
Päivitetty 17.11.2022
Mikä on t-testi?
Tänä päivänä tilasto-ohjelmistot, kuten Minitab, ovat tuoneet tilastolliset analyysit jokapäiväiseen käyttöön. Laskenta ei enää ole työlästä eikä kaavoja tarvitse muistaa. Riittää, kun osaat kerätä oikeanlaisen näytteen, sijoittaa datan Minitab-worksheetille ja valita oikean analyysin. Sen jälkeen ohjelma suorittaa laskennan ja piirtää kuvat. Sinun tarvitsee vain osata tulkita tuloksia.
T-testi on yksi käytetyimmistä tilastollisista testeistä. Testistä laskettu statistiikka noudattaa Studentin t-jakaumaa. T-testiä voidaan soveltaa, jos otos on poimittu perusjoukosta, joka on ”likimain” normaalijakautunut ja toisistaan riippumatonta. Ennen testin käyttöä tulisi testata näytteen normaalisuus ja stabiilisuus, joka käy helposti Minitabilla. T-testiä voidaan käyttää yhden otoksen keskiarvon testaamiseen, kahden riippumattoman otoksen tai kahden riippuvan otoksen keskiarvojen yhtäsuuruuden testaamiseen. Erityisen tärkeä testi on yhden otoksen keskiarvo. Tällä testillä testataan, onko esimerkiksi työstökoneen asetus oikein. Prosessin keskiarvon olisi oltava mahdollisimman lähellä keskiarvoa!
Mutta edes ihmiset, jotka usein käyttävät t-testiä eivät aina tiedä, mitä datalle tapahtuu käyttäessämme Minitabia. Kurkistetaan verhon taakse. Jos ymmärrät kuinka t-testi toimii, ehkä ymmärrät paremmin mitä tulokset todella tarkoittavat. Ehkä myös ymmärrät paremmin, miksi testi antoi tai ei antanut tilastollisen merkittävyyden.
t-testin anatomia
t-testiä yleensä käytetään määrittämään eroaako populaation/prosessin keskiarvo tilastollisesti jostakin nimenomaisesta arvosta (hypoteesikeskiarvosta tai tavoitearvosta) tai eroaako kahden populaation keskiarvot toisistaan.
Esimerkiksi 1-sample t-testillä voidaan testata onko terveysasemalla olevien potilaiden odotusaika suurempi kuin ylärajaksi määritelty tavoiteaika, joka on 15 minuuttia. Analyysi tehdään perustuen satunnaiseen näytteeseen potilaista.
Määritelläkseen, onko ero tilastollisesti merkittävä, t-testi laskee t-arvon (testistatistiikan), jonka perusteella ohjelmistoista saadaan ulos p-arvo.
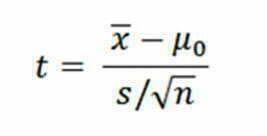
Kaava saattaa näyttää mystiseltä. Ehkä se ei tunnu niin pahalta, jos ajattelet että siinä on kaksi vaikuttavaa osaa: osoittaja (yläpuolella) ja nimittäjä (alapuolella).
Osoittaja on signaali
Osoittaja 1-sample t-testin kaavassa mittaa signaalin voimakkuutta: eroa näytteen keskiarvon (x-viiva) ja hypoteesikeskiarvon (tavoitearvo, µ0) välillä.
Jos ajatellaan potilaiden odotusesimerkkiä, tavoite maksimiodotusajalle oli 15 minuuttia. Jos satunnaisen näytteesi keskiarvoinen odotusaika on 15,1 minuuttia, signaali on 15,1 – 15 = 0,1 minuuttia. Ero on suhteellisen pieni, joten osoittajan signaali on heikko.
Kuitenkin, jos satunnaisen näytteesi potilaiden keskimääräinen odotusaika onkin 68 minuuttia, ero on paljon suurempi. 68 – 15 = 53 minuuttia. Signaali on vahvempi.
Sama analogia pätee sorvattavaan kappaleeseen kuin potilaaseen. Ero tavoitekeskiarvosta toleranssien välissä.
Nimittäjä on kohina
1-sample t-testissä nimittäjä mittaa näytteen vaihtelua tai ”kohinaa” (noise).
Kaavassa s on standardipoikkeama, joka kertoo sinulle kuinka paljon data vaihtelee. Jos joku potilas odottelee 50 minuuttia, toinen 12 minuuttia, kolmas puoli minuuttia ja neljäs 175 minuuttia jne, se tarkoittaa suurta standardipoikkeamaa eli meillä on paljon vaihtelua.
Jos taas joku potilas odottaa 12 minuuttia, toinen 14 minuuttia, kolmas 13 minuuttia ja neljäs 15 minuuttia jne, meillä on vähemmän vaihtelua, joka tarkoittaa pienempää standardipoikkeamaa eli vähemmän kohinaa.
Entä standardipoikkeaman alla oleva √n? Se on neliöjuuri näytekoostasi.
t-arvo on signaalikohinasuhde
Kuten kaava esittää, t-arvo yksinkertaisesti vertaa signaalin voimakkuutta (eroa) kohinan määrään (vaihteluun) datassa. Jos signaali on heikko suhteessa kohinaan, t-arvo on pienempi. Eli ero ei todennäköisesti ole tilastollisesti merkittävä.
Palataan takaisin potilaiden odotusaikaan. Oletetaan, että molemmissa tapauksissa keskiarvo on sama vähän reilu 30 minuuttia, mutta ensimmäisessä tapauksessa vaihtelua on paljon ja toisessa tapauksessa vaihtelua on vähän.
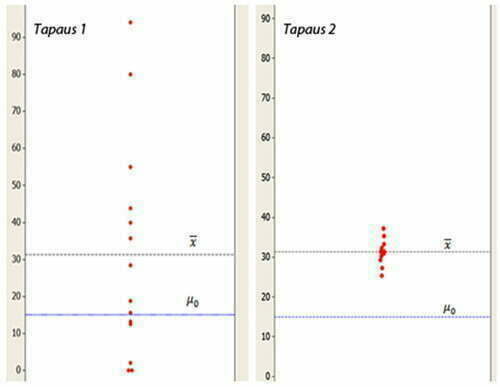
Ensimmäisessä tapauksessa ero näytteen keskiarvon ja hypoteesiarvon välillä on noin 16 minuuttia. Mutta koska havainnot ovat levinneet laajasti toisin sanoen vaihtelua on paljon, ero ei ole tilastollisesti merkittävä. T-arvo – signaalikohinasuhde – on suhteellisen pieni johtuen suuresta nimittäjästä. Kuitenkin, jos signaali olisi vahva suhteessa kohinaan, t-arvo olisi suurempi. Toisessa tapauksessa ero näytteen keskiarvon ja hypoteesiarvon välillä on sama kuin ensimmäisessä tapauksessa, noin 16 minuuttia. Näytekoko on myöskin sama. Mutta tällä kertaa data on tiukemmin nipussa. Eli vaihtelua on vähemmän. Tästä seuraa, että sama 16 minuutin ero onkin nyt tilastollisesti merkittävä ero.
t-testin suorittaminen
Hypoteesitestit suoritetaan yleensä 95 %:n luottamustasolla (alfa-riski 0,05) eli suomeksi vähemmän kuin joka 20:s päätös on väärin. Hypoteesitestauksessa on määritettävä ongelma käytännön termein, muunnettava se tilastollisiksi termeiksi, kerättävä data, suoritettava tilastollinen testi, määritettävä tilastollisen testin tulos ja käännettävä testin tulos käytännön ratkaisuksi.
Suorittaessamme testin asetamme ensimmäisenä nollahypoteesin ja vaihtoehtoisen hypoteesin. Nollahypoteesi ja vaihtoehtoinen hypoteesi kannattaa kirjoittaa ensimmäiseksi ylös. Nollahypoteesia voi ajatella: ei yhteyttä olemassa (tai ei ole eroa) ja vaihtoehtoinen hypoteesi on: yhteys on olemassa (tai ero on olemassa).
Sitten keräämme datan. Sen jälkeen me suoritamme tilastollisen testin, jonka perusteella määritämme hyväksymmekö vai hylkäämmekö nollahypoteesin. Jos hyväksymme sen, toteamme ettei yhteyttä tai eroa ole olemassa. Jos hylkäämme sen, toteamme että tilastollisesti merkittävä yhteys tai ero on olemassa.
Nykypäivän ohjelmistot tekevät hypoteesitestauksesta suhteellisen yksinkertaista. Syötät datan, suoritat sopivan testin ja softa palauttaa tuloksen p-arvon kera. Jos softaa ei ole käytettävissä, testit voi tehdä myös manuaalisesti ja tuloksen lukea taulukoista.

Kahden näytteen t-testi (2-sample t)
Otetaan esimerkiksi tilanne, jossa haluat selvittää onko eroa kahden paikkakunnan myyntimäärissä. Määritetään ensimmäiseksi käytännön ongelma. Onko eroa kahden myyntipaikkakunnan myyntimäärissä? Asetamme nollahypoteesin: ei ole eroa kahden paikkakunnan myynnissä.
Myyntipaikkakunnalla A on sama myyntimäärä kuin paikkakunnalla BMyyntipaikkakunnalla A ei ole sama myyntimäärä kuin paikkakunnalla B
Sen jälkeen käännetään käytännön ongelma tilastolliseksi ongelmaksi. Kirjoitettuna se on:
H0: Myynti A paikkakunnalla = Myynti B paikkakunnalla
HA: Myynti A paikkakunnalla ≠ Myynti B paikkakunnalla
Sitten kerätään data. Tässä tapauksessa voimme ottaa satunnaisen näytedatan kahdelta eri paikkakunnalta. Valitaan sopiva tilastollinen testi. Tässä tapauksessa voimme suorittaa two-sample t-testin ja määrittää hyväksymmekö vai hylkäämmekö nollahypoteesin. Jos p-arvo on suurempi kuin 0,05 tällöin hyväksymme nollahypoteesin. Jos p-arvo on pienempi kuin 0,05, hylkäämme nollahypoteesin.
Viimeisenä vaiheena käännämme tulokset käytännön ratkaisuksi.
Jos nollahypoteesi hyväksytään, valitsemme:H0: Myyntipaikkakunta A on yhtäläinen tai ei ole eroa myyntipaikkakuntaan B
Jos nollahypoteesi hylätään, valitsemme:HA: Myyntipaikkakunta A on erilainen kuin myyntipaikkakunta B
Päätöksenteko on siis toimi, josta muodostetaan johtopäätös perustuen dataan ja/tai näyttöön. Tilastollinen päätöksenteko muodostaa ja vetää johtopäätökset perustuen matemaattiseen datan yhteenvetoihin, joista voidaan estimoida riskitaso ja luottamusväli.
Tilastollisen teorian käytöllä ja työkalujen avulla, yritämme vastata kolmeen peruskysymykseen:
1. Kuinka minun pitäisi kerätä dataa?
2. Kuinka minun pitäisi analysoida ja yhdistää dataa, jota olen koonnut?
3. Kuinka tarkat data yhteenvetoni ovat? Virhe?
Viimeinen kysymys on kriittinen ja johtaa seuraaviin yleisiin johtopäätöksiin ja ala- tai jatkokysymyksiin. On muistettava, että jokainen numero, jota tarkastelet, olkoon se yksittäinen mittaustulos tai tilastollinen yhteenveto, voi olla väärä. Teemme kuitenkin aina johtopäätöksiä näytteen perusteella, johon liittyy omat ominaisuutensa. Myös mittaussysteemi voi olla ongelmana.
Voihan olla, että mittaus ei tosiasiassa mittaakaan, mitä sen on tarkoitus mitata. T-testit eivät huomioi näitä asioita vaan niihin täytyy paneutua erikseen.
Minitabin Assistant
Versioon 16 Minitab toi vielä lisää helpotusta ohjelman käyttöön lanseeraamalla Assistant -valikon. Assistant tekee data-analyysistä vieläkin helpompaa. Vuosien ajan Minitab -käyttäjät toivoivat helpotusta analyyseihin. Tänäpäivänä käytössä olevassa versiossa 21 Assistant-osio on kehittynyt merkittävästi.

Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.