
Edam ja EDA?
Piru on yksityiskohdissa, sanoo englantilainen. Edam on mieto juusto, joka päätyy leivän päälle tai sen väliin. Mutta mikä on vähemmän tuttu EDA, jonka ulkomuoto on 75 % samanlainen? Ja missä sitä käytetään?
Datan visualisointi ja graafien tulkinta on yleinen kerätyn tiedon tai datan käytön muoto. Otamme tueksemme numerot ja niiden keräämisen, esittämisen ja kuvaamisen keinot, kun tutkitaan tuotteita, juuston valmistuksen prosesseja, systeemejä, tuotantoa, saunan lämmittämistä, pannukakkuja, ihmisten käyttäytymistä, luonnon ilmiöitä, unta tai ihan mitä tahansa mikä meitä uteliaita ihmisiä sattuu kiinnostamaan. Pelkkiä lukuja tai niistä tehtyä yhteenvetoa ei yleensä pysty sellaisenaan viestimään tai mielekkäästi tulkitsemaan, joten joudumme piirtämään ne auki.
Kun koitamme ymmärtää mitä tapahtuu tai mitä pitäisi tehdä, tarvitsemme tutkittavaa ilmiötä korkeamman tarkastelun tason ymmärtääksemme asioiden syitä ja seurauksia. Näihin abstraktioiden apukeinoihin ongelmanratkaisussa viitataan yleensä tilastollisina menetelminä. Silti monia ihmisiä ahdistaa lukujen ja numeroiden käyttö ongelmia tutkittaessa. Miksi ei vain voida käydä selvittämässä asia paikan päällä? Onko pakko mitata?
Koska kiinnostavista ja monimutkaisista ilmiöistä on pelkästään tarkkailemalla mahdoton tehdä järkeviä johtopäätöksiä, ajaudumme datan keräämiseen ja tilastollisiin menetelmiin. Hyvin usein tarkkailu on jopa mahdotonta ja siitä syystä mittareista saatu tieto on ainoa mitä voimme käyttää. On hyvin hankala arvioida esimerkiksi saunan lämpötilaa sen ulkopuolelta ilman mittaria tai nettisivujen käyttäjäliikennettä ilman palvelimelta saatavaa dataa. Saunan lämmön voi ihminen toki tuntea, mutta nettisivun kävijäliikennettä ei (ehkä teoriassa, mutta jätetään viisastelu sen osaajille). Menneisyydestä ei voida sanoa paljoakaan, jollei siitä ole jäänyt dataa.
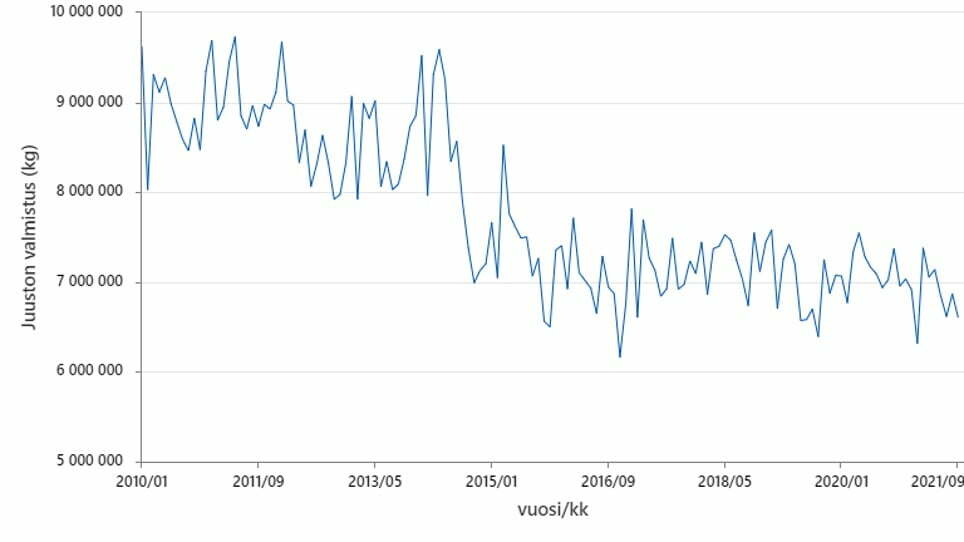
Vaikka tilastollisuudesta tulee usein mieleen erilaiset tilastolliset testit tai siisteiksi tietueiksi kerätty aineistot, ovat ne vain osa tilastollisen ajattelun ja menetelmien laajaa kirjoa. Jotta pystymme käsittelemään tarkkailukykymme ja kärsivällisyytemme rajojen ulkopuolella olevia asioita, ihminen tarvitsee abstraktioita, joilla voitaisiin ymmärtää paremmin käsiteltävää ongelmaan. Näitä ovat yksinkertaisimmillaan datasta piirretyt kuvat tai graafit, jotka kertovat ilmiöstä paremmin kuin yksittäiset tunnusluvut tai numerot. Esimerkiksi juuston valmistuksen määrän vaihtelua Suomessa on vaikea tiivistää yhdellä luvulla, mutta se on helppo näyttää kuvalla (kuva 1).
Kuvasta nähdään, että juuston kuukausittainen valmistusmäärä on laskenut vuoden 2014-2015 paikkeilla ja tarkastelujakson alkuun nähden nykyinen keskiarvo on tippunut noin 1,5 miljoonaa kiloa per kuukausi. Kuvasta tietysti tulisi ideoita syistä miksi näin on käynyt. Eikö suomalaiset enää syö juustoa? Miksi juustoa ei enää tehdä kuten ennen? Onko tuontijuusto syynä tähän alamäkeen? Miksi käyrä on siirtynyt?
Mikä on EDA?
EDA on lyhenne sanoista Exploratory Data Analysis, joka kääntyisi suomeksi tutkivaksi data-analyysiksi. Kyse on ongelmanratkaisussa tai tutkimuksessa käytettävästä lähestymisestä, jonka tarkoituksena on auttaa tutkijaa keksimään ideoita ilmiöiden syistä ja siten muodostamaan olettamuksia, eli hypoteeseja testattavaksi. Vaihtoehtoisesti voi syntyä ideoita, joita vaativat uuden datan keräämistä.
EDA on olemassa olevan tai kerätyn havaintoaineiston kuvaamista ja sen hiljaisten piirteiden tulkintaa. Tutkivassa analyysissa on kolme päävaihetta I) näytä data II) tunnista hiljaiset piirteet III) tulkitse hiljaisia piirteitä. Kuvassa 2 on esitetty EDA:n malli, kuten Jeroen de Mast ja Benjamin Kemper sen klassisessa artikkelissaan 2009 esittivät.
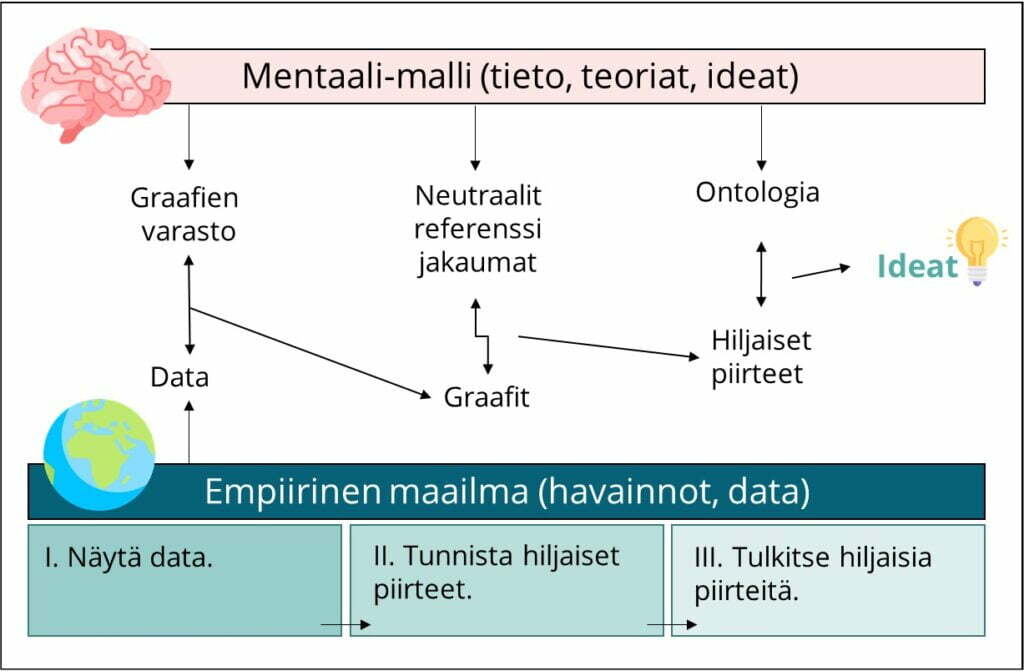
Kuten de Mast ja Kemper myös totesivat, on hyvä ymmärtää, että mikään data itsessään ei luo yhtään hypoteesia tutkittavaksi. Tarvitaan tutkijan mentaalimalli, jonka tiedon, teorioiden ja ideoiden yhdistelmät vuorovaikutuksessa varsinaisen empiirisen maailman havaintojen ja datan kanssa synnyttävät uudet ideat ja testattavat hypoteesit.
Jotta datan piirteitä voidaan tunnistaa ja tulkita tulee olla keinot näyttää kerätty data ymmärrettävällä visuaalisella tavalla. Tyypillisesti EDA:ssa halutaan nähdä ja ymmärtää datan hajontaa, käyttäytymistä ajan suhteen, sekä ryhmitellä dataa mielenkiintoisten luokkien avulla ja purkaa hajontaa luokkien välillä ja niiden sisällä.
Näihin käytettäviä perusmenetelmiä ovat yleensä histogrammit, boxplotit, hajontakuvaajat (scatterplot), aikasarjat ja ohjauskortit. Kaikki perusmenetelmät ja myös paljon muuta löytyy esimerkiksi Minitab-ohjelmistosta, joka on tarkoitettu juuri tilastollisten menetelmien ja kuvaajien käyttämiseen.
Siinä missä edam on mieto ja mauton juusto, EDA voisi tuoda ideoita juuston mauttomuuden vaihtelun syistä. Ideoista syntyisi olettamia seurausten ja syiden yhteydestä. Näitä olettamia, eli hypoteeseja voisi testata käyttämällä erityyppisiä tilastollisia testejä tai kokeellisia menetelmiä. Kyse on vahvistavasta data analyysista (confirmatory data analysis, CDA).
Tehtävien testien tulokset antaisivat näyttöä oletetuista yhteyksistä syyn ja oletetun seurauksen välillä. Eli saisimme tietoa, pitääkö teoriamme tutkittavasta ilmiöstä paikkansa vai ei. Jos käytetään tilastollisia testejä, koeasetelmia tai näistä tehtyjä malleja on testin tulos ilmoitettu P-arvona, eli testattavan hypoteesin mahdollisuutena verrattuna satunnaisuuteen. Jos satunnaisuus hylätään (P < riskitaso) voidaan todeta, että on löydetty tilastollinen ero (syy)!
Uusia kuvakulmia Graph Builderilla
Minitab versioon 20 päivityksenä tullut Graph Builder on mielenkiintoinen työkalu kuvien piirtämiseen ja datan tutkimiseen. Varsinkin uudet Minitabin käyttäjät ovat todenneen Builderin olevan hyödyllinen datan analyysiä opetellessa, koska se näyttää suoraan erilaiset vaihtoehdot kuvista, joita valituista muuttujista voisi tehdä.
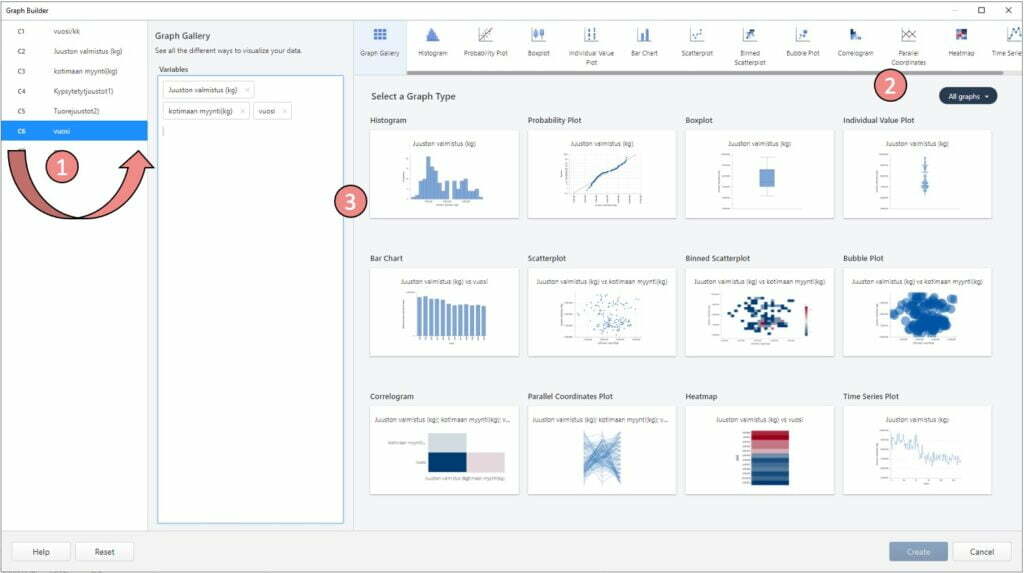
Graph builder löytyy Graph-valikon ylimmäisenä ja se käyttää Minitabin päivitettyä graafista ulkomuotoa ja tekotapaa. Kuvissa on interaktiivisia ominaisuuksia ja lisäksi värien sävyillä voidaan tulkita esimerkiksi havaintojen keskittymistä tai kolmatta ulottuvuutta (summaa, keskiarvoa yms.), jotka ovat toimivia varsinkin suurien data-aineiston tarkastelussa.

Näitä versiossa 20 ensi kertaa esiintyneitä sävyjä ja kuvien piirtotapaa käytetään uudemmissa graafisissa kuvaajissa, kuten heatmap, binned scatterplot ja correlogram. Graph Builderin kautta saadaan myös vanhanmallisten kuvien päivitettyjä versioita ja niihin interaktiivisia ominaisuuksia. Joten kaikki kuvat, jotka eivät näytä perinteiseltä Minitabilta voivat silti olla sillä tehtyjä.
Suosittelen Graph Builderin kokeilua, siitä voi saada uusia ideoita erilaisille kuville!
Lähteet:
- Jean de Mast, Benjamin P.H Kemper. Principles of Exploratory Data Analysis in Problem Solving: What can we learn from a well-known case, Quality Engineering, 21:366-375, 2009.
- Suomen virallinen tilasto, Luonnonvarakeskus, Maito- ja maitotuotetilasto, syyskuu 2021 (ennakko).


Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.