
Teollisuus 4.0 ja Laatu 4.0 ovat termejä, jotka kuvaavat uusia teollisuuden ja laatuorganisaatioiden radikaaleja muutoksia. Nämä muutokset vaativat erityistä osaamista. Sen sijaan, että reagoimme tapahtumiin ja niiden virheisiin ja poikkeamiin, reagoimme tekoälyn (LQC) antamaan ennustemalliin ja mallin antamiin virhe ja -poikkeamaennusteisiin. Malli kertoo ennusteen lisäksi myös juurisyyehdokkaat. Niitä ovat tekijät, jotka vaikuttivat eniten malliin ja sen luomaan ennusteen. Muutos on suuri! Tähän asti on reagoitu jo tapahtuneeseen asiaan, menneeseen. Juurisyyt on ”arvattava” tai suoritettava erillinen juurisyyn selvitysprosessi yhdistettynä kausaalikokeeseen (DoE), koska välittömälle havaintodatalle ei ole ollut helppoa, ”järkevää” ja luotettavaa syyanalyysiä. Ainoan poikkeaman muodostaa SPC ja sen indikoima erityissyyn olemassaolon todennäköisyys.
Koneoppimismalli yhdistettynä laatutekniikkaan (Machine Learning ja Learning QC) mahdollistaa mallinnuksen ja ennustuksen empiirisestä havaintodatasta välittömästi ennen virheen ja vian tapahtumaa, jolloin oikealle reaktiolle jää aikaa. Tämä on uutta ohjausta. Tilannetta voi verrata säähän. Voit mennä ulos ja todeta, sataako vettä ja hakea sateenvarjon sisältä. Tämä on jälkireagointia ja sisältää ”turhaa” työtä! Vai katsotko sadetutkan havaintodatan antamaa sade-ennustetta – otanko vai en sateenvarjon ennen ulos poistumista. Voit vain kuvitella, miten paljon parempi ja tuottavampi tekoälyn luoma uusi ohjaustapa on ja miten paljon virhe ja vikaprosentit paranevat!
Koneoppimismallia (korrelaatiomalli) ei pidä sekoittaa Lean Six Sigmaan ja sen kokeellisesta (parametri)datasta (DoE) luotuun ennustemalliin (kausaalimalli). Korrelaatiomalli pätee juuri tähän hetkeen ja mahdollistaa välittömien virheiden ohjauksen, kun taas kausaalimalli mahdollistaa löytämään ja optimoimaan virheettömän olosuhdetilan uudet parametrit ja ehkäisemään ei-välittömät virheet ja viat mallin (ennusteen) avulla. Korrelaatiomalli on ohjausta ja kausaalimalli on parantamista.
Tämä muutos, koedatan (Laatu 3.0) täydentyminen havaintodatalla (Laatu 4.0) on seurausta tehokkaiden tekoäly- ja koneoppimisalgoritmien (MLA) keksimisestä ja uusien digitaalisten teknologioiden integroinnista teollisiin prosesseihin ja näiden kasvaneista laadun hallintavaatimuksista – NOLLA-virhe vaatimus. Teollisuus 4.0:n tavoitteena on mahdollistaa älykkäät palvelu- ja tuotetehtaat, jotka tuottavat räätälöityjä palveluja ja tuotteita automaattisesti samalla, kun käytetään ympäristöystävällisiä ja tehokkaampia prosesseja. Nämä automaattiprosessit vaativat toimiakseen (lähes tai täysin) virheettömät päätökset, komponentit ja vikavapaat ja samalla robustit prosessit. Ei ole mieltä eikä menetelmää yrittää poimia/tarkastaa harvinaisia ja virheellisiä päätöksiä, komponentteja ja prosessoituja kokonaisuuksia pois valmiista osakokonaisuuksista, palveluista, laitteista ja järjestelmistä.
Jotta tähän päästään, valmistajien on ylitettävä useita esteitä, kuten pätevien henkilöiden löytämisen ja/tai kouluttamisen korkean teknologian laatujärjestelmien kehittämiseen ja hallintaan. Tämä tarkoittaa, että Teollisuus 4.0 ja Laatu 4.0 vaativat muutosta työmarkkinoilla ja koulutettuja ja sertifioituja ammattilaisia, joilla on tarvittava osaaminen, taidot ja työvälineet (AI ja ML algoritmit) menestyä tässä uudessa ympäristössä.
Onko tällainen muutos uutta? Ei. Näin on tapahtunut modernin ajan laatuteknologiassa jo kolme neljä kertaa 20–30 vuoden välein. Edellinen murros osui 2000-luvun vaihteeseen, kun (Lean) Six Sigma -metodi tuli yleiseen tietoisuuteen. Sitä edeltänyt Laatu 2.0 murros osui 1980-luvun vaihteeseen, kun SPC ja TQM/PDSA/Deming mullistivat laadunvalvonnan (Laatu 1.0) ja syntyi laadunohjaus, joka tarkoitti, että havaintodatasta/prosessin käyttäytymisdatasta voitiin tri Walter A. Shewhartin vuonna 1931 kehittämän SPC-ohjauskortin avulla suodattaa signaali, erityissyyn olemassaolo, ja käyttää tätä stabiilisuuden ohjaukseen. Termi control (≈valvonta) sai uuden sisällön! Ei tyydytty valvomaan, tarkastamaan ja poimimaan vikoja, vaan haluttiin ohjata (≈control) virhe- ja vikatasoja alaspäin. Jotkut ehkä muistavat japanilaiset Laatupiirit (Quality Circle), joiden tavoitteena oli opettaa uuden ohjauksen (SPC, 7-tools) laatumenetelmiä työntekijöille – ongelmanratkaisua tarkastuksen ja valvonnan sijaan. Ideana oli korvata tarkastajat ongelmanratkaisuryhmillä eli laatupiireillä, jotka ratkovat erityissyitä (stabiloivat prosessia). Tarkastuksista ja valvonnasta siirryttiin ohjaukseen ja ongelmanratkaisumenetelmiin 1980-luvulla, mutta englanninkielinen termi ”control” säilyi, mutta muuttui sisällöltään valvonnasta ohjaukseksi.
Mitä näistä muutoksista on opittu? Olen ollut tekemisissä molemmissa transformaatiossa, joista olen kirjoittanut ”kokemuskirjat” /1, 2/. Laatu 2.0 muutos epäonnistui ainakin osittain. Muutos oli laadunvalvontaorganisaatioille kivulias. Osa laatuhenkilöstöstä ei koskaan hyväksynyt tarkastuksen tilalle erityissyy ohjausta (≈säätötekniikkaa) ja/tai sen alkeita ei ymmärretty. Jopa AINOA laatutekniikan ohjausväline, ohjauskortti, käännettiin SFS-standardissa väärin valvontakortiksi, vaikka olisi pitänyt olla ohjauskortti. Tehty, mikä painettu!
Google AI Mode: SFS-valvontakortti viittaa tilastollisessa prosessinohjauksessa (SPC, Statistical Process Control) käytettävään työkaluun, jonka virallinen perusta Suomessa on standardi SFS 4360:1981 (Laatutekniikka. x-R-valvontakortti).
Ohjauskortit/laatutaulut antavat hälytyksen, että erityissyy/juurisyy on mahdollisesti löydettävissä. Ongelmanratkaisu alkaa tästä hälytyksestä. Vain erityissyyn (signaalin) perusteella voi ohjata. Satunnaissyiden ohjaus johtaa vaihtelun kasvamiseen kuten Deming on osoittanut/2/. Valvonta ja ohjaus ovat täysin eri asioita ja painottavat eri asioita – toinen tarkastusta ja toinen ”säätämistä” (feedback).
Ei ihme, että muutos epäonnistui, kun käsitteetkin olivat sekaisin standardista lähtien. Aniharva yritys siirtyi erityissyiden avulla tapahtuvaan ohjaukseen, esimerkiksi Laatutaulujen käyttöön/2/. Erityissyy ja satunnaissyy käsitteitä ei ymmärretty eikä hyväksytty. Jokaiseen virheeseen ja hukkaan ajateltiin virheellisesti löytyvän juurisyy! Ei maailma näin yksinkertainen ole. Koulutus oli liian epäkonkreettista, lyhytkestoista ja työkalukeskeistä. Muitakin syitä oli. Tästä on lukuisia tieteellisiä artikkeleita/3,4/. Osin TQM/SPC:n epäonnistuminen loi pohjan ja tarpeen Six Sigmalle, joka julkistettiin Motorolan toimesta ASQ:n Dallasin laatukonferenssissa vuonna 1988. Motorola oli voittamassa USA:n ensimmäistä laatupalkintoa. Varsinainen läpimurto tapahtui kuitenkin Anaheimissä vuonna 1999 termillä ”Takaisin todellisuuteen” (Come Back to the Reality). https://sixsigma.fi/asq-laatukonferenssi/. Olin tässä ASQ-konferenssissa.
Sen sijaan Laatu 3.0:n (=Six Sigma) muutos onnistui erinomaisesti/1/. Koulutus tapahtuu käytännön projekteilla, joilla on konkreettinen yritystä ja organisaatiota hyödyttävä tavoite (reality) ja koulutuksen kesto on riittävää ja koulutettavien osaaminen varmistetaan käytännön sovellutusprojektilla (sertifikaatti). Tätä mallia on hyvä jatkaa!
Millaista osaamista tarvitaan Laatu 4.0:n käyttöönottoon ja mikä voisi olla Laatu 4.0:n sertifiointikoulutuksen pohja? Tässä artikkelissa tarkastelen vaadittuja osaamisia Laatu 4.0:ssa ja niiden kehittämistä tukevia teknologioita.
Artikkelin sisältö:
- Johdanto
- Tekoäly
- Laatu 4.0
- LQC-prosessi juurisyiden löytämiseen ja luokittelijan luomiseksi
- Vihreän, mustan ja mestari mustan vyön sertifikaatit Laatu 4.0:ssa
5.1. Keltaisen vyön (Yellow Belt) vaatimukset
5.2. Vihreän vyön (Green Belt) vaatimukset
5.3. Mustan vyön (Black Belt) vaatimukset
5.4. Mestari Mustan vyön (Master Black Belt) vaatimukset - Tiimityön tärkeys
- Esimerkit Minitab 22:n automaattisesta AutoML-algoritmin käytöstä
A. Valkoviinidata
B. Valkoviini juurisyy ja regressiomalli koneoppimis algoritmilla (perusasetukset)
C. Valkoviini luokittelumalli koneoppimis algoritmilla (perusasetukset) - Yhteenveto
- Lähteet
1. Johdanto
Organisaatioiden Laatu 4.0:n käyttöönottotasoon liittyy kaksi tärkeää käsitettä: valmius ja kypsyys. Näitä sanoja käytetään joskus rinnakkain, koska molemmat viittaavat organisaation valmiustilaan ottaa uutta teknologiaa käyttöön. Pidän kuitenkin parempana erottaa käsitteet toisistaan. Valmius on ajattelua ja ymmärrystä ja kypsyys konkreettista toimintaa. Valmius (readiness) kuvaa prosessin alkua epäilystä innostukseen ja kypsyys (maturity) viittaa innostuksesta huippuosaamisen asteisiin 1:stä 10:een.
Valmius voidaan määritellä asteeksi, jolla yritys voisi hyödyntää Laatu 4.0 -teknologioiden tarjoamia etuja. Tähän kuuluu myös halu ja paine muuttaa olemassa olevia prosesseja ja työskentelytapoja, halukkuus ottaa ”riskejä” teknologioiden soveltamisen kanssa, halu kasvattaa riittävää tietämystä teknologioista, valmius muuttua ja muuttaa omia ajatuksia. Kysymys on transformaatiosta. Valmius sisältää ymmärryksen siitä, mitä kaikkea Laatu 4.0 on (sisältää).
Lukuisat tutkijat ovat hahmotelleet ”listoja” asioista, jotka muuttuvat ja joita yrityksessä tulee muuttaa (osata). Prashar (2023)/5/ esittää laatujärjestelmän käyttöönottoa Industry 4.0 -ympäristössä kuudella ulottuvuuden, joihin muutos kohdistuu:
- Tuotanto- ja sen tukitoiminnot – kuten koneistus, kokoonpano sekä tarkastus ja testaus;
- Laadunhallinnan toimintojen laajuus – kuten laadunvarmistus ja/tai Juranin trilogia: laadun suunnittelu, laadun ohjaus, laadun parannus;
- Mahdollistavat teknologiat – erityyppiset älykkäät AI-teknologiat ja laitteet;
- Digitalisaation piilevä kyvykkyys – laatujärjestelmän digitalisoinnilla saavutettavat kyvykkyydet;
- Suorituskykymittarit – laadunhallinnan digitalisointihankkeiden suorituskyvyn arviointimittarit;
- Laadunhallinnan keskeiset periaatteet – prosessien hallinta, näyttöön perustuva päätöksenteko, johtajuus, asiakaslähtöisyys ja jatkuva parantaminen sekä työntekijöiden sitoutuminen ja suhteiden hallinta (ISO 9001).
Yhteistä näille listoille on, että Laatu 4.0 -kehyksien piirteet ovat samoja Teollisuus 4.0 -teknologioiden ja laatutyökalujen soveltaminen kanssa, kuten kokonaisvaltaisen laadunhallinnan periaatteet (TQM), laadunhallinnan 4 pilaria (varmistus, suunnittelu, ohjaus, parantaminen) ja ISO-standardit (ISO 9001 jne.).
Muutoslistoissa korostuu liiketoimintaprosessien vertikaalisen ja horisontaalisen integraation teema. Teollisuus 4.0 -kontekstissa Nolla-virhe valmistusta (ZDM, Zero Defect Manufacturing) pidetään Six Sigma -menetelmän seuraavana kehitysvaiheena. Siis halutaan parempaa laatua kuin Six Sigman < 3,4 PPM virhetaso. Laatu 4.0:ssa korostetaan ”reaaliaikaista (ennuste)ohjausta” älykkäiden anturiohjausjärjestelmien integroinnin avulla. Laatu 3.0:ssa ”ohjaus on ensi sijassa ”jälkikäteistä” ongelmien ratkaisua. Six Sigmassa korostetaan parannusprojekteja, suorituskyvyn parantamista, josta seuraa virheiden ja poikkeamien ennaltaehkäisyä.
Laatu 4.0:ssa ohjattavat asiat ennustetaan (predict, prognosis) toisin kuin nykyisin todetaan ja reagoidaan (control). Ennaltaehkäisy ja parannus ovat eri asioita, jotka tosin osittain menevät päällekkäin. Ennaltaehkäisy ja parannus vaikuttaa pidemmälle tulevaisuuteen ja perustuu suunnitteluun. Rokotus lienee ymmärrettävin allegoria ennaltaehkäisylle ja vitamiinien ottaminen on parannusta ja kipulääke on ohjausta ja antibiootti korjausta!
Valmius käsittää myös työntekijöiden halun osata ja taitaa uutta teknologiaa sekä motivaation työskennellä uusien teknologioiden kanssa (vaikka ne aluksi ovat ehkä vaikeita) ja tietysti riittävä määrä painetta (tulosvaatimuksia) ja tukea ylimmältä johdolta. Tavoitteena on parempi laatu ja tuottavuus.
Kypsyys voidaan määritellä tilaksi, jossa ollaan ”valmiita”. Valmiit myös kokeilemaan ja epäonnistumaan. Se liittyy rakennettavaan tai jo toimivaan järjestelmään kuten esimerkiksi erilaiset ”maturity” pisteytykset – Suomen Laatupalkinto, EFQM, Malcom Baldrige jne, joissa arvioidaan hyvin erilaisten laatutoimintojen tasoa.
Valmiusvaiheen ohittaminen ja suora hyppäys kypsyystilaan on suurin yksittäinen syy, miksi yritykset eivät onnistu kehittämisessä. Yliarvioidaan henkilöstön osaaminen ja tulokset ja halukkuus muutokseen ja aliarvioidaan tehtävän vaikeus. Yliarvioidaan fyysiset resurssit ja tulosten saantinopeus. Valmiudessa keskeistä on motivointi, uuden argumentointi ja pohdinta eduista ja haitoista.
Yleensä ennen argumentointia ja pohdintaa tarvitaan infoa ja koulutus, jotta argumentointi ja etujen ja haittojen analysointi ei pohjautuisi ennakkoluulojen ja virheellisten oletusten päälle kuten Laatu 2.0 osalta tapahtui – ”Valvomalla ohjaan, joten valvonta on sama asia kuin ohjaus, joten tässä ei ole mitään uutta!” Olen Laatutaulu-kirjassa/2/ kuvannut laajoja koulutuksia, joilla henkilöstö saatiin mukaan ja vastarinta ”murrettua” ja hyväksymään ero satunnaissyiden ja erityissyiden välillä ja poistamaan ja estämään erityissyyt eli stabiloimaan prosessi ja pitämään ”näpit poissa” satunnaissyistä. Laatutason parannus oli merkittävä kuten olen useilla esimerkeillä osoittanut. Samaa vaaditaan nyt Laatu 4.0:n osalta. Kun valmiudessa on päästy ensimmäisten esteiden yli, tulee osaamisen hankinta, joka on tehtävä huolellisesti ja riittävillä resursseilla.
Useasti kuitenkin halutaan nopeasti siirtyä kypsyysasteikolle ja pikakoulutuksella tuloksiin. Johtoryhmälle 2 tunnin briiffi ja muille 1–2 päivän pikakurssi ja ”lelu”demo aiheesta – ja tuottavuus ”räjähtää”! Tämä on ymmärrettävää, mutta niin tuhoisaa. Näin tehtiin 1980–90-luvuilla PDSA ja SPC-koulutuksessa. Laatu 2.0:n analyysit osoittavat, että yleinen ”pikakoulutus” ei toiminut.
Laatu 3.0:ssa, Lean Six Sigmassa – valmius luotiin huolellisesti. Kirjoitin lukuisia artikkeleita lehtiin ja sivuillemme. Löytyvät www.sixsigma.fi/artikkelit alta. Six Sigmassa koulutus kestää 4–5 viikkoa puolen vuoden aikana. Koulutus on rakennettu Six Sigma ”sertifiointi”kurssien muotoon, joihin liittyi vielä vaativa projektityö ja siihen liittyvä kirjallinen esitys (näyttö 10–50 sivua). Siis ei mikään pikku demo. Six Sigma -koulutuksen/projektin tuoton pitäisi kattaa vähintään koulutuskustannus (50.000–100.000 €/hlö). Tutkimustulokset ja analyysit todistavat, että tämä metodi toimii erityisesti silloin, kun useita henkilöitä koulutetaan samasta organisaatiosta Green Belt ja Black Belt -tasoon./1/ Tätä samaa mallia on ehdotettu Laatu 4.0:n käyttöönottoon.
Artikkelisarjalla Laatutauluista ja Laatu 4.0 olen pyrkinyt luomaan valmiuksia henkilöille ja yrityksille arvioida omaa valmiutta siirtyä tasossa ylöspäin kohti jäljitettävän havaintodatan keräämistä (traceable observational data), analysointia, mallintamista (predict) ja käyttöä ja tavoittelemaan kypsyysasteikon prosentteja. Se on mahdollista. Olen toteuttanut, johtanut, vienyt ja kulkenut rinnalla useissa läpimurtoprojekteissa vuosikymmeninen aikana. Olemme uuden tekoälyn ja koneoppimisen (LQC) äärellä.
2. Tekoäly ja laatutekniikan sovellutuksia
Tekoäly (AI) mullistaa jokaista toimialaa. Näin myös laatutoimintaa. Emme vielä tiedä kuinka ja kuinka paljon. Ensimmäiset sovellutusartikkelit on jo julkaistu ja lisää julkistetaan koko ajan. Erilaisten tutkimusten ja ennusteiden mukaan jopa yli 70 % yrityksistä soveltaa yritystoimintaan ainakin jotain tekoälyn alaluokkaa vuoteen 2030 mennessä. Nyt on korkea aika aloittaa.
Tekoälyn kuusi alaluokkaa ovat: koneoppiminen, generatiivinen tekoäly, luonnollisen kielen käsittely, konenäkö, robotiikka ja asiantuntijajärjestelmät. Nämä ovat yleisiä pääluokkia, jotka jakautuvat edelleen alaluokkiin (kuva 1). Laatutekniikan sovellutukset kattavat vasta pienen osan pääluokkia, mutta sovellutusten kattavuus kasvaa huimaa vauhtia.
Uusin laatutekniikan sovellutus on Quincy – Luotettava opas huippulaadulle, joka julkaistiin vuonna 2025. Quincy on ASQ:n tekoälyllä toimiva laajojen kielimallien (LLM) avustaja. Quincy on koulutettu yksinomaan ASQ:n omaan sisältöön ja auttaa ASQ:n jäseniä saamaan välittömiä vastauksia ja räätälöityjä ratkaisuja laatuhaasteisiinsa. Quincy on laadun 24/7-knowhow palvelu, joka tarjoaa yksilöllisiä vastauksia ja ohjausta. Se on kehitetty ASQ:n vuosikymmenten resurssien pohjalta. Kysymykset voi esittää englannin tai suomen kielellä. Vastaukset tulevat myös englannin tai suomen kielellä. Paras ja pätevin laatuteknologian AI-sovellutus. Suosittelen! Vaatii ASQ-jäsenyyden, mitä suosittelen kaikille laatuammattilaisille. Tutkittua ja varmennettua laatutietämystä!
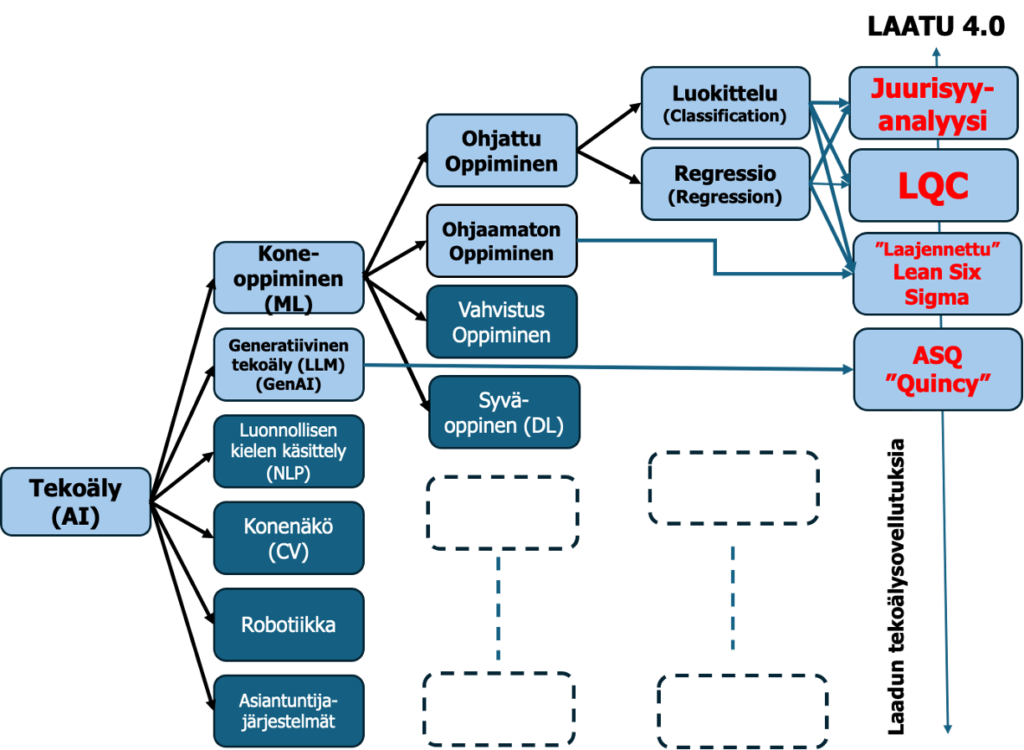
- Koneoppiminen (Machine Learning, ML): Tekoälyn alaluokka, jossa tietokonejärjestelmät oppivat ja kehittyvät kokemuksen (datan) perusteella ilman erityistä ohjelmointia.
- Syväoppiminen (Deep Learning, DL): Koneoppimisen alaluokka, joka perustuu syviin neuroverkkoihin (ihmisaivojen toimintaa jäljitteleviin malleihin) ja kykenee käsittelemään monimutkaista tietoa, kuten kuvia ja puhetta.
- Generatiivinen tekoäly (GenAI): Tekoäly, joka luo uutta sisältöä (tekstiä, kuvia, musiikkia, koodia) opetusdatansa perusteella. Esim. kielimallit ChatGPT (OpenAI), Copilot (Microsoft), Gemini (Google) ja kuvageneraattorit Adobe Firefly, Midjourney, DALL-E.
- Luonnollisen kielen käsittely (Natural Language Processing, NLP): Mahdollistaa tietokoneiden ymmärtää, tulkita ja tuottaa ihmiskieltä.
- Konenäkö (Computer Vision, CV): Tekniikka, jonka avulla tekoäly voi ”nähdä” ja analysoida visuaalista tietoa (kuvia ja videoita).
- Robotiikka (Robotics): Yhdistää tekoälyn mekaanisiin laitteisiin, jolloin robotit voivat toimia itsenäisesti tai puoli-itsenäisesti.
- Asiantuntijajärjestelmät (Expert Systems): Sääntöpohjaisia järjestelmiä, jotka matkivat ihmisasiantuntijan päätöksentekoa tietyllä kapealla alueella.
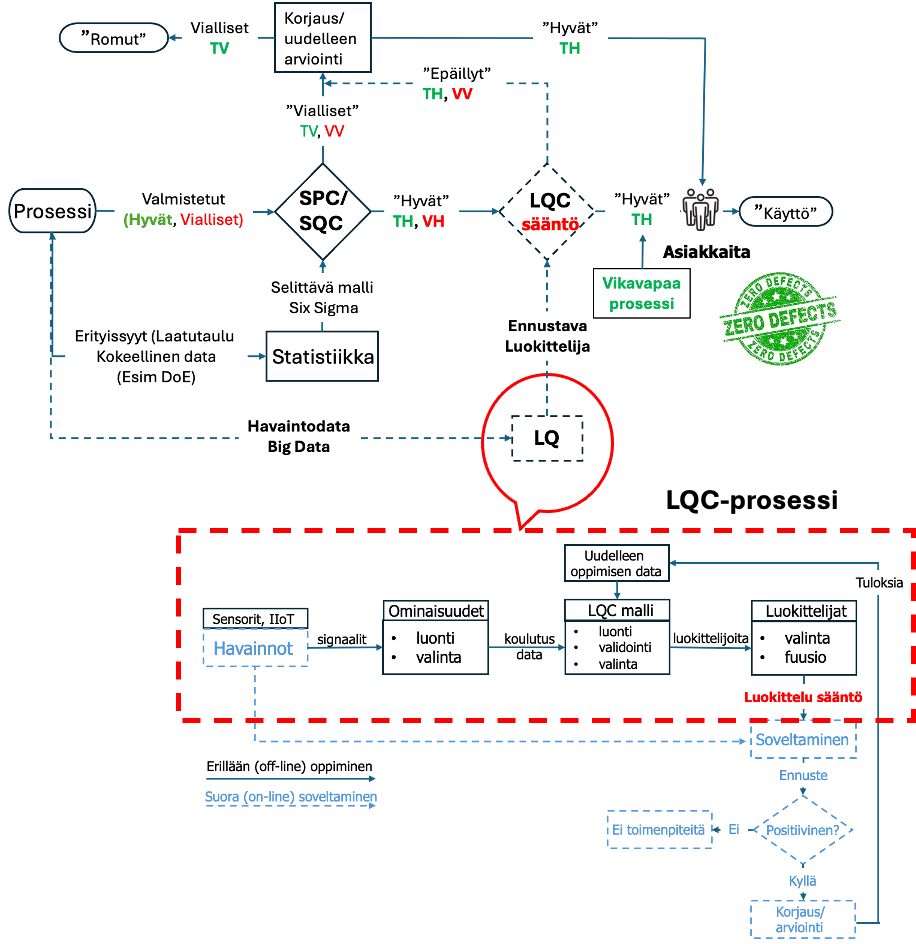
Laatu 4.0:ään tullaan soveltamaan seuraavien vuosien kuluessa lukuisia näistä luokista. Yksi ensimmäisistä tekoälyn konkreettisista laatuteknisistä sovellutuksista on koneoppimisen luokittelu- (classification), juurisyyanalyysit ja Lean Six Sigma analyysivaiheen laajennus. Miksi juuri luokittelu, juurisyy ja Six Sigma laajennus?
Luokittelussa/tarkastuksessa tapahtuu yritysten suurimmat ja kalleimmat laadun piilovirheet ja hukat, jotka menevät läpi aina asiakkaille saakka. Luokittelun/tarkastuksen suorituskykyä ei yleisesti tunneta. Uskotaan, että suorituskyky on 100 % (α ja β -virhe =0) ja että kaikki virheet ja viat löydetään tarkastamalla! Kuitenkin useimmissa tarkastustehtävissä havaitsematta jääneiden virheiden ja vikojen määrä vaihtelee tyypillisesti 20 %:sta 30 %:iin ja jopa 70 % asti. Tämä on menetettyä tehokkuutta ja tuottavuutta. Tekoäly pystyy luokittelemaan (ennustamaan) luokat huomattavasti paremmin so. virheettömämmin, kuin tarkastaja, mutta ei täydellisesti! Yhdistettynä laatutauluun (SPC) teho vain kasvaa ja prosessi stabiloituu – ennustettavuus kasvaa.
Luokittelu ja sen onnistuminen on yksi tärkeimmistä ja keskeisistä tieteen ja tutkimuksen menetelmistä – alkuaineet on luokiteltu, kasvit ja eläimet on luokiteltu, sairaudet ja taudit on luokiteltu, genomin analyysi (DNA) on luokittelua. Oikeuslaitos luokittelee – ja tuomitsee – syylliset toivottavasti oikein. Oikeastaan ”kaikki” on luokiteltua erilaisiin ryhmiin! Onko luokittelu tehty oikein ja voisiko sitä parantaa? Voisiko luokittelun tehdä ennusteperusteisesti etukäteen ja tehdä toimenpiteet ennen ei-toivottua tapahtumaa vai joudummeko tyytymään tapahtuman jälkeiseen luokitteluun ja sitä seuraavaan virheiden valvontaan (control). Tekoälyn ja koneoppimisen algoritmi tuo lähes automaattisesti luokitteluun johtaneet syyt näkyviin, kun taas ihmisen tekemä luokittelu on pitkälti intuitiivista ”syyn peittävää”. Algoritmien paljastamat syyt ovat (ehkä) juurisyitä, joita voi parantaa tai ohjata (control), että viat/virheet eivät toistu. Tämä pätee myös Six Sigman analyysivaiheeseen.
Laatufunktio (organisaatio) luokittelee/tarkastaa palvelut ja tuotteet ja näiden osakomponentit hyviin ja huonoihin (vialliset, virheelliset) jälkikäteen. Luokittelu on laatufunktion primääri tehtävä. Tätä tointa, prosessia kutsutaan, tarkastukseksi (inspection). Tarkastuksen totutus yrityksissä vaihtelee työntekijöiden suorittamasta omavalvonnasta erillisiin tarkastusorganisaatioihin (itsenäinen laadunvalvonta). Tarkastus ja lajittelu on perinteistä SQC/SPC-teknologiaa, jossa luokittelu perustuu suunnittelun asettamiin vaatimuksiin/toleransseihin ja prosessin asettamaan stabiilisuusvaatimukseen (erityissyy/satunnaissyy)!
Tarkastuksen tuloksen – luokittelun – oikeellisuus on keskeistä. Oikeellisuutta kuvataan sekaannusmatriisilla (confusion matrix) ja α- ja β -virheillä. Tilastomatematiikassa tätä kutsutaan luokitteluvirhetaulukoksi. Käsittelin luokittelun virheitä, sekaannusmatriisia, edellisessä artikkelissa. Tarkastuksen luokitteluvirheen, ”mittausvirheen”, α- ja β -määrittely on työlästä. (Menettelyn perusteet opetetaan Lean Six Sigma -kurssilla MSA:n yhteydessä).
Tarkastuksen luokittelun tasosta kertoo esimerkiksi ydinaseiden komponenttien tarkastustulos vuodelta 2015/6/. Yhdysvaltain ydinturvallisuusviraston (U.S. Nuclear Security Enterprise) 82 tarkastajaa tarkasti 140 osaa 8 eri vian osalta. Tarkastajat hylkäsivät virheellisesti 35 % hyväksyttävistä osista (α-virhe 35 %) ja oikein 85 % viallisista osista (β-virhe 15 %).
Tarkemmin tarkastuksesta lähteessä/7/, jossa on annettuna yhteenveto visuaalisen tarkastuksen tuloksista (kuva 2) ja korjausmahdollisuuksista. Ylisummaan tarkastusta, tapahtuu se visuallisesti tai mittalaitteella, on erittäin vaikea parantaa perinteisin menetelmin. Jokainen Six Sigma -kurssin käynyt tämän tietää. Perinteisen tarkastuksen/lajittelun 100 % oikeellisuus on syvään juurtunut myytti, jolle ei ole mitään perusteita! Oikea luku voisi olla 70–80 %, jos sitäkään.

Osassa 2 kerroin Chevrolet Voltan akkuliitosten tarkastuksesta luokittelijanvalinnasta. Taulukon 4 mukaan luokittelijan C1α-virhe 0,3 % ja β-virhe 11 %. Luokittelijan kyvykkyys on paljon parempi kuin tarkastajan.
Tässä artikkelissa keskitytään ensi sijassa koneoppimiseen mahdollistavaan luokitteluun ja sen kehitysprosessiin LQC, jota esiteltiin tarkemmin edellisessä artikkelissa (Koneoppimisesta (ML) ja Laatutaulusta (SPC) – Osa 1; Laatu 4.0 – Oppivalla laadunohjauksella (LQC) parempaan laatuun – Osa 2; Laatu 4.0 – Havaintodata ja sen analysointi – Oppiva Laadun Ohjaus-prosessi (LQC) – Osa 3). Tämä siksi, että LQC:ssa esitetty prosessi Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen kattaa datan luonnista sen lopulliseen käyttöön. Sama ongelmanratkaisuprosessi toistuu myös muissa tekoälyn soveltamisprosesseissa. Kuvassa 1 esitetyt sovellutukset, Juurisyyanalyysi ja Laajennettu Lean Six Sigma/5/, ovat koneoppimisen osajärjestelmiä.
Tekoälyn yleisenä tavoitteena on luoda teknologioita, jotka täydentävät ihmisen älykkyyttä tai ottavat haltuunsa tylsät, yksitoikkoiset, riskialttiit, nöyryyttävät ja epäinhimillistävät työt. Nämä teknologiat on ohjelmoitu käsittelemään tilanteita itsenäisesti ilman ihmisen puuttumista asiaan.
Koneoppiminen on siis tekoälyn haara, joka antaa koneille taidot oppia esimerkeistä (havaintodatasta) ilman, että niitä ohjelmoidaan erikseen. Koneoppimisalgoritmilla (MLA) on keskeinen rooli tekoälyn rakenteessa. Lähes kaikista tilastosoftista (Minitab, Matlab, SPSS) löytyy keskeiset MLA algoritmit Predective-valikon tai vastaavan alta.
On huomattava, että kaikki tekoälysovellutukset antavat ennusteen (predict, prediction, prognosis) muodossa tai toisessa. Äly tulee siitä, että ennuste on parempi (nopeampi) kuin yksittäinen ihminen tai yritys voi luoda ”juuri tässä hetkessä”. Ennuste perustuu laskentaan ja laskennassa käytettyihin sääntöihin. Laskenta algoritmit muuttavat big datan älykkäämmiksi ”itseoppimisen” kautta ilman ihmisen puuttumista asiaan, so. laskutoimitukseen. Itseoppiminen on vähän kyseenalainen termi. Kyllä kaikki laskenta- ja logiikkasäännöt on ihminen asettanut! MLA ”oppii” automaattisesti malleja olettamatta todennäköisyysjakaumaa tai ennalta määritettyä mallimuotoa. Yksinkertaisia algoritmeja käytetään yksinkertaisissa sovelluksissa, kun taas monimutkaisemmat auttavat ratkaisemaan monimutkaisia tekoälyongelmia. Osassa 1 Koneoppimisesta (ML) ja Laatutaulusta (SPC) esittelin Minitabin algoritmit ja niiden käyttöä.
3. Laatu 4.0
Teollisuus 4.0 ja Laatu 4.0 on uusi teknologia, joka hämmentää yrityksiä ja niiden laatuorganisaatioita. Miten suhtautua tekoälyyn ja koneoppimiseen? Mitä hyötyä tästä olisi yrityksen tuotteiden ja palveluiden laadulle ja paljonko mahdollinen hanke maksaisi, voisiko se olla kannattava? Onko ryhdyttävä toimenpiteisiin? Kuinka edetä? Yritykset pyrkivät kasvattamaan valmiuksia täydestä epävarmuudesta varmuuteen.
Merkittävällä osalla yritys- ja laatujohtajista ei ole vielä selkeää käyttöönottostrategiaa ja kohdetta. He ovat valmiusvaiheessa jossain 0–100 % välissä. Laatuhenkilöillä on ehkä vaikeuksia perustella yritysjohdolle, mistä tekoälyteknologiasta pitäisi aloittaa, mitä työkaluja ja osaamista on hankittava, mitä hyötyä tekoälystä saadaan ja kuinka uusia teknologioiden valjastetaan käyttöön. Tilanne on pitkälti sama, kuin 1980-luvulla SPC:n tullessa ja 2000-luvun alussa Six Sigman kanssa. Voisiko näistä transformaatioista oppia jotain?
Tilannetta voi tarkastella lukuisten kirjoittamieni Six Sigma -artikkelieni (https://sixsigma.fi) ja Lean Six Sigma 2.0 -kirjan/1/ ja Laatutaulu -kirjan/2/ avulla. Näin silloin edettiin ja viestittiin. Six Sigman osalta epäilijöitä oli paljon ja <3,4 PPM tavoitteelle ”naureskeltiin”. Six Sigman idea oli hyvä, mutta osaaminen ja henkilöiden puute oli ja on yksi suurimmista haasteista. Kuinka tämä ratkaistaan? Vastauskin on yksinkertainen – varataan ja koulutetaan tarvittavat resurssit? Mitä koulutetaan?
Investoiminen koulutukseen on strategisesti tärkeää, jotta (valmistus/palvelu) yritys voi luoda lisäarvoa tekoälyllä – datalla ja koneoppimisella. Millainen koulutus? Six Sigmasta 20 vuoden ajalta saadut erinomaiset kokemukset tarjoavat todistetusti toimivan datapohjaisen polun, jota kannattaa seurata.
Tässä artikkelissa esitetään sertifiointiperusteista ML-opetussuunnitelmaa Green, Black ja Master Black Belt -valmentajille. Sertifiointi on muodollinen prosessi, jolla tunnistetaan henkilö, joka on saavuttanut pätevyyden (koulutus, teoria, tieto ja taito, kokemus) tietyllä alueella. Sertifiointiprosessin aikana hankittu osaaminen erottaa sertifioidut insinöörit/osaajat muista. Laatupuolella Amerikan laatuyhdistys (ASQ) tarjoaa hyvin laajan kirjon sertifiointiohjelmia. Kaikki ASQ:n sertifiointiohjelmat ovat tulleet Laatu 3.0 myötä. Tekoälystä (Laatu 4.0) ei vielä ole ASQ:n sertifiointivaatimuksia BOK:a (The Body of Knowlwdge), sertifiointikoulutusta ja sertifikaattia, mutta odotettavissa on, että ohjelma syntyy pian ja ehkä myös ISO-standardi, kuten Six Sigmasta. ASQ:lla on Laatu 4.0 -ohjelma/aloite käynnissä.
Tri Carlos Escobarin esittämä Laatu 4.0:aan opetussuunnitelma/8,10/, joka yhdistää kuusi osaamisaluetta: tilastotiede, laatu, valmistus, ohjelmointi, oppiminen ja optimointi. Nämä alueet sekä 5-vaiheinen ongelmanratkaisustrategia on hallittava sertifikaatin saamiseksi.
Sertifioidut ammattilaiset ovat niitä, jotka ottavat ensimmäisenä käyttöön Laatu 4.0 -teknologioita ja -strategioita. Heillä on kyky tunnistaa koneoppimisongelmiin liittyviä teknologisia ja ratkaistavissa olevia ongelmia.
4. LQC-prosessi juurisyiden löytämiseen ja luokittelijan luomiseksi (kertaus)
LQC ongelmanratkaisu voidaan kuvata viidellä vaiheella – Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen tai yksityiskohtaisemmin 7-vaiheella – Tunnista, Aavista (havaitse), Löydä data, Opi datasta, Ennusta, Suunnittele uudelleen, Opi uudelleen; Identify, Acsensorize (Observe), Discover Data, Learn Data, Predict, ReDesign, ReLearn (IADLPR2). Huom: Joissain uusimmissa artikkeleissa LQC:sta käytetään myös lyhennettä PQM, Predict Quality Management.
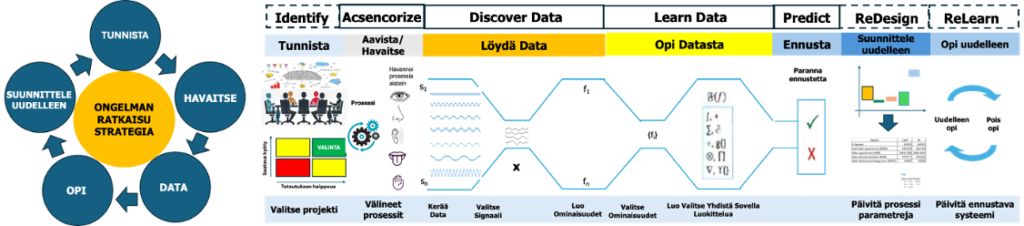
Kuinka luodaan koneoppimisperusteinen AI-malli jäljitettävästä havaintodatasta (LQC):
- Tunnistaminen – monimutkaisten teknisten ongelmien tunnistaminen. Tämän vaiheen ensisijainen tavoite on arvioida jokainen potentiaalinen projekti ja valita niistä arvokkaita monimutkaisia teknisiä ongelmia. Ensin kutakin projektia arvioidaan 18 kysymyksen perusteella/8/. Tämän jälkeen arvioidaan potentiaalisia projekteja datan saatavuuden, liiketoiminta-arvon ja onnistumismahdollisuuksien perusteella. Lopuksi, kun projekti on valittu, oppimistavoitteet on määriteltävä alfa- ja betavirheiden avulla toteutettavuuden arvioimiseksi.
- Havaitseminen, akserointi – prosessi, jossa käytetään kameroita ja älykkäitä antureita raakadatan tuottamiseksi.Tämän vaiheen ensisijainen tavoite on tarkkailla (eli ottaa käyttöön kameroita tai sensoreita) prosessia, jolla tuotetaan raakaa empiiristä dataa järjestelmän valvontaa varten (traceable observational data).
- Data, koulutusdatan löytäminen – jäljitettävän empiirisen datan muuntamiseksi ominaisuuksiksi ja tunnisteiden (label) antamiseksi kullekin näytteelle. Tämän vaiheen ensisijainen tavoite on luoda koulutusdataa eli luoda/muuntaa ominaisuuksista raakadataa ja nimetä jokainen näyte.
- Oppiminen – datan esikäsittelytekniikoiden oppiminen ja käyttäminen. Tämän vaiheen ensisijainen tavoite on suunnitella malli (esim. juurisyy, luokittelija) käyttämällä Big Models-oppimisparadigmaa. Tämä vaihe sisältää esikäsittelytekniikoita, esim. poikkeavien arvojen havaitseminen (erityissyyt, SPC), normalisointi/standardointi, ominaisuuksien valinta, imputoinnit, muunnokset jne.
- Ennustus – useiden eri ML-algoritmien, perusteella etsitty optimiennuste (predict). Minitab-ohjelmassa on automatisoitu mallin haku. Tämän vaiheen ensisijainen tavoite on kehittää ML-algoritmeja ennustamisen optimoimiseksi eli parantaa parhaiten suoriutuvaa mallia. On huomattava, että ennuste on välitön koskien esim. seuraavaa palvelua tai tuotetta.
- Uudelleensuunnittelu – tiedon louhinnan tuloksista saatavan teknisen tiedon tarjoaminen. Tämän vaiheen ensisijainen tavoite on kerätä ja jalostaa teknistä tietoa tiedonlouhinnan tuloksista. Poimittua tietoa käytetään tuotteen ominaisuuksien ja laadun välisistä mahdollisista yhteyksistä, joista luodaan uusia hypoteeseja esimerkiksi juurisyistä, joilla voidaan parantaa edelleen korrelaatio- ja kausaalimalleja. Tilastollisia analyysejä (DoE) voidaan suunnitella syy-seuraussuhteen selvittämiseksi, juurisyyanalyysien täydentämiseksi ja tunnistamiseksi sekä optimaalisten parametrien tunnistamiseksi prosessin uudelleensuunnittelua varten.
- Uudelleenoppiminen – sen määrittämiseksi, miten dataa generoidaan ja kuinka usein ML-algoritmit koulutetaan uudelleen. Tämän vaiheen päätavoite on kehittää uudelleenoppimisstrategia, jolla malli oppii luokkien uudet tilastolliset jakaumat. Konekielisessä oppimisessa tätä kutsutaan ”ajautumisen” käsitteeksi. Korrelaatiomallille tyypillistä on, että se on voimassa välittömästi, mutta ajan mittaan ajautuu ”virheelliseksi”. Tässä vaiheessa määritetään, miten uudelleenkoulutusdata luodaan ja kuinka usein mallia koulutetaan uudelleen. Tyypillisesti laitoksen dynamiikka otetaan huomioon uudelleenoppimisstrategiaa kehitettäessä.
5. Vihreän, mustan ja mestari mustan vyön sertifikaatit Laatu 4.0:ssa
Laatu 4.0 perustuu aiempien filosofioiden tilastollisiin ja johtamiseen perustuviin perusteisiin ja täydentää ja laajentaa näitä Teollisuus 4.0 tarpeiden mukaisesti. Se noudattaa myös ongelmanratkaisuparadigmaa (LQC), joka edistää systemaattisesti innovaatioita ja parantamista. Uusi opetussuunnitelma ei kuitenkaan perustu pelkästään perinteiseen tilastotieteeseen, vaan sitä on päivitetty koneoppimisella, optimoinnilla ja tietokoneohjelmoinnilla, joita ei aikaisemmissa tilasto- ja johtamismenetelmissä ollut.
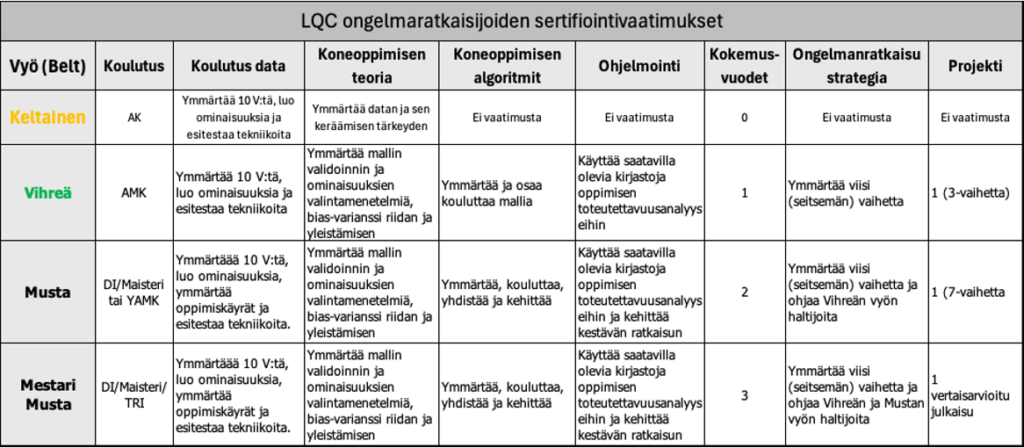
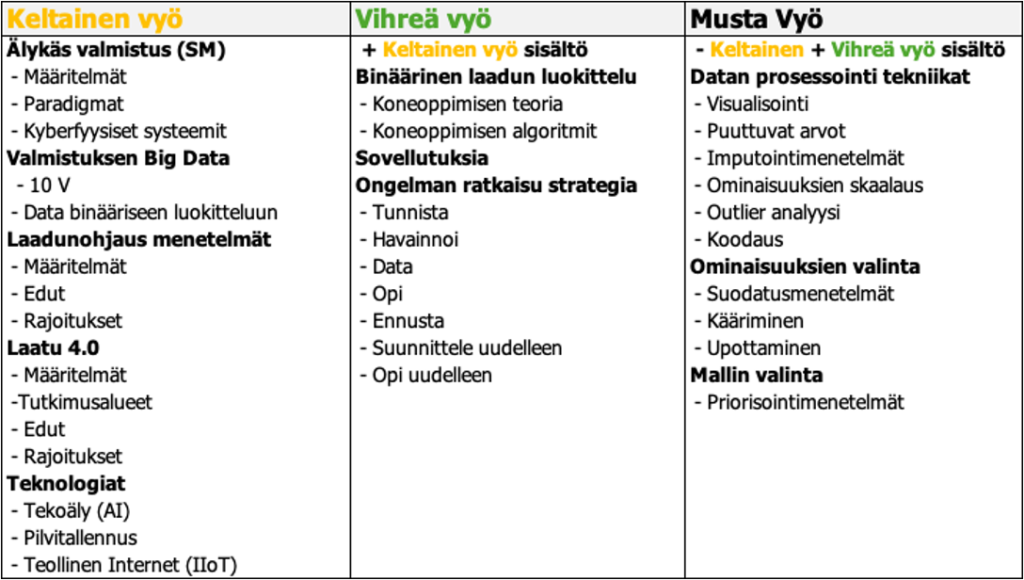
Alkuperäisen Six Sigma -väritunnuksia noudattaen Laatu 4.0 -sertifikaateille on tunnistettu neljä eri osaamistasoa: keltainen, vihreä ja musta vyö ja mestari musta vyö. Jokainen väri vaatii erilaisia tiedon, koulutuksen ja kokemuksen tasoja, kuten taulukossa 1 on kuvattu.
Taulukko1. LQC ongelmaratkaisijoiden sertifikaattivaatimukset/9,10/.
5.1. Keltaisen vyön (Yellow Belt) vaatimukset/8, 10/
Keltaisen vyön opetussuunnitelma auttaa laatualan ammattilaisia ymmärtämään älykkään valmistuksen ja L4.0:n uudet paradigmat, määritelmät ja rakennus ”palikat”. Se tarjoaa yleiskatsauksen perinteisten laatujärjestelmien ja L4.0-menetelmien eroista kuin myös niiden samankaltaisuudesta. Vaikeinta lienee hyväksyä ennusteperusteinen toiminta jälkikäteisen reagoinnin sijaan. Vastaavan tyyppinen ongelma oli Laatu 2.0 osalta. Tarkastajan oli vaikea hyväksyä tarkastuksen täydentäminen ja korvaaminen erityissyyvirheiden luokittelun periaatteella (± 3 sigma) ja ongelmanratkaisulla (ennaltaehkäisy).
5.2. Vihreän vyön (Green Belt) vaatimukset/8, 10/
Vihreän vyön sertifikaatin haltijalla olisi oltava luonnontieteiden, teknologian, tekniikan tai matematiikan tutkinto ja vähintään vuoden kokemus datan käsittelystä esim. Six Sigmasta. Henkilön tulisi ymmärtää Big Datan 10V-periaatteiden merkitys ja seuraukset. Kaikki nämä ovat keskeisiä datatieteissä
10 V:tä on:
- Koko (Volume) on luotavan datan koko – 100 vai 10 000.
- Nopeus (Velocity) kuvaa sitä, kuinka nopeasti data on luotava, käytettävä ja käsiteltävä ennustamista varten. Laatu 4.0 -aloite vaatii lähes reaaliaikaista nopeutta.
- Vaihtoehdot (Variety) määritellään eri tietolähteiden (videot, kuvat, ääni tai signaalit) analysoinniksi.
- Todenmukaisuus (Verasity) on datan luotettavuus.
- Vaihtelu (Variability) viittaa valmistusjärjestelmien dynaamiseen luonteeseen.
- Visualisointi (Visualization) tarkoittaa sitä, miten tiedonlouhinnan tulokset tiivistetään ja käytetään johdon päätöksenteossa.
- Verifiointi (Verification) on tapa, jolla mallit validoidaan.
- Valppaus (Vigilance) viittaa strategiaan, joka on kehitettävä vaihteluominaisuuden käsittelemiseksi; oppimis-, uudelleenoppimis- ja unohtamismalli.
- Tyhjiö (Void) on tehtaan/yksikön dynamiikasta johtuva taipumus, että data sisältää useita tyhjiä valmistuksesta johdettuja datatietueita.
- Arvo (Value) vastaa Laatu 4.0 -projektin arvon ymmärtämisen ydintä ennen sen osoittamista datatiimille.
Hänen on tiedettävä, miten datasta (≈ kohina + signaali) erotellaan signaaleja tai kuvista luodaan ominaisuuksia. Hänen on myös ymmärrettävä, miten esikäsittelytekniikoita käytetään ja sovelletaan tehokkaasti epätäydellisten tietojoukkojen ja eri teknisten mittakaavoissa olevien menetelmien käsittelyyn. Vihreän vyön haltijan on myös osoitettava ymmärrys koneoppimisen perusteoriasta, mukaan lukien: mallin validointi- ja ominaisuuksien valintamenetelmät, bias-varianssi-kompromissi ja yleistysarvioinnin metriikat. Hänen on kyettävä kouluttamaan koneoppimisen algoritmeja. Hänen on ymmärrettävä jokainen ongelmanratkaisustrategian viidestä/seitsemästä vaiheesta, jotta hän voi osallistua osittain koko ratkaisujaksoon. Hänen on dokumentoitava projekti osoittaakseen kykynsä soveltaa onnistuneesti ainakin kolmea ongelmanratkaisustrategian vaihetta. Green Belt suorittaa datan luonnin ja alustavat toteutettavuusanalyysit.
5.3. Mustan vyön (Black Belt) vaatimukset/8, 10/
Mustat vyön haltija on tekniikkaosaava ja kykenevä kehittämään kestävän ratkaisun yhteistyössä eri toimintojen tiimin kanssa. Vihreän vyön haltijan vaatimusten lisäksi Mustan vyön haltijat ymmärtävät oppimiskäyrät, jotka ohjaavat tiedon tuottamista – joko enemmän dataa tai enemmän ominaisuuksia tai molempia – varianssi- bias kompromissi. Heidän on kyettävä optimoimaan ennustamista päätösten yhdistämisjärjestelmän avulla. Heidän tulisi olla taitavia kirjoittamaan koodia – oppimaan ja uudelleenoppimaan, jos käytettävät softat ja ML-algoritmit sitä vaativat. Mustan vyön haltijat kykenevät tunnistamaan järjestelmän ohjaavat ominaisuudet prosessien uudelleensuunnittelun/optimoinnin ohjaamiseksi ja ihmisälyn lisäämiseksi (eli vianetsintäprosessien). Heillä on oltava vähintään kahden vuoden kokemus datan käsittelyssä ja heidän on dokumentoitava ongelmanratkaisuteorian seitsemän vaiheen soveltaminen.
Ennen sertifikaattia on valmistava koulutus ja harjoitustyö. Seuraavassa taulukossa 2 alustava koulutusohjelman sisältö keltaisen, vihreän ja mustan vyön koulutettaville:
Taulukko 2. Keltaisen (Yellow), vihreän (Green) ja mustan (Black) vyön koulutus/10/
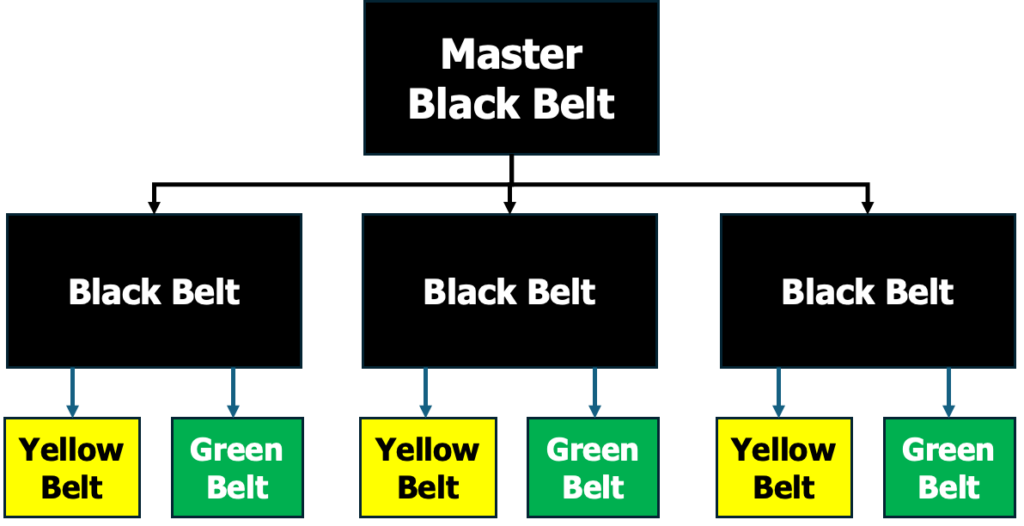
5.4. Mestari Mustan vyön (Master Black Belt) vaatimukset/8, 10/
Mestari mustan vyön haltijat toimivat mustan vyön haltijoiden ohjaajina ja eri toimintojen tiimien mentoreina ja toimivat siltana mustan vyön haltijan ja organisaation johdon välillä. He ovat ”tunnistusvaiheen” johtajia, joten he varmistavat, että datatiimit työskentelevät vaikuttavien/arvokkaiden projektien parissa, joilla on suuri onnistumisen todennäköisyys. He vastaavat, että tuloksia syntyy. Master Black Belt -sertifioitujen on kyettävä kirjoittamaan uusia algoritmeja ja kirjastoja ratkaisujen mukauttamiseksi. Tämän taidon osoittamiseksi on julkaistava yksi vertaisarvioitu artikkeli AI-, IBD- (Industrial Big Data) tai Quality 4.0 -alueella. Master Black Belt -sertifioidulla on oltava vähintään kolmen vuoden kokemus sekä Green ja Black Belt -sertifikaatit.
Kuvassa esitettynä Laatu 4.0:n vöiden hierarkia.
6. Tiimityön tärkeys/8, 10/
Black Belt- ja Master Black Belt -osaajat ottavat keskeisiä henkilöitä oikeiden ongelmien valinnassa ja ratkaisemisessa. Laatu 4.0 sisältää lukuisia osaamisalueita, joihin tarvitaan erityisosaamista. Siksi on tärkeää, että L4.0-tiimillä on oikeat taidot, jotta aloite voidaan toteuttaa onnistuneesti.
Tässä joitain kriittisiä tiimiläisten osaamisalueita ja panoksia.
- Master Black Belt – johtaja, joka yhdistää liiketoimintavision L4.0-aloitteeseen.
- Black Belt – insinööri, joka ratkaisee kunkin projektin tekniset näkökohdat
(esim. kouluttaa luokittelijaa).
- Prosessin tuntija – insinööri, jolla on perustiedot valmistusprosessista (esim. hitsausprosessi, palveluprosessi). Tämä tieto varmistaa, että asiaankuuluvat tiedot (esim. signaalit) luodaan. Hän validoi mallit insinööritieteen näkökulmasta. Tätä tietoa käytetään myös datalähtöisten havaintojen yhdistämiseen insinööritieteisiin prosessin uudelleensuunnittelua varten.
- Data asiantuntija/insinööri – insinööri, joka osaa muokata reaalimaailman mittauksista digitalisoituja muotoja, kuten videosta, äänestä, paineesta, kosteudesta tai lämpötilasta, ja muuntaa niitä ja luoda ominaisuuksiksi, jota niitä ML algoritmit voivat käyttää.
- Data-insinööri – valmistelee ja järjestää datan tietokantoihin ja muihin formaatteihin. He valmistelevat datan Black Beltille kehittämällä, testaamalla ja ylläpitämällä datatietueita ja data-arkkitehtuureja. Black Belt voi keskittyä innovaation ydinongelman eli oikean ja luotettavan mallin luomiseen.
- Koneoppimisoperaatiot (MLOp) työskentelevät koneoppimisratkaisun automatisoinnin ja käyttöönoton parissa maantieteellisesti hajallaan olevissa tehtaissa.
Ei ole olemassa universaalia ja parasta ML-tiimiä. Tiimiltä vaadittavat osaamiset voivat vaihdella projektin mukaan. Jotkut projektit ovat yksinkertaisia ja toiset hyvinkin monimutkaisia ja vaativat laajan osaamispohjan.
7. Esimerkit Minitab 22:n automaattisesta ML-algoritmin käytöstä
Minitab 22:ssa on automaattinen ja helppokäyttöinen Predictive Analytics Module/12/, jolla voi helposti tehdä ja valita koneoppimismallin (ML-algoritmi). Moduuli sisältää automatisoidun koneoppimisen (AutoML) ja patentoidut puupohjaiset algoritmit. AutoML sovittaa datan ja vertaa automaattisesti useita malleja toisiinsa (kuten Random Forests, TreeNet ja CART) ja suosittelee ”parasta” valintaa. Jotta voit käyttää mallia, tarvitset datan, jossa on ennustajat (inputs, x) ja vaste (output, Y). Kuvassa 6 datarakenne. Rivejä voi olla muutamasta kymmenestä tuhansiin.

Pikaohje Minitab Predictive Analytics Module/12/
1. Avaa analyysityökalu (Minitab 22)
Siirry ylävalikkoon ja valitse Predictive Analytics Module. Valitse pudotusvalikosta Automated Machine Learning. Sinun on sitten valittava versio, joka vastaa vasteen (output, Y) datatyyppiä. Joko Jatkuva tai binääri.
- Jatkuva: Discover Best Model (Continuous Response): Käytä tätä, jos kohteena on numero (esim. hinta, paino tai lämpötila).
- Binääri: Discover Best Model (Binary Response): Käytä tätä, jos kohteena on vain kaksi lopputulosta (esim. hyväksytty/hylätty; kyllä/ei tai 1, 0).
2. Määritä muuttujat (inputs x, output Y)
Määritä näkyviin tulevassa valintaikkunassa, miten Minitabin tulisi käsitellä dataasi:
- Response (Target Y): Syötä sarake, jonka haluat ennustaa. Kuvassa 4 C12
- Continuous Predictors (x): Syötä kaikki numeeriset muuttujat (esim. ikä, verenpaine). Kuvassa 4 C1-C11
- Categorical Predictors (x): Syötä muuttujat, joilla on erilliset ryhmät tai tunnisteet (esim. siviilisääty, työvuoro). Kuvan 4 datoissa ei ole luokiteltuja muuttujia!
3. Määritä validointi ja asetukset (valinnainen, voit ”hypätä” yli)
Validation välilehdestä voit määrittää, miten Minitabin tulisi testata mallin tarkkuutta. Minitab valitsee automaattisesti, jos et muuta asetuksia.
Yleisiä menetelmiä ovat:
- K-fold Cross-validation: Datan jakaminen useisiin ”taitoksiin” sen varmistamiseksi, että malli ei vain opi koulutusdatasta.
- Validation with a test set: Käytetään erillistä osaa datastasi (esim. 20 %) sen määrittelemiseksi, kuinka hyvin malli ennustaa uutta, ennennäkemätöntä dataa.
4. Suorita ja tunnista ”paras” malli
Napsauta OK. Minitab käy läpi (laskee) useita algoritmeja samanaikaisesti ja näyttää mallin Model Selection taulukossa.
- The Winner: Minitab korostaa automaattisesti parhaiten toimivan mallin kriteerien, kuten R-neliön (jatkuvalle) tai ROC-käyrän alle jäävän pinta-alan (binääriselle), perusteella.
- Switching Models: Jos haluat yksinkertaisemman mallin (kuten yhden CART-puun) monimutkaisen mallin (kuten TreeNetin) sijaan, voit valita sen luettelosta nähdäksesi sen tarkat tulokset.
5. Ennusta (predict) uusia tuloksia
Kun olet tunnistanut parhaan mallisi, voit käyttää sitä todellisten ennusteiden tekemiseen:
- Napsauta tulosikkunassa yläreunassa olevaa Predict nappulaa.
- Syötä ennustajien arvot (esim. tietyn asiakkaan ikä ja ostohistoria tai valkoviinin ominaisuudet).
- Minitab antaa Predicted Response arvon sekä luottamusvälit.
Seuraavassa parilla esimerkillä esittelen ML-mallin luontia ja analysointia. Dataa ja malleja ei ole yksinkertaisuuden vuoksi ”työstetty” ja optimoitu. Tällä esimerkillä on ensi sijassa valaistu ML-algoritmin käyttöä (ei ensi oikean ja optimin valkoviinin ennustamista, joka vaatisi enemmän tietoa prosessista).
A. Valkoviini data
Tämän esimerkin tarkoituksena on valaista regressio ja luokittelijan koneoppimisalgoritmien käyttöä. Käytettävät algoritmit löytyvät Minitab Predictive -valikon alta.
Käytettävä data löytyy linkistä https://www.kaggle.com/datasets/piyushagni5/white-wine-quality cvs-tiedostomuodossa. Datassa ei ole järjestys ja päivämäärädataa, joten datan/prosessin stabiilisuutta ei voi luotettavasti analysoida. (Saat datan myös eero@qkk.fi tai toimisto@qkk.fi Excel ja Minitab mwx. muodossa, jos linkistä nouto/muuntaminen ei onnistu.)
Datan konteksti
Tämä aineisto liittyy portugalilaisen ”Vinho Verde” -viinin puna- ja valkoviinivariantteihin. Lisätietoja on julkaisussa/13/. Tietosuoja- ja logististen syiden vuoksi saatavilla on vain fysikaaliskemiallisia (inputit (x)) ja aistinvaraisia (output, Y) muuttujia (esim. ei ole tietoa rypäletyypeistä, viinimerkistä, viinin myyntihinnasta jne.).
Tätä aineistoa voidaan pitää luokittelu- tai regressiotehtävänä. Luokat ovat järjestettyjä eivätkä tasapainotettuja (esim. normaaleja viinejä on paljon enemmän kuin erinomaisia tai huonoja). Poikkeavien arvojen havaitsemisalgoritmeja voitaisiin käyttää muutamien erinomaisten tai huonojen viinien havaitsemiseen. Ei myöskään voida olla varmoja, ovatko kaikki syöttömuuttujat relevantteja, joten voisi olla mielenkiintoista testata ominaisuuksien valintamenetelmiä.
Sisältö
Lisätietoja on julkaisussa [Cortez et al., 2009]. Input-muuttujat (fysikaaliskemiallisiin testeihin perustuen):
1. Kiinteä happamuus Fixed acidity
2. Haihtuva happamuus Volatile acidity
3. Sitruunahappo Citric acid
4. Jäännössokeri Residual sugar
5. Kloridit Chlorides
6. Vapaa rikkidioksidi Free sulfur dioxide
7. Kokonaisrikkidioksidi Total sulfur dioxide
8. Tiheys Density
9. pH pH
10. Sulfaatit Sulfates
11. Alkoholi Alcohol
12. Laatu Quality
Data (valkoviini)
Valkoviinidatan ymmärtämiseksi on hyvä suorittaa tutkiva data-analyysi eli EDA-analyysin (Exploratory Data Analysis), jolla voi tutustua, millaista data on ja onko siinä erityisiä piirteitä. Tässä muutama tieto datasta:
I. Stat>Basic Statistic>Display Descriptive Statistics
Taulukko 3. Valkoviinin statistiikka, N=havaintojen määrä, Mean=keskiarvo, StDev= standarrdipoikkeama
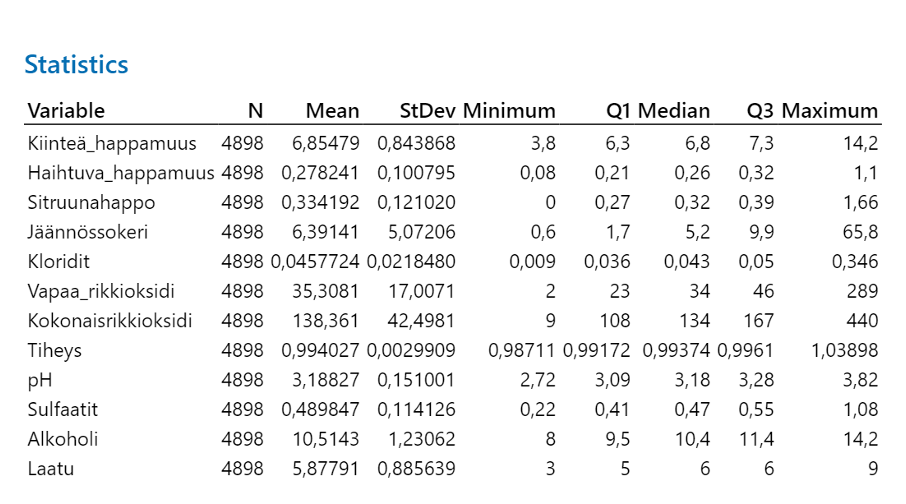
Dataa on 4898 riviä. Kaikki datat ovat jatkuvia eli variaabelidatoja
2. Graph>Graph Builder (Box Plot)
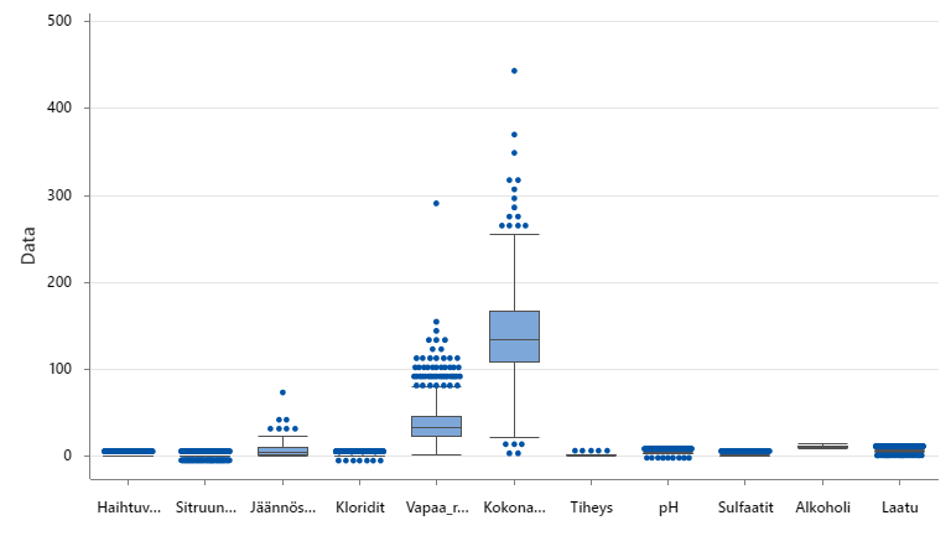
Box Plot -kaavio esittää, että datassa on erityisen paljon ”outliers” jäännössokerissa, vapaassa rikkioksidissa ja kokonaisrikkioksidissa. Mallinnuksessa ei saa olla ”outliers” (erityissyitä). Datan/prosessin pitää olla kohtuullisen stabiili, jotta malli (ennuste) on luotettava. Mikään malli ei onnistu epästabiilista prosessista tai epästabiileilla ennustajilla/muuttujilla (x). Tämä tri Shewhartin laatuteoria, ±3 sigma sääntö, on keskeistä niin laadun suunnittelulle, ohjaukselle kuin parannukselle, joilla tulevaisuutta parannetaan. Katso QKK Laatutaulu-artikkelit ja kirja/2/.
Valkoviinidatan kokonaiskuvan saamiseksi tarkemmin stabiilisuutta ja erityissyitä (oletetaan, että data on aikajärjestyksessä).
3. Stat>Control Charts>Vvariable charts for Individual>I-mR
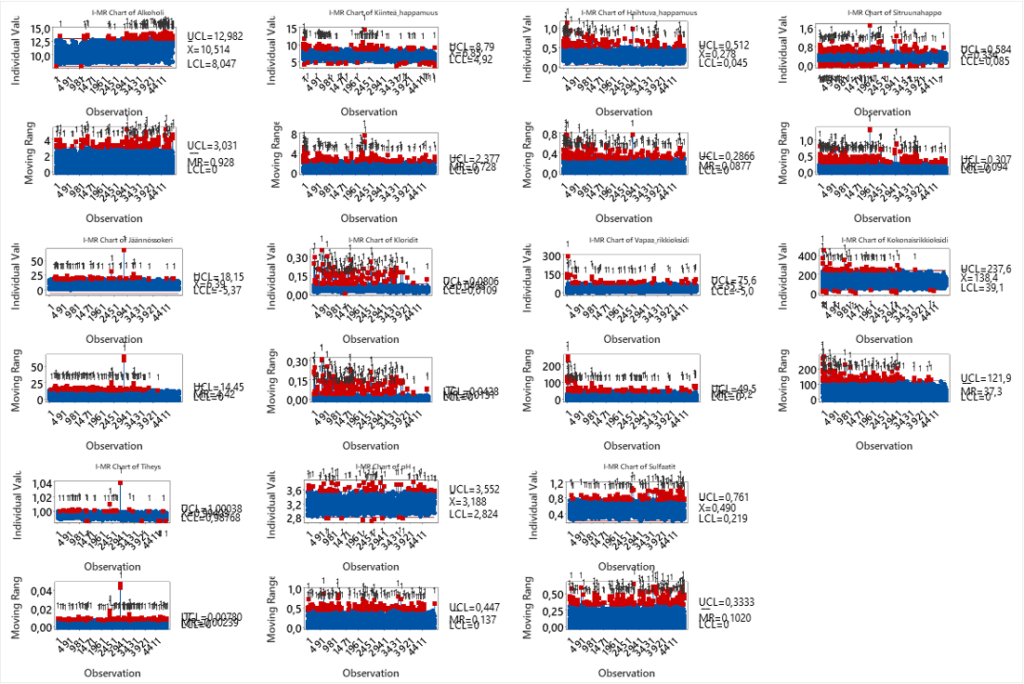
Kuvassa jokaisesta ennustajasta on I-mR -kortti (SPC-kortti). Punaiset pisteet osoittavat erityissyitä. Luotettavan mallin tekemiseksi datasta pitäisi ”puhdistaa” erityissyyt pois, vaikka jotkin mallit ”kestävät” jonkin verran erityissyitä. Datan esikäsittely, ”puhdistus” ja täydennys (imputointi), on keskeistä luotettavan mallin luomiseksi. (Näin en tehnyt tässä yksinkertaisuuden ja toistettavuuden vuoksi! Tässä näytetään mallin tekninen luonti.)
Tutkitaan seuraavaksi ennustajien välisiä korrelaatioita (keskinäisvaikutuksia).
4. Graph>Graph Builder (Correlation)
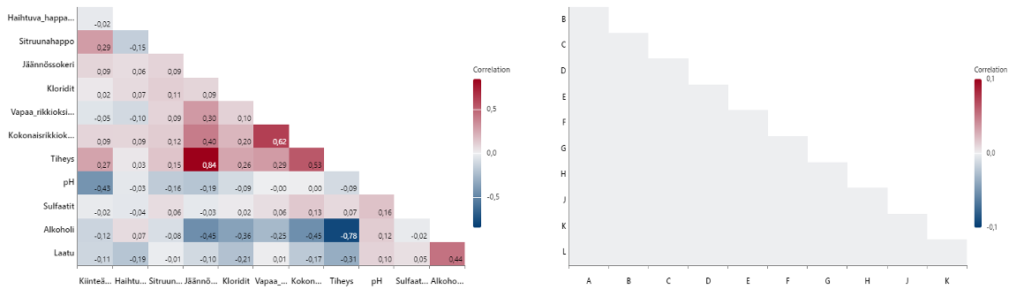
Korrelaatiokuvasta nähdään, että muuttujat korreloivat voimakkaasti toistensa kanssa (havaintodataa). Tällaisesta datasta luotu malli on korrelaatiomalli. Malli toimii välittömiin ennusteisiin esim. seuraaviin tuotteisiin tai palveluihin. Käyttö on ohjaus. Jos data olisi luotu DoE:lla, näytteenottotekniikalla (ortogonaalimatriisilla) olisi pyritty estämään tai ainakin vähentämään korreloitumista kuten oikeanpuoleisesta kuvasta ilmenee! Ei korreloituneessa tilassa kuva olisi liki ”valkoinen”. Tällaisesta datasta luotu malli on kausaalimalli (keskiarvomalli, Six Sigma -malli). Malli toimii välittömiin ja ei välittömiin tuotteisiin ja palveluihin. Kysymys on parannusmallista.
Yhteenveto datasta: Valkoviinidata on ennustajien (x) osalta variaabelidataa. Datassa on runsaasti erityissyitä (outlier), josta voidaan päätellä, että prosessi ei ole stabiili. Tästä seuraa, että mahdollinen malli ei myöskään ole stabiili ja luotettava. Luotettavuutta heikentää myös vahva korreloituminen. Luotettavan mallin luomiseksi data olisi ”puhdistettava”. Ennustajat korreloivat myös voimakkaasti toistensa kanssa. Tämän ilmiön algoritmit yrittävät ratkaista ”laskennalla”.
B. Valkoviini juurisyy ja regressiomalli koneoppimis algoritmilla (perusasetukset)
Käytetään automaattista ML-mallin valintaa: Predictive Analytics Module>Autometed Machine Learning>Discover Best Models (Continuous Responce)
Malli jakaa datan 4898 riviä satunnaisesti kahteen osaan, 70 % koulutusdataan ja 30 % testausdataan. Mallin valinta-algoritmi laskee jokaiselle algoritmille R2-poikkeaman.
- Satunnaismetsämallin R2 (the coefficient of determination, määrityskerroin) edustaa riippuvan muuttujan varianssin osuutta, jonka malli selittää. Satunnaismetsän regression yhteydessä R2 on keskeinen mittari mallin sopivuuden ja ennustustarkkuuden arvioinnissa.
- R2 tulkinta: Lähempänä 1:tä (tai 100 %) oleva arvo osoittaa, että mallin x:t selittävät suuren osan vastemuuttujan vaihtelusta. Lähellä nollaa oleva arvo viittaa siihen, että malli ei selitä vaihtelua yhtään paremmin kuin datan yksinkertainen keskiarvo. Suurin R2 % on paras valinta.
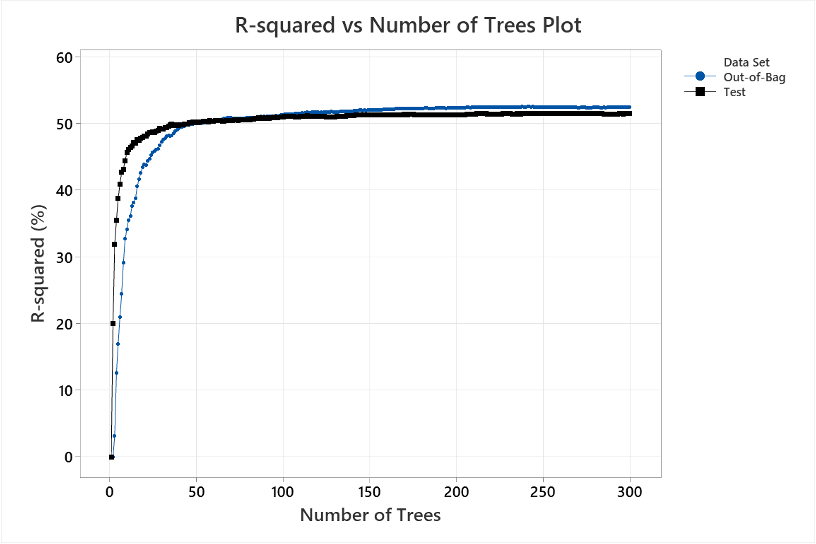
- Konvergenssi: Kun piirretään R2 puiden lukumäärän funktiona, tasoittunut (konvergoituva) viiva viittaa siihen, että riittävä määrä puita on käytetty metsän maksimaalisen ennustuspotentiaalin saavuttamiseksi. (kuva 10)

Paras valinta 5 algoritmista on Satunnaiset Metsät (Random Forests, RF), jonka R2=51,43 %. Kuvasta nähdään, kuinka R2 saavuttaa koulutus ja testidatan osalta n. 50 %:n tason n. 50 puun kohdalla.
Mallin suhteelliset ennustajien vaikutukset on esitettynä kuvassa. Alkoholi ja haihtuva happamuus ovat tärkeitä luokittelun puhtaudelle.
Suhteellinen muuttujien tärkeys on standardoitu mittari, joka luokittelee ennustavat muuttujat sen perusteella, kuinka paljon ne parantavat mallin tarkkuutta tai puhtautta (gin). Mittari skaalaa tärkeyspisteet helpommin tulkittavaksi asettamalla tyypillisesti vaikutusvaltaisimman muuttujan arvoksi 100 % ja laskemalla kaikki muut prosentteina tästä huipusta.
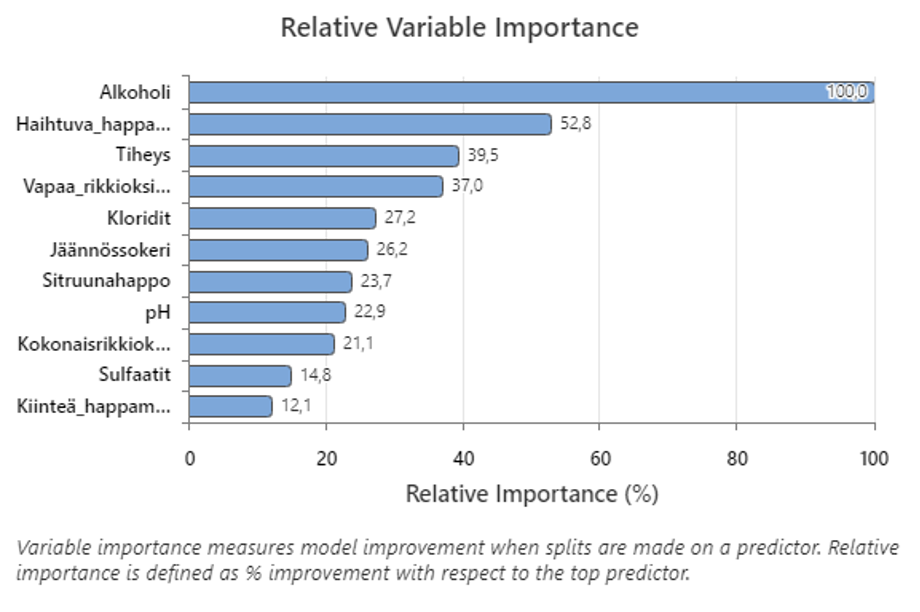
Juurisyy: Tärkeys-kuva kertoo ”mahdolliset” juurisyyt. Huomaa, että tekijä voi myös olla tärkeä, jos se on tulosta voimakkaasta korrelaatiosta. Kuvasta (12) näkyy ”hyppyrin nokka” (Danielin käyrä) neljän tärkeimmän ennustajan jälkeen. Tämä kertoo, että neljä ensimmäistä ennustajaa (x) ovat merkittäviä ja loput 7 ennustajaa ovat kohinaa, sattumatekijöiden aiheuttamia. Näitä neljää tekijää pitää tarkastella tarkemmin juurisyyanalyysissä ja tehdä neljän muuttujan koe (DoE) syy-seuraustekijän (kausaliteetin) varmistamiseksi.
Mallilla ennustaminen ”Predict” valikolla?
Valitse Predict ja syötä haluamasi ennustaja-arvot (taulukko 5). Algoritmi laskee taulukon punaiset arvot.
Oletetaan, että edessämme on tuotantolinjalta tullut 3 valkoviinipulloa, joiden ominaisuudet ja ennustetut laatuarvot Y. Jos kyseessä olisi pullotuslinja, ennuste mahdollistaisi välittömän jokaisen pullon valvonnan ja ohjauksen, jos sekoitusmatriisi (luokitteluvirhe) olisi riittävän pieni. Kuinka lähellä todellisuutta arvot ovat, ei voida tässä varmentaa!
Taulukko 5. Ennustetut viiniarvot, kun neljää muuttujaa on muutettu (harmaat).
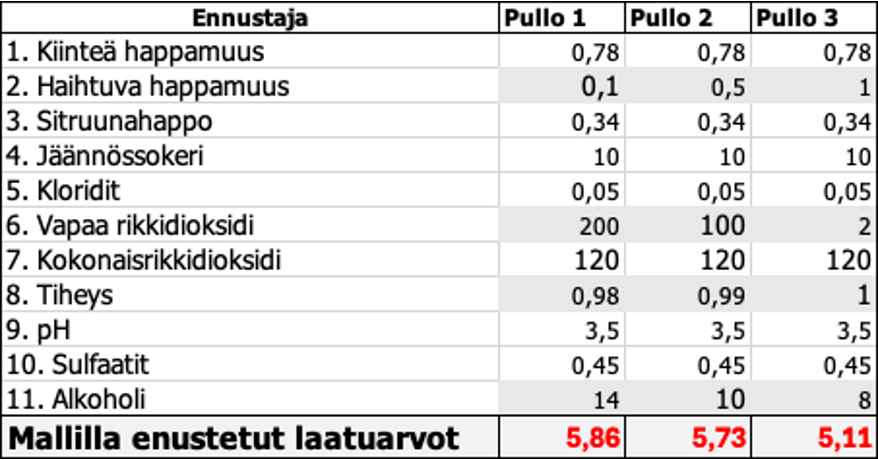
Mallin optimointi Responce Optimizer valikolla? Mistä muodostuu paras valkoviini?
Minitabissa Response Optimizer toimii Random Forests® -regression kanssa hyödyntämällä tallennettua ennustusmallia. Se optimoi tunnistamalla ihanteellisen input asetusten yhdistelmän asetettujen tavoitteiden saavuttamiseksi. Toisin kuin perinteinen regressio, joka käyttää yhtä yhtälöä, Random Forests käyttää satojen puiden yhdistelmää ”sopivuuksien” (ennustettujen arvojen) laskemiseen.
Satunnaismetsien optimoinnin tärkeimmät edut
- Epälineaariset suhteet: Koska satunnaismetsät pystyvät havaitsemaan monimutkaisia, epälineaarisia kuvioita, jotka tavallinen lineaarinen regressio ei välttämättä havaitse, vasteen optimoija voi löytää ”kultaisia pisteitä” datasta, jossa on paljon kaarevuutta tai vuoro/keskinäisvaikutuksia.
- Muuttujarajoitukset: Voit rajoittaa ennustajia tiettyihin alueisiin tai pitää tiettyjä tekijöitä vakioina ja optimoida toisia.
- Useita ratkaisuja: Monimutkaisille malleille, kuten Satunnainen Metsille (RF), Minitab voi tallentaa useita ”paikallisia” optimaalisia ratkaisuja uuteen laskentataulukkoon vertailua varten.
Optimoidaan/maksimoidaan viinin laatu seuraavilla parametreilla.
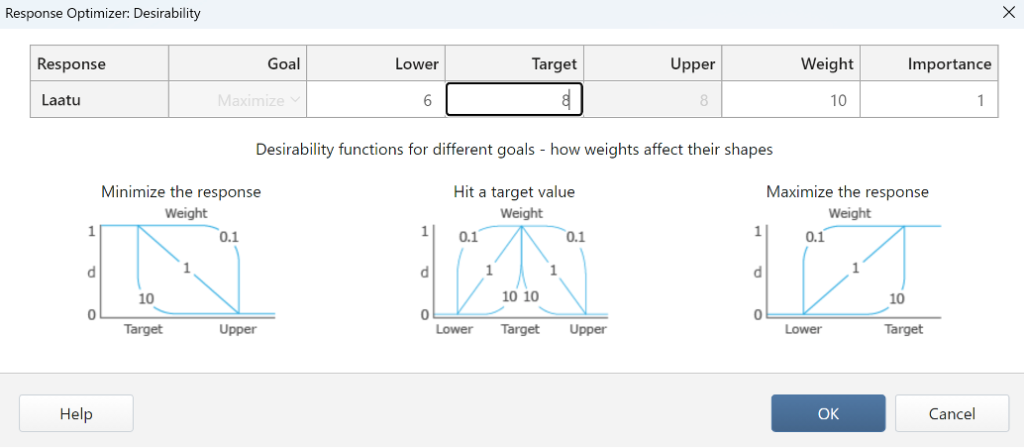
Optimoija löytää ratkaisun, jossa Laatu on 7,22.
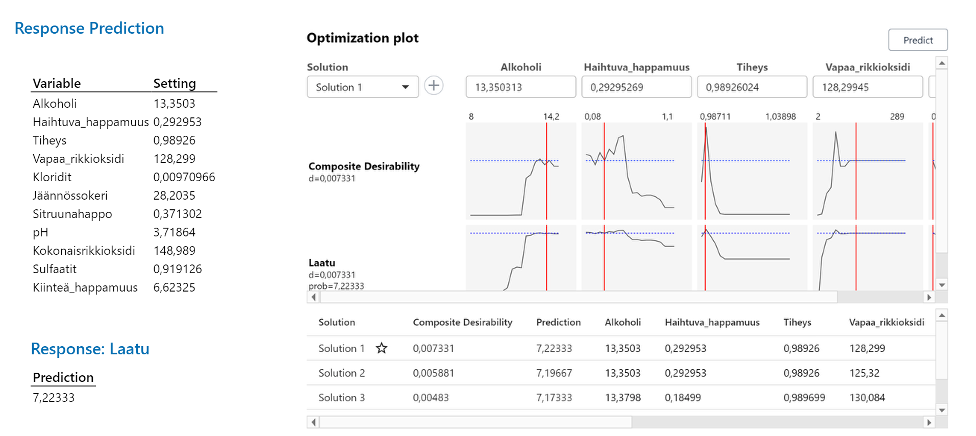
C. Valkoviini luokittelumalli koneoppimis algoritmilla (perusasetukset)
Luokittelijan luomiseksi jaetaan LAATU kahteen luokkaan. Luokka 1 on laadut, jotka ovat pienempiä kuin Laatu <5 ja luokka 0 on Laatu ≥ 5. Koodaus voidaan toteuttaa esim. Edit>Sort käskyllä lajittelemalla laatu suuruusjärjestykseen ja merkitsemällä uuteen sarakkeeseen Luokka 1:llä kaikki 183 kpl, joissa laatu<5 ja loput 0:lla.

Tarkastellaan muuttujien luokkajakoa histogrammikuvalla, jossa ennustajan (x) histogrammikuvaan on piirretty luokan 1 ja 0 jakaumat (käyrät).
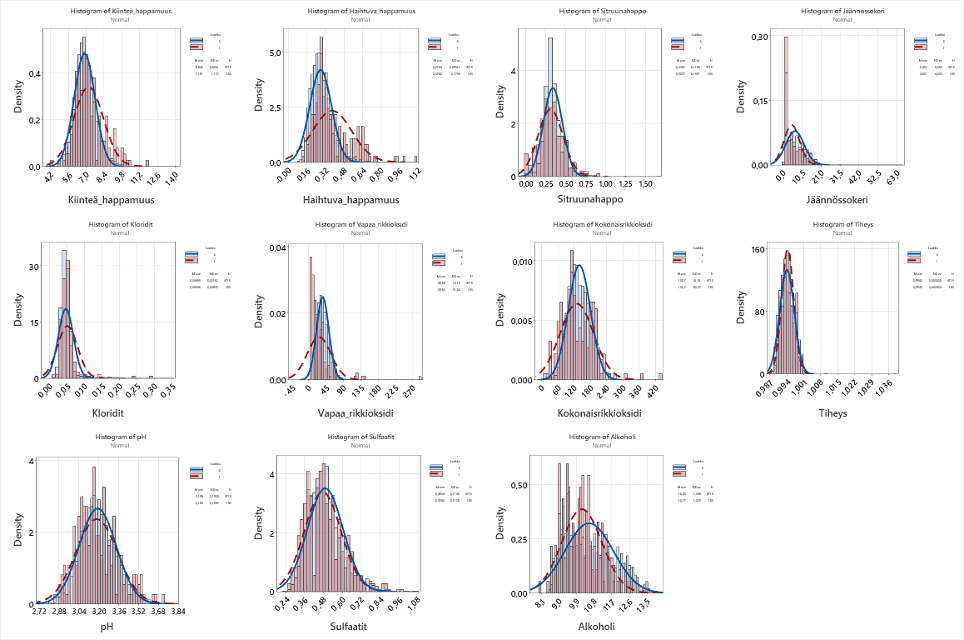
Kuvasta havaitaan, että mikään yksittäinen tekijä ei selitä, miksi viini on huonoa (1) tai hyvää (0). Toisin sanoen jakaumat ovat lähes päällekkäin.
Mallin stabiilisuuden tarkastelemiseksi olisi tarkasteltava kunkin tekijän ”outlier” eli erityissyitä ja ennen mallin luomista olisi selvitettävä ja poistettava erityissyyt ja korvattava mahdolliset puuttuvat datat. Tässä esimerkissä ei yksinkertaisuuden (toistettavuuden vuoksi) näin tehdä.
Käytetään automaattista ML-mallin valintaa: Predictive Analytics Monude>Autometed Machine Learning>Discover Best Models (Binary Responce).
Malli jakaa datan 4898 riviä satunnaisesti kahteen osaan, 70 % koulutusdataan ja 30 % testausdataan.
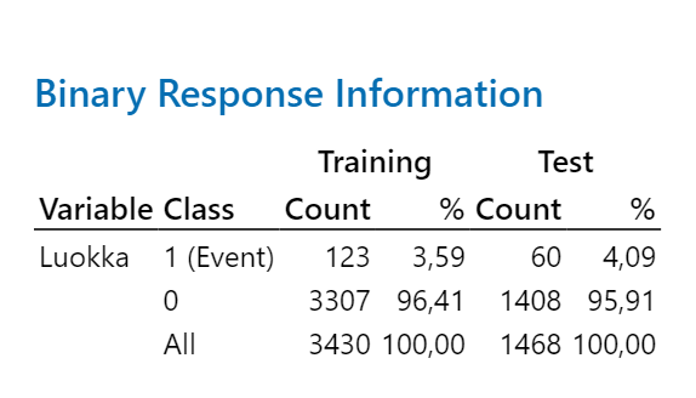
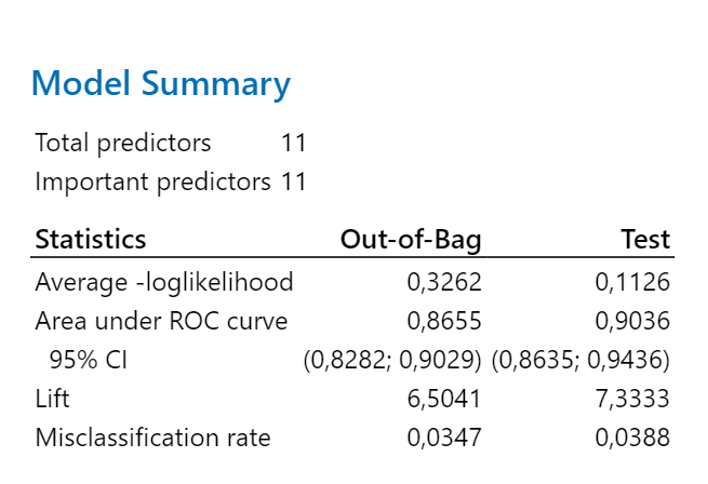
Mallin valinta-algoritmi laskee jokaiselle algoritmille Average -Loglikelihood, Area Under ROC Curve ja Misclassification Rate.

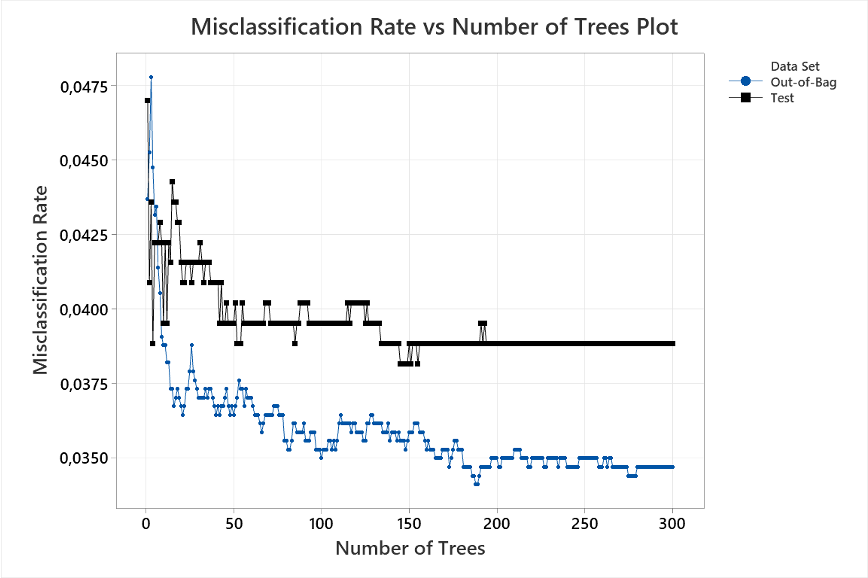
Mallin valinta on Ramdom Forests. Minitab luo mallin valinnan jälkeen automaattisesti ja näyttää luokkavirheet ”Out-of Bag” ja testijoukolle puiden lukumäärän funktiona ja antaa mallin statistiikan.
Tärkeimmät tekijät luokitteluun on annettu kuvassa ”Relative Variable Importance”. Suhteellisen muuttujan tärkeyden kuvaaja piirtää ennustajat mallin parannukseen vaikuttavien muuttujien vaikutuksen mukaisessa järjestyksessä, kun ennustajalle tehdään jakoja puiden sekvenssin perusteella. Tärkein ennustajamuuttuja on tässä ”tiheys”. Jos tärkeimmän ennustajamuuttujan, Tiheys, osuus on 100 %, seuraavaksi tärkeän muuttujan, Jäännössokeri”, osuus on 78,1 %. Tämä tarkoittaa, että jäännössokerin merkitys on 78,1 % yhtä suuri kuin Tiheys tässä luokittelumallissa.
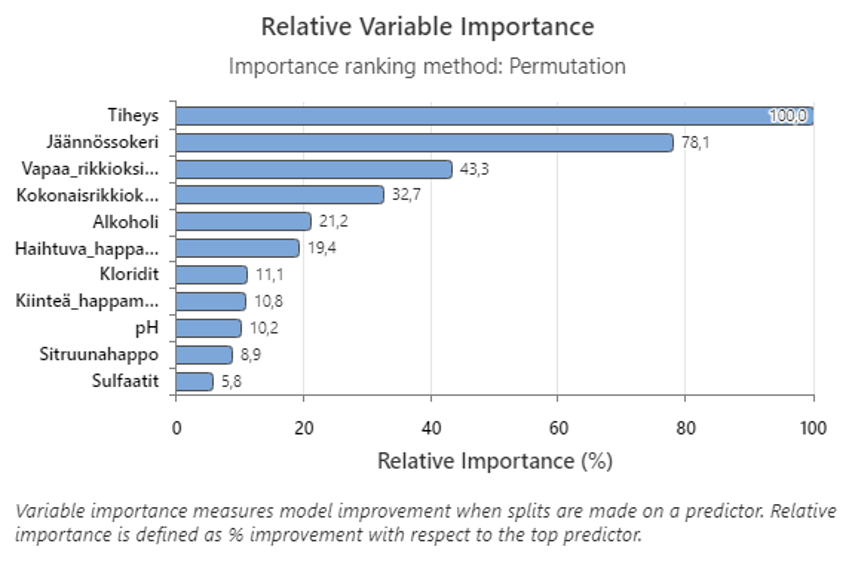
Juurisyy: Tärkeimmät tekijät muodostuvat 6:sta ensimmäisestä tekijästä (”hyppyri”). Neljä viimeistä erottelevaa tekijää on ehkä kohinaa. Nämä tekijät pitäisi poistaa mallista ja ajaa malli kuudella ensimmäisellä tekijällä. Yksinkertaisuuden vuoksi tätä vaihetta ei tehdä.
Sekaannusmatriisi (Confusion Matrix) osoittaa, kuinka hyvin malli erottaa luokat oikein. Tässä esimerkissä tapahtuman (event=1) oikean ennusteen todennäköisyys on noin 7,32 %. Tapahtumattoman tapahtuman (unevent=0) oikean ennusteen todennäköisyys on noin 99,85 %.
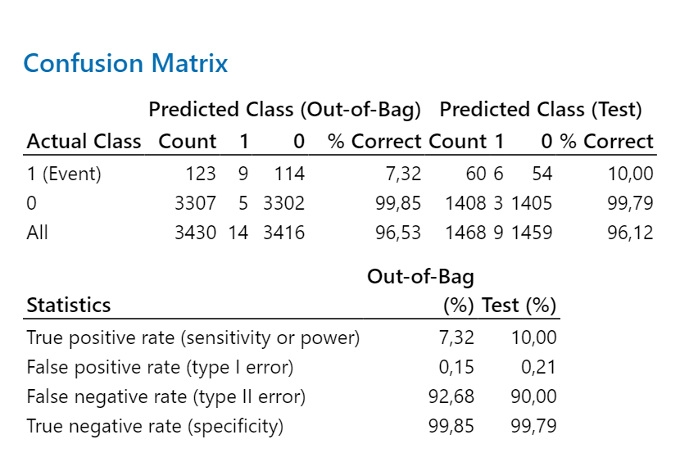
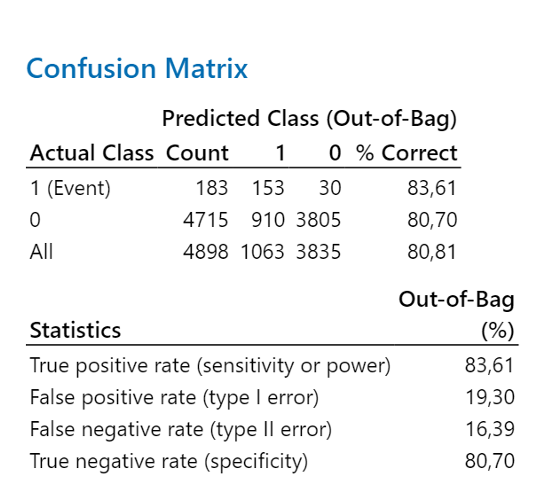
Koska malli erottele virheellisiä valkoviinejä riittävän hyvin (β-virhe 92,98 %), muodostetaan uusi malli, jossa data on tasapainoisempi. Painotetaan virheellisiä (1) datarivejä, joita oli 138:n 4989:stä.
Uudessa mallissa tapahtuman (event=1) oikein ennusteen todennäköisyys on nyt noin 83,61%. Tapahtumattoman tapahtuman (non event=0) oikean ennusteen todennäköisyys laskee 99,79 %:sta 80,70 %:iin. Nyt α- ja β- virheet ovat liki tasapainossa.
Ennustettavan tapahtuman (1) ja ei tapahtuman (0) asetusarvot voidaan kirjoittaa ”Predict” taulukkoon, worksheetille tai optomizeriin. Algoritmi laskee ennustearvon ja antaa toden-näköisyydet 1:lle ja 0:lle. Tämä tulos olisi hyväksymistä/hylkäystä ohjaava tieto tarkastukselle (luokittelu sääntö). Minitabissa luotua sääntöä voi käyttää esim. kirjoittamalla ”tuotannosta” tulevat uudet datat aiemien datojen alle ja ajamalla ennusteen (predict) tai luomalla oman worksheetin tai laittamalla arvot ennustetaulukoon, joka laskee uusille datoille (tietue) ennusteen. Kuvassa olen muuttanut 3 pullon muutamia arvoja ja pyytänyt ennusteen. Kaikki olivat huonoja!

8. Yhteenveto
Laatuteknologia on muutoksessa. Tässä neljän Laatu 4.0 -artikkelin sarjassa olen pyrkinyt luomaan valmiuksia ja keskustelua Laatu 4.0:sta ja sen yhdestä ongelmaratkaisun sovellutuksesta Oppivasta Laadun Ohjauksesta (LQC). Oppiva Laadun Ohjaus on SQC/SPC:n ja tarkastuksen evoluutio, joka vaikuttaa välittömään laadun tekemiseen. (Huomaa, että SPC/Deming/TQM (Laatu 2.0) ja Six Sigma (Laatu 3.0) keskittyivät ”tulevaisuuden” laadun ohjaamiseen ja parantamiseen, ei siis välittömään, jota tarkastus (inspection) Laatu 1.0 edustaa.)
Erityissyiden/epästabiilisuuden ”poistamisen” osalta LQC ei tuo muutosta. Erityissyyt on paljastettava ja analysoitava edelleen ohjauskorteilla/laatutauluilla ja ryhdyttävä ennaltaehkäiseviin toimenpiteisiin kirjaamalla joikainen erityissyyn aiheuttama syy ja tälle vastatoimenpide/2/. Näin stabiloidaan prosessi ja prosessin ulostulosta tulee ennustettava, jolle voi luoda järkevän ML-mallin ja ennusteen.
LQC muodostaa empiirisestä havaintodatasta tekoälymallin, jolla voidaan ohjata tarkastusta ja laatua ”oikeammin” ja tehokkaammin verrattuna aikaisempaan työntekijöiden jälkikäteen tekemiin havainto- ja seurantayhteenvetoihin. Konkreettisena esimerkkinä kuvan 2 tarkastustoiminnan kyky havaita yksittäisisistä osista ja tuotteista virheellisyydet ja viallisuudet.
Oppivaa Laadun Ohjausta ei pidä sekoittaa Lean Six Sigmaan, joka on Laatu 3.0:n keskeinen ongelmanratkaisu ja kuuluu laadun parannuksen piiriin. Six Sigma on SPC/PDSA evoluutio, joka vaikuttaa ei-välittömään laadun tekemiseen. Se muodostaa kokeelisesta datasta (DoE, ortogonaali-matriisi) parannusmallin, jolla voidaan ennaltaehkäistä osissa ja tuotteissa mahdollisesti syntyviä virheitä ja vikoja, jos parannusta (suorituskyvyn nostamista) ei toteutettaisi.
Jotta maailma ei olisi niin sinivalkoinen, on ilmeistä, että osia Laatu 4.0:ssa kehitetyistä menetelmistä tullaan käyttämään Laatu 3.0:n menetelmien ”terästämiseen” ja päivittämiseen. Ensimmäiset Six Sigman laajennukset koneoppimisen on nähty! Kuinka paljon nämä lisäykset tuovat lisäarvoa, on vielä tuntemattomia.
Laadunohjaus (LQC) että laadun parannus (Six Sigma) vaativat vankkaa osaamista, jotta molemmat mallit ovat oikeita ja vaikuttavia. Six Sigman koulutuksesta ja käyttöönotosta on saatu erinomisia kokemuksia. Laatu 3.0 ja Six Sigman tietoisuuden kasvattaminnen ja koulutus rakennettiin erityisen sertifiointiohjelman päälle. Tätä samaa rakennetta suositellaan myös LQC:n ja sen kouluttamiseen. Artikkeliin on kerätty ja hahmoteltu ”tekoäly” Beltien, dataosaajien, koulutusohjelmaa. Tämä vertautuu koesuunnittelun (Six Sigma) koulutukseen niin keston kuin vaativuudenkin osalta.
Lähteet:
- Eero E. Karjalainen, Tanja Karjalainen: Lean Six Sigma 2.0 ja laatuteknologia, (2020)
- Eero E. Karjalainen, Tanja Karjalainen: Laatutaulu – Tehokas menetelmä laadunohjaukseen ja parannukseen, (2024)
- Bergquist, T. M. and Ramsing, K. D.: Measuring performance after meeting award criteria. Quality Progress,(1999)
- https://sixsigma.fi/wp-content/uploads/2021/03/sivullinen_talouselm.pdf
- Elisa Gonzalez Santacruz …: Integrated Quality 4.0 Framework for Quality Improvement Based on Six Sigma and Machine Learning Techniques Towards Zero-Defect Manufacturing, The TQM Journal (2024)
- Judi E. See: Visual Inspection Reliability for Precision Manufactured Parts, Sandia National Laboratories, HUMAN FACTORS, Vol. 57, No. 8, December 2015
- Judi E. See: Visual Inspection: A Review of the Literature, SANDIA REPORT, SAND2012-8590, October 2012
- Carlos A. Escobar, Ruben Morales-Menendes: Machine Learning in Manufacturing –Quality 4.0 and the Zero Defects Vision (2024)
- Avigdor Zonnenshain, Ron S. Kenett: Quality 4.0—the challenging future of quality engineering, Quality Engineering, (2020)
- Carlos A. Escobara, Debejyo Chakrabortya, Megan McGoverna, Daniela Maciasb, Ruben, Morales-Menendezb: Quality 4.0 — Green, Black and Master Black Belt Curricula, Procedia Manufacturing (2021)
- Carlos Alberto Escobar Diaz: Beyond DMAIC: Leveraging AI and Quality 4.0 for Manufacturing Innovation in the Fourth Industrial Revolution, Quality Magazine (2024)
- Quentin Brook: Lean Six Sigma Minitab® The Complete Toolbox Guide for Business Improvement, 8th edition, (2024)
- P. Cortez, A. Cerdeira, F. Almeida, T. Matos and J. Reis. Modeling wine preferences by data mining from physicochemical properties. In Decision Support Systems, Elsevier, 47(4):547–553, 2009.
- Eero E. Karjalainen: Koneoppimisesta (ML) ja Laatutaulusta (SPC) – Osa 1 (2026)
- Eero E. Karjalainen: Laatu 4.0 – Oppivalla laadunohjauksella (LQC) parempaan laatuun – Osa 2 (2026)
- Eero E. Karjalainen: Laatu 4.0 – Oppiva Laadun Ohjaus prosessi (LQC) – Havaintodata ja sen analysointi ja mallintaminen – Osa 3 (2026)

Tutustu kurssitarjontaamme!


Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.