päätelmiä tilastollisesta otoksesta. Se keskittyy kokeellisen otantadatan (DoE, ortogonaalimatriisi) analysointiin ja yhteenvetoon oletusten mukaisesti, ja se soveltuu paremmin järjestelmiin, jotka ovat pienempiä, lineaarisia, toistettavien ja datamäärät ovat kohtuullisia ja data (≈prosessi) on stabiili.
Tekoäly ja koneoppimisalgoritmit tarjoavat laajemmat ja paremmat kyvykkyydet havaintodatan analysointiin. Ne oppivat automaattisesti ennustavia malleja suurista tietojoukoista ja muodostavat malleja monimutkaisista epälineaarisista tapahtumista, jotka yleensä esiintyvät hyperulotteisissa tiloissa. ML-algoritmeissa ei ole oletuksia tai ennalta määriteltyä mallia, kuten Six Sigmassa. Hyperulotteinen avaruus tarkoittaa useiden tekijöiden aiheuttamaa saman aikaista vaikutusta. Esimerkiksi vety ja happi ovat turvallisia kaasuja yksinään, mutta yhdessä liitettynä kipinään syntyy hyperulotteinen avaruus – räjähdys. Tässä on 3 ulottuvuutta! Ulottuvuuksia voi olla paljon enemmän. Perinteinen tarkastus löytää yleensä vain 1-uloitteiset viallisuudet, mutta ei ”osaa” erotella hyperulotteisia vikatiloja!
Taulukossa joitain keskeisiä eroja Six Sigman ja Laatu 4.0 välillä .
Taulukko 2. Six Sigman ja Laatu 4.0 ominaisuuksien vertailu /3/
| Ominaisuus | Six Sigma | Laatu 4.0 |
| Vertailevat näkökulmat | Tilastotekniikkaan perustuva | Koneoppimiseen perustuva |
| Data | Koedata | Havaintoihin perustuva data |
| Ominaisuusavaruus | Pienestä keksinkertaiseen | Iso (hyber mittakaavainen) |
| Oppiminen | Hypoteesiperusteinen | Keksimiseen perustuva |
| Malli | Selittävä | Ennustava |
| Oletukset | Teoreettinen jakaumamalli | Ei mallia |
| Validisuus | Tilastollinen merkitsevyys (p-arvo) | Yleistäminen |
| Toteutus | Reaaliaikainen ja asynkroninen | Reaaliaikainen |
| Datan nuuskinta | Ei sallittu | Kyllä (iteratiivinen malli) |
| Ratkaisu | Pitkäaikainen kokeellisesti johdettu | Lyhytaikainen havaintoihin perustuva |
| Uudelleenoppiminen | Ei | Kyllä (adaptiivinen mallinnus) |
| Datan osittaminen | Ei (kaikki data käytetään) | Kyllä (koulutus, validointi, testaus |
Laatu 4.0 tehostaa laatua teknologisesta näkökulmasta, mutta on tärkeää ymmärtää yksi sen tärkeimmistä rajoituksista: koska useimmat koneoppimissovellukset kehitetään havaintodatan perusteella, kausaalista yhteyttä ei voida todistaa. Koneoppimismalli on ensi sijassa korrelaatiomalli. Koneoppimismallit eivät siis korvaa Six Sigman tilastollista pohjaa ja kausaalista selityskykyä. Koneoppimismallista et yleensä pysty päättelemään juurisyytä. Ne eivät siis sovellu ennaltaehkäisevään parannukseen, mutta voivat antaa vihjeitä Six Sigmalle juurisyiden selvittämiseksi. Six Sigma ja sen luomat tilastolliset mallit ja niiden antamat ennusteet ovat edelleen mitä tärkeimpiä ennaltaehkäiseviä parannusmenetelmiä. Näillä voidaan muuttaa ja optimoida prosessia paremmaksi.
Yleisesti Six Sigmaa ja sen ongelmanratkaisukehystä käytetään niissä tilanteissa, joissa voidaan turvautua tilastolliseen mallinnukseen – tulevaisuuden tuloksen optimointiin ja ennustamiseen (prediction). Laatu 4.0 ongelmanratkaisua käytetään ei-tilastollisesti sopivaan havaintodataan ja tuloksen ennustamiseen (predict).
4. Luokittelumalli (LQC) prosessin ohjaukseen
Laatu 4.0:n pääasialliset tutkimus- ja soveltamisalueet ovat:
- Harvinaisten laatutapahtumien havaitseminen esim. asiakasreklamaatioiden estäminen
- Laatuongelmien ennustaminen (predict)
- Visuaalisten ja manuaalisten tarkastusten täydentäminen ja/tai poistaminen
- Ihmisen älykkyyden parantaminen hypertiloissa esimerkiksi sairauksien – syöpien, sydän infarktien – esiasteiden tunnistaminen (katso osa 1), hoivatarveluokitukset jne.
- Päätöksenteon nopeuden ja laadun lisääminen (luokittelupäätökset)
- Läpinäkyvyyden, jäljitettävyyden ja auditoitavuuden parantaminen
Six Sigmalla on saatu merkittäviä tuloksia useissa edellä mainituissa kohteissa, mutta ei kaikissa. Six Sigma ei ole paljoakaan vaikuttanut suoraan prosessiin, prosessin lopputarkastukseen ja reklamaatioihin toisin kuin esimerkiksi SPC/SQC. Six Sigmalla on parannettu prosessien suorituskykyä ja yritysten tulosta. Jokapäiväinen tehdas- ja palveluprosessin laatutyö on Six Sigmalle vieras alue. Laatu 4.0 -aloite (binäärinen luokittelu) on kehitetty ”suoraan” ja välittömään laatutyöhön.
4.1. Perinteinen laadun tarkastus ja luokittelu ja sen ongelmia
Useimmat prosessit tuottavat edelleen 0,1-30 % tai jopa enemmän viallisia tuotteita ja palveluja, joista osa ”valuu” asiakaspintaan ja aiheuttaa jatkuvia reklamaatioita, asiakasvalituksia ja takuukustannuksia. Yritykset ovat pyrkineet ”suitsimaan” näitä virheitä prosessiohjauksella käyttämällä SPC:tä (ohjauskortteja, laatutaulua) erityissyiden poistamiseen prosessista ja tuotteiden lopputarkastusta luokittelemaan tuotteet hyviin ja viallisiin (≈laadun binäärinen luokittelu).
Binäärisen luokittelun ongelma lopputarkastuksessa on, että tarkastuksen resoluutio, erottelu, ei riitä. Tämä on yksi keskeisistä syistä, miksi prosessien ja komponenttien suorituskykyä pyritään kasvattamaan. Artikkelissani Laatu 4.0 ja Lean Six Sigma 2.0 taulukossa1/9/ on esitetty yhteys tuotteen monimutkaisuus ja prosessin kyvykkyyden (sigmataso) ja onnistumisen välillä. Tämä on tullut esille sadoissa BB- ja GB Six Sigma -projekteissa. Jo 10 – 40 komponentin/osakokoonpanon kohdalla ollaan rajassa, jossa ”reklamaatio”vuoto on vääjäämätön nykyisillä sigmatasoilla (2 -3 s) /10/. 10 virhemahdollisuuden kohdalla vaaditaan erottelua, joka on alle 0,1 % (<1/210x100 %)! Ei onnistu!
Jokainen voi tarkistaa yrityksen lopputarkastuksen ”vuodon” ryhmittelemällä lopputarkastuksen virhedatan (=prosessivirheet) ja vastaavan ajankohdan reklamaatiot (=vikataajuus) korrelaatiosuoraksi (kuva 3a). Olen kirjassamme/10/ selittänyt tekniikan s. 159. Käytännössä, jos pisteet eivät noudata korrelaatiosuoraa, lopputarkastus ei mitenkään toimi/vaikuta (kuva 3 b, yritysesimerkki). Käyrän kulmakertoimesta nähdään, mikä % -osuus tarkastuksen virheistä menee läpi. Mitä jyrkempi suora, sitä enemmän tarkastus vuotaa!
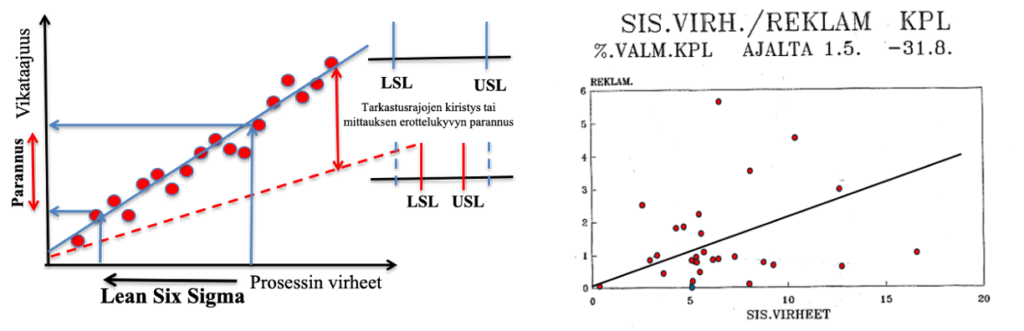
Kuva 3a): Asiakasvikataajuuden ja prosessi/tarkastustaajuuden välinen suhde (korrelaatio) kertoo, mikä osuus prosessivirheistä ”valuu” asiakasreklamaatioksi. Asiakaslaatua voidaan ”parantaa” kiristämällä tarkastuksen/toleranssien rajoja (katkoviiva) ja/tai vähentämällä prosessin virheitä paljastamalla ja poistamalla erityissyyt ja kasvattamalla komponenttien suorituskykyä Lean Six Sigmalla.
Kuva 3b): Erään yrityksen kahden vuoden sisäiset virheet ja reklamaatiot. Kuvasta nähdään, että reklamaatioiden ja sisäisten virheiden välillä ei ole yhteyttä (korrelaatiota) eikä tarkastuksen luokittelu/resoluutio toimi/vaikuta. Jotain on vialla tarkastuksen säännöissä. Tätä tarkastusta ei korjattu (liian kallis ja liian monta mittauskohtaa! Kallis mittakone), vaan täydennettiin laatutauluilla, jotka ”poistivat” sisäisiä virheitä ja suorituskyvyn parantamisella (Six Sigma). Katso lähteet /11,12/ artikkeli: Laatutaulu – Osa 3: kehitysvaiheet III-VI – teoriasta käytäntöön kuva 20 ja artikkeli: Laatutaulu – Osa 5: Poikkeamatietojen analysointi kuva 18 + Case ”Eimo”.
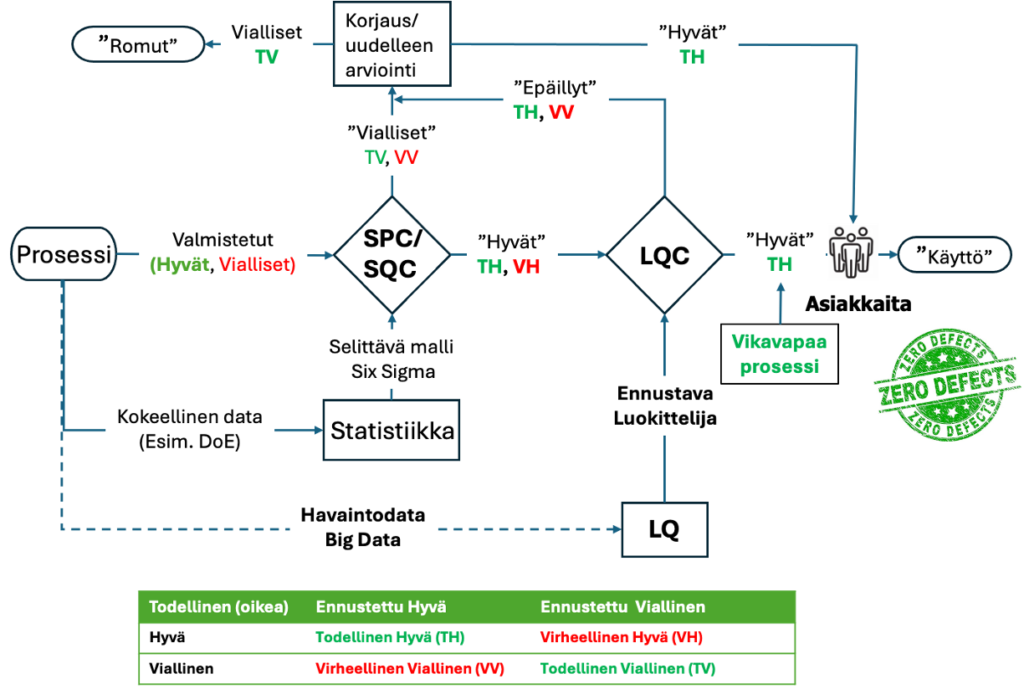
Kuvassa 4 on esitetty kaaviokuvana edellä kuvattu tarkastusjärjestys (3a ja b), joka vuotaa niin asiakaslaadun kuin romutettujen suhteen. /1,3/
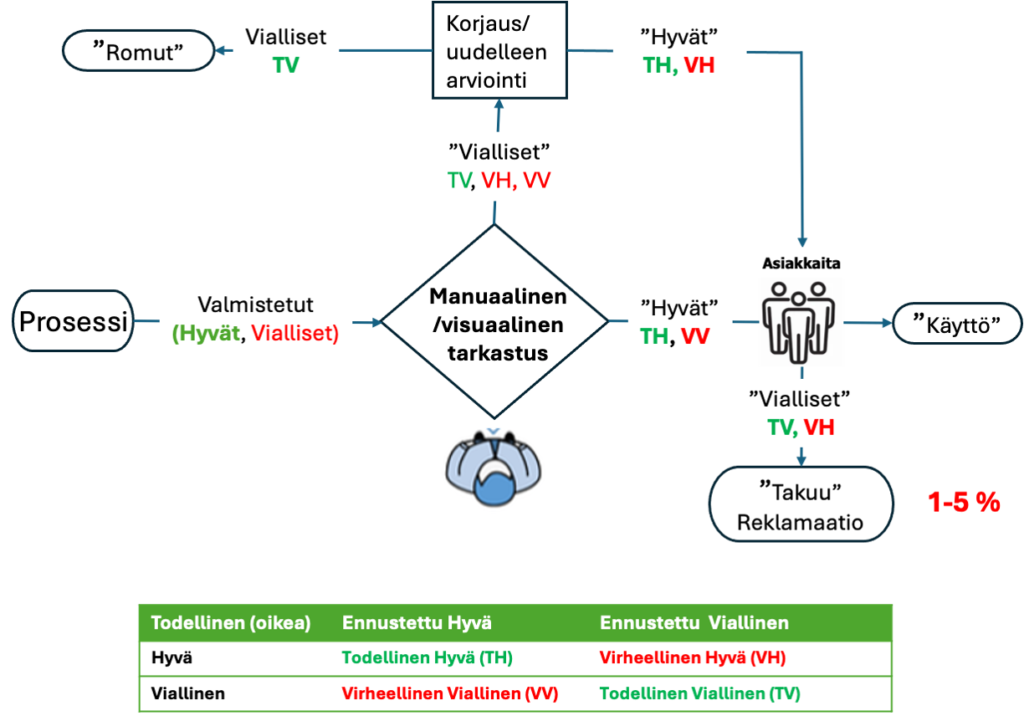
Kuvassa 4 klassinen laaduntarkastus (luokittelu) ja ohjaus, joka läpäisee virheellisiä ja viallisia tuotteita ja palveluja asiakkaille. Näistä muodostuu reklamaatioita, asiakasvalituksia ja kustannuksia. Tarkastus synnyttää myös ”piilotehtaan”. Tarkistus myös ohjaa hyviä turhaan korjattavaksi. Monilla organisaatioilla on todellisia laatuun liittyviä kustannuksia jopa 15–20 % myyntituloista, joillakin jopa 40 % kokonaistoiminnasta. Yleisenä nyrkkisääntönä voidaan pitää, että huonon laadun kustannukset menestyvässä yrityksessä ovat noin 10–15 % toiminnasta. Tehokkaat laadunparannusohjelmat voivat vähentää tätä merkittävästi ja siten vaikuttaa suoraan voittoihin (https://asq.org/quality-resources/cost-of-quality#COPQ )
Klassinen laatutarkastuksen ja ohjauksen prosessikuvaus (kuva 4) perustuu manuaaliseen ja visuaaliseen lopputarkastukseen ja tarkastukseen liittyvään korjaus- ja hylkäysprosessiin. Vialliset tuotteet vuotavat asiakkaille ja synnyttävät eriasteisia reklamaatioita, asiakasvalituksia ja takuukorjauksia. Tyypillisesti 1-5 % valmistuneista tuotteista ja palveluista on viallisia tarkastuksen jälkeen. Mitä monimutkaisempi tuote, sitä enemmin korjauksia.
4.2. Laatu 4.0 -aloite – Laadun binäärinen luokittelu koneoppisella (LQC)
Yksi Laatu 4.0:n merkittävimmistä aloitteista on tarkastusjärjestelmän uudistaminen koneoppimiseen (ML) perustuvalla luokittelulla. Tätä järjestelmää kutsutaan Oppivaksi Laadunohjaukseksi (LQC) tai prosessin laatumonitoroinniksi (PMQC, MQC). LQC on sekoitus reaaliaikaista prosessinvalvontaa ja laadunohjausta. Sen päätavoitteisiin kuuluu harvinaisten laatutapahtumien (virheiden, vikojen) mallintaminen ja havaitseminen.
Virheiden ja vikojen havaitseminen muotoillaan binääriseksi luokitteluongelmaksi – viallinen (1), hyvä (0). Havaintodatan perusteella luodaan laatuluokille luokittelumalli li =f(xni):

Luokittelijan LQ-mallin luominen tapahtuu aikaisemmin esitetyn prosessin – Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen – avulla (kuva 2).
Koneoppimisella opetetaan tietokone luomaan ennustemalli (predict) lopputuotteen tai palvelun virheelle prosessin pienten poikkeamien avulla. Oleellista (ja vaikeaa) on löytää vialliseen lopputuotteeseen vaikuttavat ja ennustavat poikkeamat xni (virheiden ilmenemismuodot, features). Tähän on erilaisia matemaattisia työkaluja. Ongelma ”haaste” on samankaltainen lääkärin tekemälle sairauden ennaltaehkäisevä diagnoosi (luokittelu) oireiden perusteella.
Klassisessa tarkastuksessa (kuva 4) tarkastuksen kohteet, kriteerit ja ohjeet on yleensä luotu ”kokemuksen” mukaan. Jos tarkastus on yhdistetty mittauskoneeseen, käytetään yleensä tuotteen speksejä ja toleransseja rajoina. Näillä ei välttämättä ole tutkittua yhteyttä asiakkaiden kokemiin valituksiin ja reklamaatioihin. Six Sigman myötä gage R&R -menettely on osoittanut, että lähes puolessa projekteista mittaus on ongelma. Käsittelin tätä mittausongelmaa artikkelissa Bayes ”puhuu” meille tapahtumien syiden todennäköisyydellä, totuudesta?/13/ Artikkeli käsitteli mm. koronatestiä ja sen oikeellisuutta (≈ testin/tarkastuksen kyky paljastaa viallisuus, virus oikein). LQ mallissa vika tai viallisuus pyritään paljastamaan oikein (1).
Seuraava kuva 5 esittää SPC/SQC:llä ja LQC on ”buustattu” lopputarkastusta, jossa on oleellisesti pienemmät reklamaatio-, asiakasvalitus- ja takuumäärät. /1,3/ Tästä ehkä kannattaa aloittaa. Kun LQC-malli saadaan riittävän hyväksi, voidaan SPC/SQC:n ja statistiikkaan perustuva tarkastus ehkä poistaa. Yrityksen tavoitteena on Nolla-virhe, Zero Defects!
4.3. LQC-mallin luomisesta /1/
LQC-luokittelumallin luominen tapahtuu aiemmin esitetyllä 5-vaiheisella Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen – Identify, Observe, Data, Learn, Redesign (IODLR) – prosessilla. Prosessi on yhtä vaativa kuin Lean Six Sigma. Sen opettamiseen on ehdotettu samantapaista koulutus- ja sertifiointiohjelmaa kuin Six Sigmassa – Black Belt, Green Belt ja Yellow Belt. Tästä prosessista myöhemmissä artikkeleissa.
Tarkastelen LQC-mallin luontia yleisluontoisesti lähtemällä datasta, IODLR-prosessin kohdasta Opi (L). Ohitan siis tärkeät kohdat, kuinka Tunnista (I), Havaitse (O), Data (D) prosesseilla löydetään tekijät (xni), joilla voidaan havaintodatasta luoda ennustava malli. Six Sigmassa, jossa luodaan otantadataan ja tilastollisiin jakaumiin perustuva kokeellinen malli (DoE), näitä vastaa määrittely (D), mittaus (M) ja analysointi (A), joilla luotiin tilastollisen mallin ehdokas xni:t.
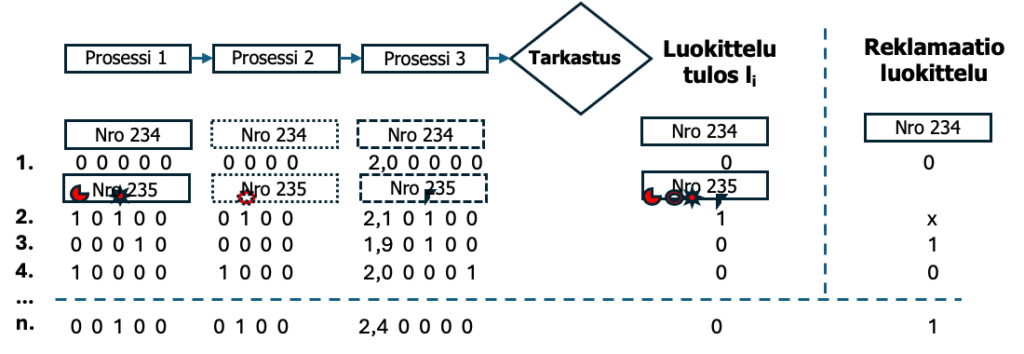
Oletetaan, että sinulla on prosessi, jossa tehdään suorakulmion muotoisia tuotteita kolmessa prosessivaiheessa. Jokaisessa vaiheessa voi syntyä poikkeamia (laatutaulussa kutsun näitä virheen ilmenemismuodoiksi = ominaisuudet, feature), jotka merkitään viallinen, hyvä (1, 0) merkinnällä (attribuutti) ja/tai mitatulla numerosuureella (variaabeli). Samoin valmis tuote luokitellaan viallinen, hyvä (1, 0) ja asiakkaan luokka viallinen, hyvä (1, 0). Kuvassa tuote Nro 234 on ”täydellinen”. Seuraavassa tuotteessa Nro 235 on lukuisia poikkeamia (virheen ilmenemismuotoja) prosessissa ja lopputuloksena tarkastus toteaa tuotteen vialliseksi (1). LQC mallinnuksessa annetaan jokaiselle poikkeamalle nimi (label, feature), jonka alle poikkeaman mitta merkitään samoin kuin laatutaulun virhemuodoilla jokaisella on nimi, label. Tuotetta Nro 235 ei lähetetä asiakkaalle. Seuraavassa tuotteessa on poikkeamia, mutta se on hyvä (0). Huom: Jokainen komponentti, prosessi- ja työvaihe kyllä poikkeaa toisistaan aina! Kysymys on, milloin poikkeama tai poikkeamien yhdistelmä, hyperavaruus, on ”liian” suuri johtaakseen tuotteen ja/tai reklamaation vian syntymiseen. Poikkeama voi olla niin suuri, että se on erityissyy, jolloin se haittaa tai jopa estää LQ-mallin luomisen. Erityissyyt voidaan määrittää ja ”poistaa” pystysuorista poikkeamariveistä yhdistämällä esim. päivän kunkin virheen ilmenemismuoto tilastollisesti esim. Poisson-jakaumalla. Katso laatutaulun analyysiä artikkelista Laatutaulu – Osa 5: Poikkeamatietojen analysointi.
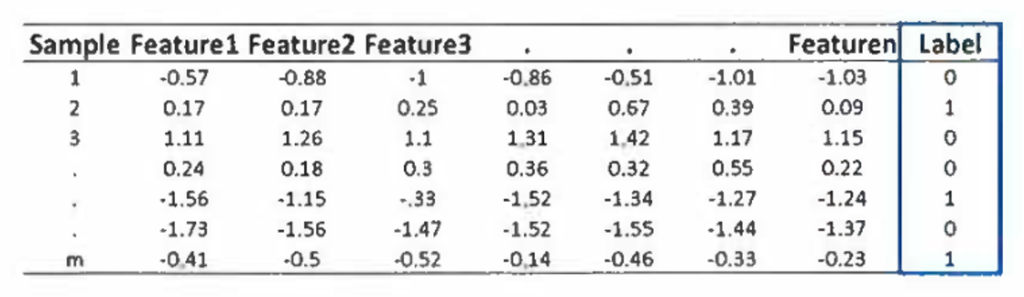
Jos kaikki valmistuksen ennustavat muuttujat voidaan mitata suoraan kuten esimerkiksi ruiskupuristuskoneesta, datamalli on kuvan 7 mukainen. Prosessi kestää muutaman millisekunnin tai sekuntteja, jolloin data syntyy. Feature on prosessin ominaispiirre, paine, lämpötila jne., joka poikkeaa ja jonka ajatellaan vaikuttavan osan tai tuotteen hyvä (0), viallinen (1) tilaan. Kuvassa ennustavat tekijät x ovat Feature 1…n ja ulostulo on merkitty ”Label” -sarakkeen alle.
4.4. LQC-koneoppimismallin laskennasta
Luokittelijan laskenta (malli + luokittelukynnys) on Oppivan Laadunohjauksen (LQC) ydin. luokittelijan onnistuminen riippuu suuresti luokittelijan kyvystä havaita tai ennustaa viallisia kohteita alhaisella väärien positiivisten tulosten osuudella. Koneoppimisen algoritmit laskevat yleensä ns. sekoitusmatriisin (confusion matrix), joka kertoo, kuinka paljon luokittelussa on oikeita viallisia ja hyviä päätöksiä ja kuinka paljon virheellisiä viallisia ja hyviä päätöksiä.
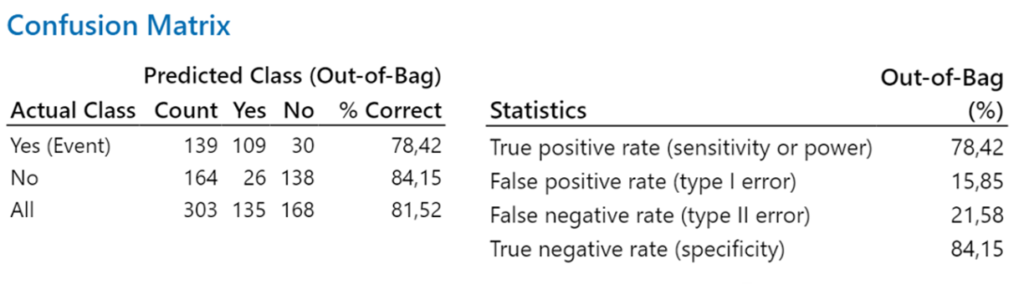
Matriisi osoittaa, kuinka hyvin malli erottelee luokat oikein. Tässä esimerkissä tapahtuman oikein ennustamisen todennäköisyys on 78,42 %. Ei-tapahtuman oikein ennustamisen todennäköisyys on 84,15 %. Malli on ei ole erityisen hyvä! (Minitab)
Koneoppimisalgoritmit poikkeavat tilastollisen koesuunnittelun (DoE, Six Sigma) malleista. DoE:ssa laskentamallit perustuvat lähes yksinomaan regressiomalliin, jonka kehitti Sir Francis Galton 1880. Sen sijaan koneoppimisen algoritmeilla (ML) ei ole olemassa yhtä laskentamenetelmää. Jatkuvasti kehitetään uusia variaatioita ja hybridimenetelmiä ja fuusioidaan malleja yhteen. Ne luokitellaan kuitenkin yleensä muutamaan pääkategoriaan ohjattu oppiminen (supervised) ja ohjaamaton oppiminen (unsupervised) ja näiden muunnelmia kuten puoliohjatut (semi-supervised) ja vahvistusoppivat (reinforsement) mallit.
Luokittelijassa käytetään ohjattua oppimisen algoritmia. Nämä algoritmit oppivat nimetystä (labeled) datasta (input-output-pareista) ennusteiden tai luokittelujen tekemiseksi.
Yleisiä algoritmeja ovat:
- Lineaarinen regressio (Linear Regression)
- Logistinen regressio (Logistic Regression)
- Päätöspuut (Decision Trees)
- Satunnaismetsät (Random Forests)
- Tukivektorikoneet (Support Vector Machines, SVM)
- Naivi Bayes (Naïve Bayes)
- K-lähimmät naapurit (K-Nearest Neighbors, KNN)
Osassa 1/14/ kerroin, että Minitabissa on neljä ensimmäistä, joista erityisesti Satunnaiset metsät (RF) -algoritmi on useissa lähteissä mainittu yhdeksi parhaimmista. Yleispätevää algoritmia ei vielä ole kehitetty. Siksi on erittäin suositeltavaa testata useiden algoritmien malleja ja päättää, mikä algoritmi sopii parhaiten dataan edellä kuvatulla sekaantumismatriisilla ja muilla mittareilla mitattuna. Minitabissa on algoritmi, joka etsii algoritmeista parhaimman mallin. Muitakin menetelmiä on. Katso osa 1.
ML-mallinnus ja tilastollinen mallinnus (Six Sigma, DoE) ovat kaksi lähestymistapaa sellaisten mallien rakentamiseen, jotka voivat tehdä dataan perustuvia ennusteita tai päätelmiä.
Tilastollinen mallinnus on perinteinen lähestymistapa, johon kuuluu tilastollisia tekniikoita muuttujien välisten suhteiden mallintamiseen ja ennusteiden tekemiseen. Tilastollisen mallinnuksen painopiste on taustalla olevan datan tuotantoprosessin ymmärtämisessä ja populaatiosta tehtävien päätelmien tekemisessä otosdatan, yleensäortogonaalimatriisi, perusteella. Tilastollisia malleja käytetään usein hypoteesien testaamiseen ja malliparametrien arvioimiseen.
Koneoppimismallinnuksessa käytetään algoritmeja datan mallien automaattiseen oppimiseen ja ennusteiden tekemiseen havaintodatasta. Koneoppimismallinnus keskittyy tarkkuuteen ja ennustamiseen pikemminkin kuin taustalla olevan datan tuotantoprosessin ymmärtämiseen; toisin sanoen ne ovat yleensä mustia laatikoita. Näitä malleja käytetään usein tilanteissa, joissa muuttujien väliset taustalla olevat suhteet ovat monimutkaisia ja vaikeita mallintaa perinteisillä tilastollisilla tekniikoilla.
Eri koneoppimisen algoritmeista on vähän vertailutietoja. Taulukossa (3) on koottuna muutamasta algoritmista tietoja.
Taulukko 3. Joitain Koneoppimisalgoritmeja ja niiden ominaisuuksia
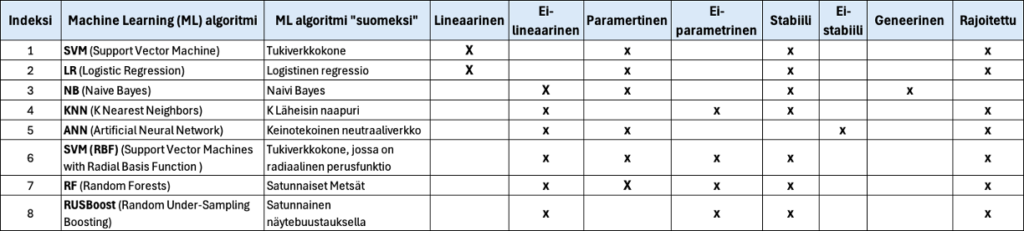
Erityisesti kannattaa taulukosta huomata, että lähes kaikki ML-algoritmit toimivat vain stabiilissa prosessissa kuten myös koesuunnittelu (DoE). Erityissyyt on tunnistettava, poistettava, ja hallittava prosessimuuttujista (xni) SPC:llä (laatutaululla). Se onnistuu analysoimalla koneoppimisen datataulukkoa aikajärjestyksessä pystysuoraan (osassa 1 kerroin, että laatutaulun data pitää kääntää vaakatasosta pystytasoon).
4.5. Satunnaiset metsät (Random Forests) algoritmista
”Satunnaiset metsät” on koneoppimisalgoritmi, joka rakentaa useita päätöspuita samasta datasta ja yhdistää ne. Näin saadaan tarkempi ja vakaampi ennuste (malli). Menetelmän kehittivät Leo Breiman ja Adele Cutler Berkeleyn yliopistossa Kaliforniassa ja rekisteröivät ”Random Forests” -nimen tavaramerkiksi vuonna 2006.
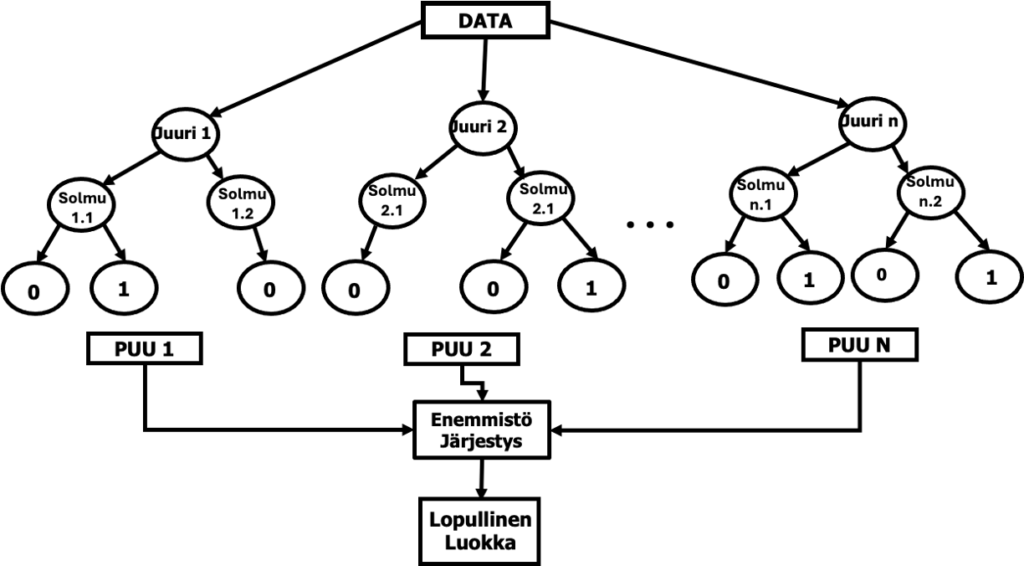
RF toimii valitsemalla satunnaisesti data- ja ominaisuusjoukkoja kunkin puun kouluttamiseksi, mikä vähentää ylisovitusta ja parantaa yleistystä. Lopullinen ennuste tehdään laskemalla keskiarvo kaikkien puiden tuloksista (regressio) tai äänestämällä (luokittelu). Random Forests käsittelee sekä numeerista että kategorista dataa ja on tehokas suurille,ulotteisille tietojoukoille. Se kestää kohinaa ja voi mallintaa monimutkaisia suhteita.
RF:n keskeiset käsitteet ovat bootstrapping ja ominaisuuksien pussittaminen (bagging):
- Bootstrapping: jokaiselle puulle valitaan satunnainen osa koulutusdatasta korvaamalla (eli sallimalla kaksoisnäytteet). Tätä osajoukkoa käytetään yhden päätöspuun rakentamiseen.
- Ominaisuuksien pussittaminen (bagging): jokaisessa päätöspuun jaossa vain satunnainen osajoukko ominaisuuksista otetaan huomioon jakamista varten. Tämä vähentää ylisovitusta ja parantaa yleistyskykyä.
Käytännössä RF:n hyvä suorituskyky on todistettu, monissa koneoppimisongelmissa, mukaan lukien binääriluokittelu. RF sopii erityisen hyvin taulukkomuotoisille tietojoukoille. Se on myös robusti kohinaiselle datalle ja pystyy käsittelemään sekä kategorisia että numeerisia ominaisuuksia. Koneoppimisen (ML) algoritmit, työkalut, ovat Minitab 22:ssa Predictive Analytics Module -valikossa.
5. Case Chevrolet Volta – uuden LQC laatuteknologian synty /16,17/
Uusi laadun valmisteknologia syntyi, kun Chevrolet Voltan pidemmän matkan sähköautoon (extended range electric vehicle, models 2016-2019) kehitettiin uutta akkujärjestelmää, jossa käytettiin ultraäänellä (UWBT-prosessi) hitsattuja akkulistoja. GM oli akkujen kehitysvaiheessa konkurssimenettelyn keskellä. Mikä tahansa Voltan vika voisi mahdollisesti vaikuttaa negatiivisesti neuvottelijoiden ja asiakkaiden näkemyksiin, ei vain GM:n, vaan myös sähköajoneuvojen tulevaisuudesta.
Ultraäänihitsaus (kuva 10) sinänsä oli luotettavaa, mutta sitä ei täysin ymmärretty. Ultraäänihitsaus on liitosprosessi, jossa fyysisessä kosketuksessa olevat kappaleet liitetään yhteen nopealla suhteellisella liikkeellä vierekkäisten pintojen välillä. Ultraäänihitsauslaite on laite, joka tuottaa värähtelyjä anturikokoonpanossa ja kohdistaa ne työkappaleisiin pyälletyn äänipään/torven avulla. Hitsausprosessi on erittäin vakaa, ja se tuottaa vain muutaman viallisen hitsin miljoonaa hitsauskertaa kohden (≈0,09 % = 900 ppm). Kaikkien akun hitsien on kuitenkin oltava kunnossa, jotta sähkömoottori toimii. Tämä ongelman esitys korostaa paitsi insinööritieteen haastetta, mutta on myös tärkeää Zero Defects -politiikan vuoksi. Autotehtaat noudattavat yleisesti Nolla-virhe eli Zero Defect laatupolitiikkaa.
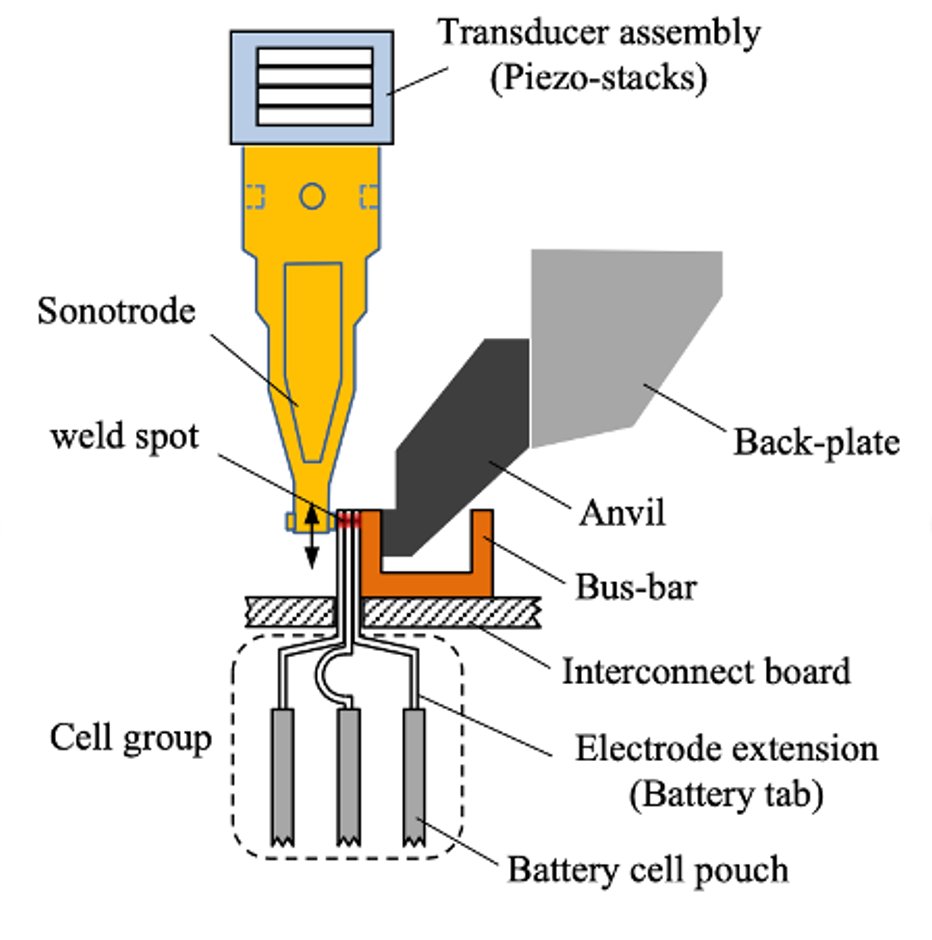
Jokaisen hitsauksen piti täyttää kaksi kriteeriä: toinen oli hitsauksen mekaaninen lujuus ja toinen sen sähkönjohtavuus. Liitoksen dilemma oli, miten rakentaa laadunvarmistusohjelma erittäin luotettavalle tuotteelle (<0,09 %), jonka suorituskykyominaisuuksia ei voida suoraan havaita/mitata eikä epäsuorasti päätellä.
Tilastollisen tuotteen laaduntarkastusmenettelyn (SPC/SQC) kehittäminen on yleensä rutiininomaista autotehtaille. Se perustuu tunnettuun teoriaan ja käyttää suoraan ja rikkomattomasti havaittavia tuotteen laatuominaisuuksia, joilla arvioidaan tuotteen sopivuutta aiottuun tarkoitukseen. Tässä akkuliitosprosessissa näin ei voitu toimia. Oli luotava uusi tapa.
UWBT-projektin alkuperäinen tavoite oli vähentää akkuliuskojen manuaalista tarkastusta 100 prosentista 50 prosenttiin.Toteutus tehtiin luokittelijan muodossa, jossa kaksi päätösluokkaa on ”hyvä” ja ”epäilyttävä” verrattuna kahteen laatuluokkaan ”hyvä” ja ”huono”. Hitsi, jonka ominaisuudet olivat aiemmin tunnistetun ”hyvän” alueen ulkopuolella, eli ”epäilyttävä” hitsi, ei tarkoittanut, että hitsi oli huono, vaan että sitä ei voitu luokitella hyväksi. Huolellisuusvaatimusten mukaisesti kyseistä hitsausta tutkittiin lisää.
Kerätty datajoukko sisälsi binäärisen tuloksen (hyvä/epäilyttävä), jossa on 54 ominaisuutta, jotka on johdettu signaaleista (esim. akustiikka, teho ja lineaariset vaihtelevat differentiaalimuuntajat) tyypillisten ominaisuuksien rakennustekniikoiden mukaisesti. Datajoukko on erittäin epätasapainoinen, koska se sisältää vain 36 viallista akkua 40 231 esimerkistä (0,09 %). Aineisto on jaettu aikajärjestyksessä olevan odotusvalidointimenetelmän mukaisesti: koulutusjoukko (18 495 – mukaan lukien 20 epäilyttävää), validointijoukko (12 236 – 9 epäilyttävää) ja testijoukko (9 500 – 7 epäilyttävää).
Lukuisia koneoppimisen algoritmeja (MLA) testattiin (Classifier). Taulukko 4
Taulukko 4. Akkuliuskojen hitsauksen luokittelumallit. MLA=koneoppimismalli, FN – TP sekaannusmatriisi, MPCD (Maximum Probability of Correct Decision) yhdistetty valintaindeksi/16/
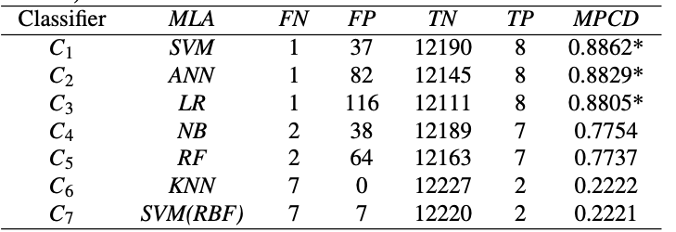
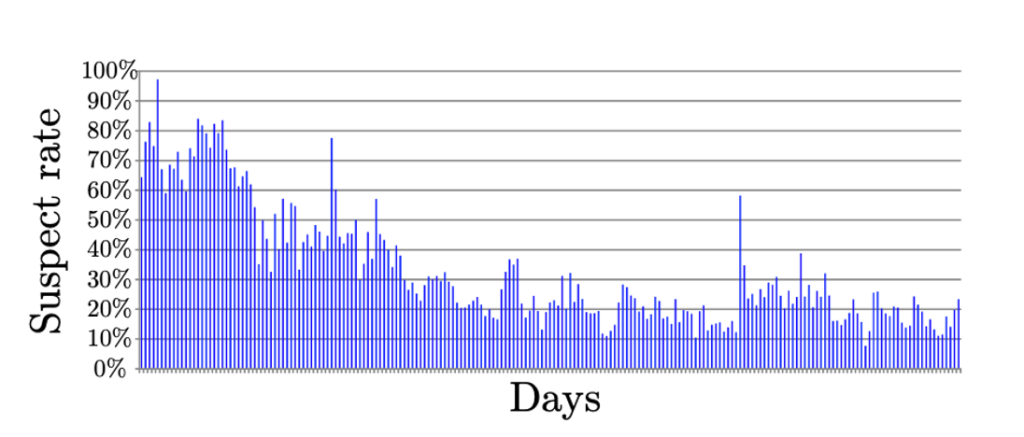
Kuvasta (11) havaitaan, että big data lähtöinen LQC prosessi vähensi merkittävästi epäilyttävien hitsien määrää, joka oli alkuperäinen tavoite. Hitsausprosessi opittiin ja manuaalinen tarkastusmäärä väheni.
6. Yhteenveto
Binääriluokittelu on hyvin laaja aihe, ja vaihtoehtoja on runsaasti. Tekoälyyn ja koneoppimiseen perustuvaa voidaan käyttää useisiin prosessin hallinta- ja luokitteluongelmiin. Olemme vasta taipaleen ensimetreillä. Vielä ei ole tietoa, mitä kaikkea tulee ja mihin kaikkeen luokittelu sopii.
Tarkastelin artikkelissa LQC:tä ja sen liittymistä aikaisempiin laatutekniikan menetelmiin. Oleellista on, että tämä tekniikka ei poista aikaisempia laatutekniikan menetelmiä, jotka pääosin ovat rakentuneet näytedatan ja tilastollisten jakaumien ja oletusten varaan. Uusi tekniikka perustuu havaintodataan ja siitä tekoälyn ja koneoppimisen muodostamiin laskentamalleihin, jotka ennustavat (predict) ”lähi” tulevaisuutta. Ennaltaehkäisy ja sen ennusteet käsittelevät ”kaukaista” tulevaisuutta (Six Sigma) ja perustuvat otosdataan eli datan ”haisteluun” (ortogonaalimatriisiin).
LQC:n oppimisparadigma vaatii useiden mallien kehittämistä ja valintaa lopullisen mallin löytämiseksi. Big Models noudattaa iteratiivista prosessia, jossa etsitään datasta kuvioita. Kuvioiden tunnistusongelma voidaan ratkaista valitsemalla oikeat oppimisalgoritmit ja niihin liittyvät hyperparametrit. Ennuste voidaan optimoida päätösten yhdistämismenetelmällä.
LQC-mallin luomiseksi käytettiin 5-vaiheista prosessia – Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen – Identify, Observe, Data, Learn, Redesign (IODLR). LQC-prosessin oppiminen vaatinee Six Sigma -tasoisen 3-4 viikon koulutuksen.
IODLR-prosessi on yleinen havaintodatan mallinnusprosessi, joka sopii hyvin monenlaisten prosessien mallintamiseen, jossa on input-output suhde. Uskon, että tulevaisuudessa kaikkien on hallittava havaintodatan mallinnusmenetelmät kuin myös tilastolliset otantadataan perustuvat mallinnusmenetelmät, DMAIC-prosessi (Six Sigma).
Eri tutkimuksissa on arvioitu, että 95 – 99 % nyt prosesseista tulevasta datasta on analysoimatta. Tässä on suuri mahdollisuus. LQC-prosessilla voimme hyödyntää merkittävän osan havaintodatasta ja mikä oleellista, voidaan parantaa laatua ja päästään lähemmäksi Nollavirhe -visiota, ennaltaehkäisyä ja Six Sigmaa unohtamatta. Molempia tarvitaan.
Artikkelin on kirjoittanut Eero E. Karjalainen (Senior Specialist, hallituksen puheenjohtaja).
https://www.linkedin.com/in/eero-e-karjalainen/
Lähteet:
- Carlos A. Escobar, Ruben Morales-Menendes: Machin Learning in Manufacturing – Quality 4.0 and the Zero Defects Vision (2024)
- Carlos A. Escobar, Jeffrey A. Abell, Marcela Hernandez-de-Menendeza, Ruben Morales-Menendez: Process-Monitoring-for-Quality — Big Models (2018)
- Carlos A. Escobar, José Antonio Cantoral-Ceballos & Ruben Morales- Menendez: The decay of Six Sigma and the rise of Quality 4.0 in manufacturing innovation (2024)
- Gregory H. Watson: The Ascent of Quality 4.0, Quality Progress 25, (2019)
- Carlos A. Escobar, Michael A. Wincek , Debejyo Chakrabortya, Ruben Morales-Menendez: Process-Monitoring-for-Quality—Applications (2017)
- Carlos A. Escobar, Megan E. MacGovern & Ruben Morales- Menendez: Quality 4.0: a review of big data challenges in manufacturing, (2012)
- Philip Crosby: Quality is Free: The Art of Making Quality Certain, (1979)
- Philip Crosby: ”Laatu on Ilmaista” (laatuyhdistyksen kustantama käännös) (1986)
- Eero E. Karjalainen: ”Laatu 4.0 ja Lean Six Sigma 2.0 (https://qkk.fi/laatu-ja-lean-six-sigma/ ) taulukko 1(2018)
- Eero E. Karjalainen, Tanja Karjalainen: Lean Six Sigma 2.0 ja laatuteknologia, (2020)
- https://qkk.fi/laatutaulu-kehitysvaiheet-iii-vi/ kuva 20
- https://qkk.fi/laatutaulu-poikkeamatietojen-analysointi/ kuva 18 + Case ”Eimo”.
- Eero E. Karjalainen: Bayes ”puhuu” meille tapahtumien syiden todennäköisyydellä, totuudesta? https://qkk.fi/bayes/ (2020)
- Eero E. Karjalainen: Koneoppimisesta (ML) ja Laatutaulusta (SPC) – Osa 1 https://qkk.fi/koneoppimisesta-ja-laatutaulusta-osa1/ (2026)
- Carlos A. Escobara, Debejyo Chakrabortya, Megan McGoverna, Daniela Maciasb, RubenMorales-Menendez: Quality 4.0 — Green, Black and Master Black Belt Curricula (2021)
- Escobar, Jeffrey A. Abellb, Marcela Hernandez-de-Menendez, Ruben Morales-Menendez: Process-Monitoring-for-Quality — Big Models (2017)
- Jeffrey A. Abell, Debejyo Chakraborty, Carlos A. Escobar, Kee H. Im, Diana M. Wegner, Michael A. Wincek: Big Data Driven Manufacturing —Process-Monitoring-for-Quality Philosophy (2017)

Tutustu kurssitarjontaamme!


Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.