
Havaintodata ja sen analysointi ja mallintaminen
Tekoäly ja siihen liittyvä Laatu 4.0 ja LQC-prosessi (Learning Quality Control) luo kehyksen, jonka puitteissa toteutetaan Teollisuus 4.0:n laadunhallintaa. Teollisuus 4.0 (Industry 4.0) on teollistumisen neljäs suuri murros (kuva 1). Murros on mahdollisuus teollisuudelle, mutta se on myös haaste laadulle ja laatuammattilaisille oppia uusia menetelmiä ja ottaa niitä käyttöön. Tätä LQC on.
Teolliset tuotteet ja palvelut paranevat samalla kun niiden totutusprosessit ovat uusiutumassa ja monimutkaistumassa merkittävästi 2020-luvulla. Uudet tekoälyyn perustuvat High-Tech -yritykset ovat jo nyt pörssiyhtiöiden kärjessä. Ne soveltavat ja hyödyntävät Laatu 4.0 -konsepteja laajasti.
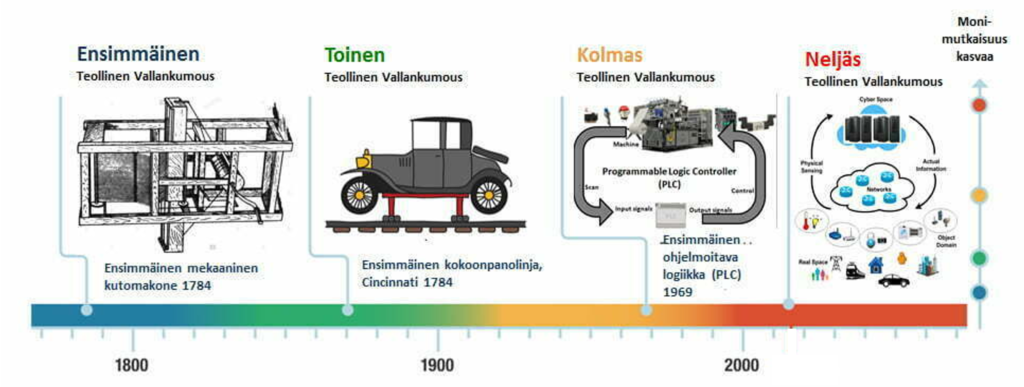
Neljäs teollinen murros on samalla valmistuksen digitaalinen vallankumous, jota kuvaa tekoäly (AI), koneoppiminen (ML), teollisten esineiden internet (IIoT), pilvitallennus ja laskenta (CSC). Teollisuus 4.0 luo ”älykkäitä tehtaita”, joissa järjestelmät, prosessit, koneet, data ja ihmiset ovat vuorovaikutuksessa reaaliajassa toistensa kanssa, mikä lisää tehokkuutta, ketteryyttä ja räätälöintiä koko toimitusketjussa. Tässä ympäristössä ”vanha” laadunohjaus ei enää ole riittävän kyvykäs. Tarvitaan uusi laatualoite, Laatu 4.0 ja sen soveltamisen prosessi LQC. On muutoksen aika!
Sisältö:
- Johdanto
- LQC ongelmanratkaisun strategia ja prosessi
- Havaintodata ja kokeellinen data
3.1. Havaintodatan määrä ML-mallin
3.2. Koedatan määrä DoE-malliin - Koneoppimismalli – luokittelumalli ja regressiomalli – sovellutukset
- Binäärisen luokittelijan kehittäminen tarkastuksen tehostamiseksi – LQC-vaiheet
5.1. Miten binäärinen laatuluokittelija toimii?
5.2. Luokittelijan ulostulomittari Y ja sekaannusmatriisi
5.3. LQC-prosessi (IODLR)
5.3.1. Tunnista: (Identify)
5.3.2. Havaitse: (Observe, Ascencorize,)
5.3.3. Data: (Discover Data)
5.3.4. Opi: (Learn)
5.3.5. Ennusta: (Predict)
5.3.6. Suunnittele uudelleen: (ReDesign)
5.3.7. Opi uudelleen: (ReLearn) - Joitain luokittelijan sovellutuksia
6.1. Vikojen ennaltaehkäisy
6.2. Luokittelijalla (tekoälyllä) tehostettu SPC/SQC kohde- ja lopputarkastus
6.3. Luokittelijalla (LQC) totutettu laadunvalvonta ja ohjaus - Yhteenveto
- Lähteet
1. Johdanto
Uusi teollinen rakenne muuttaa voimakkaasti laadunohjauksen ja valvonnan kenttää. Laatu 4.0 (Quality 4.0) on kehitetty varmistamaan Teollisuus 4.0 tuottamien tuotteiden ja palveluiden laadun. Kuva 2a. Laatu 4.0 tuo modernin ongelmanratkaisun neljännen aallon koneoppimisen työkalun LQC:n (1. aalto SQC/SPC, 2. aalto PDSA, 3. aalto Lean Six Sigma, 4. aalto LQC). Tämä ratkaisu tukeutuu aiempien teknologioiden tilastollisiin ja johtamiseen liittyviin perusteisiin. Laatu 4.0 muodostuu kuudesta tiedon ja osaamisen alueeseen: Laatu, Tilastotiede, Ohjelmointi, Optimointi, Oppiminen, Valmistus.
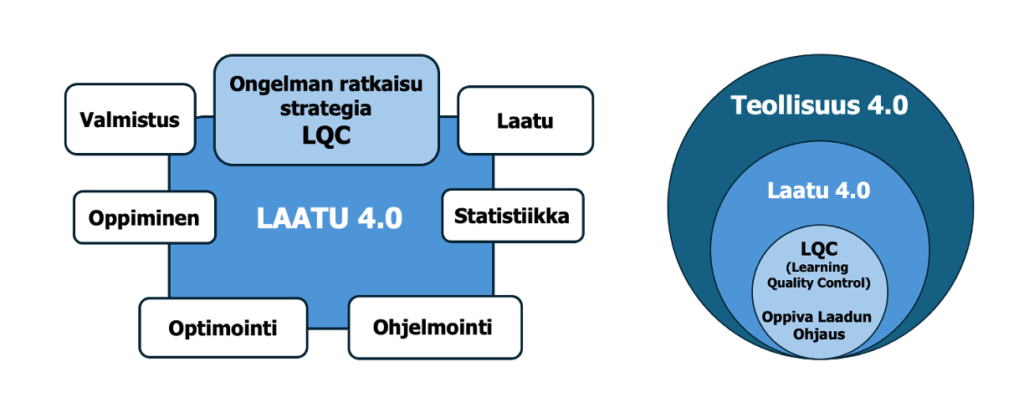
Laatu 4.0 on laadun kypsyysportaiden ylimmällä askeleella (kuva 3), jota menestyvimmät yritykset – Iscar, Hamlet, RAFAEL ja Kornit/3/ – käyttävät ja muut tavoittelevat.
- Iscar on erikoistunut metallinleikkaustyökaluihin. He saavuttivat maailmanluokan laadun ja tuottavuuden. Innovaatioprosessien ansiosta 60 % kaikesta myynnistä tuli viimeisten viiden vuoden aikana esitellyistä tuotteista.
- Ham-Let perustettiin vuonna 1950, ja se on maailmanlaajuinen huippulaatuisten instrumentointiventtiilien ja -liittimien toimittaja.
- RAFAEL on huippuluokan yritys, joka on ollut yli 70 vuoden ajan edelläkävijä puolustus-, kyber- ja turvallisuusratkaisujen kehittämisessä ilmassa, maalla, merellä ja avaruudessa. Toimittaa myös Suomen armeijalle puolustusvälineitä.
- Kornit on maailman johtava vaate-, vaatetus- ja tekstiiliteollisuuden digitaalisten painoteknologioiden kehittäjä, valmistaja ja markkinoija.
Edellä mainitut yritykset ovat Laatu 4.0:n onnistuneita soveltajia lähteen/3/ mukaan ja saavuttaneet kypsyystason 4.
Ohjauksesta siirrytään yhä enemmän ennustamisen.

Tässä artikkelissa käsitellään neljättä ongelmanratkaisuteknologiaa (LQC), joka perustuu havaintodataan, sen analysointiin ja mallintamiseen. Mallinnuksessa käytetään tekoälyn osa-aluetta, koneoppimista. LQC on SQC/SPC evoluutio, seuraava askel, joka parantaa erityisesti tarkastusta/luokittelua ja ongelmien ennaltaehkäisevää havaitsemista ja ongelmanratkaisua tarjoamalla paremman/oikeamman kuvan nykytilanteesta ML-mallin avulla. Malli vastaa kysymykseen, onko tuote tai komponentti luokiteltava vialliseksi, paljon luotettavammin kuin visuaalinen tarkastaja.
2. LQC ongelmanratkaisun strategia ja prosessi
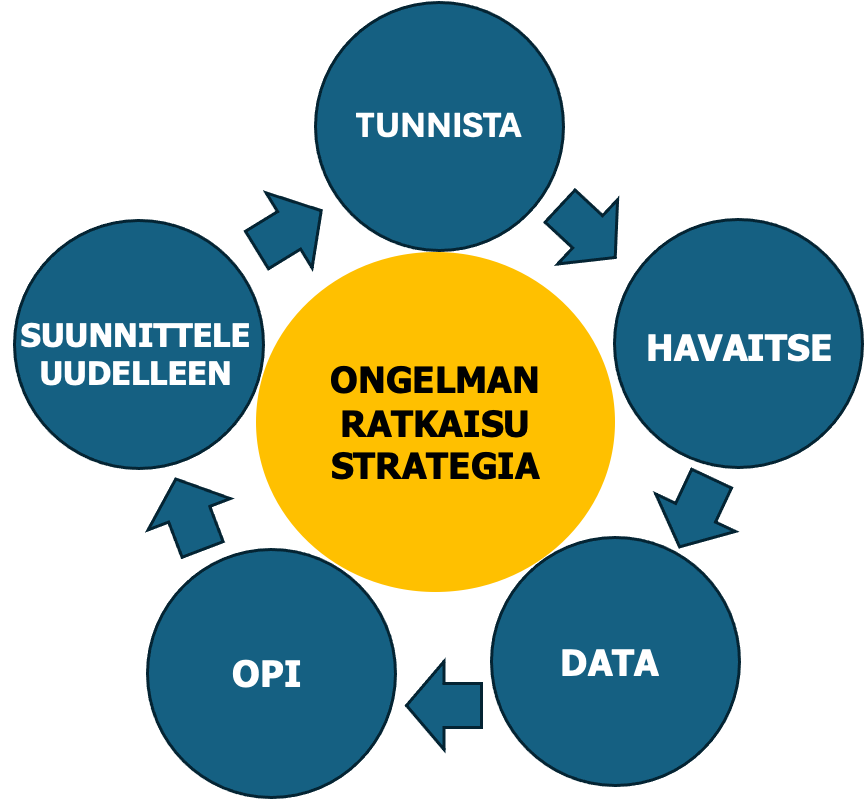
Oppivan Laadun Ohjauksen, LQC (ML+ QC =LQC) prosessi muodostuu 5 vaiheesta – Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen – Identify, Observe, Data, Learn, Redesign (IODLR)./2, 4/ Kuva 4.
Artikkelissa Laatu 4.0 – Oppivalla laadunohjauksella (LQC) parempaan laatuun! Osa 2 totesin, että ”Laatu 4.0 perustuu uuteen paradigmaan, joka mahdollistaa älykkäät päätökset empiirisen oppimisen, empiirisen tiedon löytämisen ja reaaliaikaisen tiedon tuottamisen, keräämisen ja analysoinnin avulla”. Empiirinen (kokemusperäinen) oppiminen ja tieto, data on havaintodataa.
Tuotannon havaintodata on suuri käyttämätön tuotantoresurssi! Eri tutkimusten mukaan 95-99 % tuotannon havaintodatasta on käyttämätöntä ja keräämätöntä. Menetämme paljon tietoa ja ymmärrystä nykytilanteesta. Miksi tiedonlouhintaa ei toteuteta ja miksi se on vaikeaa? Tri Douglas C. Montgomery toteaa artikkelissa ”Havaintotietojen tutkiminen”/5/ sattumanvaraisesta ja rutiininomaisesta käytöstä kolme tärkeää seikkaa:
- Tyypin II virheet. Suurissa havaintotietokannoissa jotkut (joskus monet) tekijät eivät muutu merkityksellisillä alueilla, jotka ovat riittävän suuria tuottamaan signaalin, joka nousisi kohinan yläpuolelle. Kun näin tapahtuu todella tärkeälle tekijälle, silloin syntyy todennäköisesti analyysiin tyypin II virhe eli β-virhe. Kun järjestelmästä tai prosessista opitaan ensimmäistä kertaa, olipa kyseessä sitten suunniteltu koe tai havaintotutkimus, tyypin II virheet ovat yleensä katastrofaalisia.
- Multikollineaarisuus. Muuttujat, jotka kaikki pyrkivät vaikuttamaan yhdessä. Muuttujien, tekijöiden välillä on erittäin vahva korrelaatio keskenään.
- Näennäinen korrelaatio – kaksi muuttujaa näyttää olevan yhteydessä toisiinsa, koska ne molemmat liittyvät kolmanteen tekijään, joka on syy-seuraussuhde molempiin alkuperäisiin tekijöihin.
Montgomery toteaa edelleen: ”Olen aina varovainen tulkitessani laajamittaisen tiedonlouhinnan tuloksia, joissa on käytetty kehittyneitä tilastollisia työkaluja. Tällaisista tutkimuksista on erittäin vaikea löytää todellisia syy-seuraussuhteita, juurisyitä. Kehotan aina analyytikoita käyttämään tiedonlouhintaa – tekoälyä ja koneoppimista – työkaluna hyödyllisten hypoteesien luomiseksi mahdollisista suhteista muuttujien välillä. Sen jälkeen suunnittelemaan suunniteltuja kokeita (DoE), joita voidaan käyttää syy-seuraussuhteen osoittamiseen.”
Yleensä tieteellinen päättelyt ja tähän perustuva (tieto)osaaminen perustuu ”erityiseen” havaintodataan, esimerkiksi näyte- ja koedataan esim. sampling, DoE ja siitä muodostettuun malliin. Data on ennen keräämistä määritelty ja jollain tavalla rajattu ja sille on asetettu erilaisia ehtoja. Näin siksi, että analyysimenetelmät antaisivat oikeita ennusteita (=tietoa). ”Yleisiä” analyysimenetelmiä on vähän ja niiden uskottavuus on kyseenalainen!
Nyt tekoäly, koneoppiminen ja (pilvi)laskenta, muuttaa tätä asetelmaa! Voidaanko rajoittavista ehdoista luopua ja kuinka paljon ja siirtyä puhtaaseen empiiriseen havaintodataan ja siitä muodostettuihin malleihin? Onko tulokset oikeita ja luotettavia? Kuinka paljon yrityksen tuottavuus kasvaa ja laatu paranee, kun käytetään ”puhdasta” empiiristä havaintodataa tietokonetta opetettaessa (Machine Learning)? Vuosisatoja, jos ei tuhansia, on havaintodataa yritetty hyödyntää enemmän tai vähemmän onnistuneesti.
Havaintodatan ongelmatiikkaa on kuvannut erinomaisesti Tri R. A. Fisher. Katso artikkeli: Kausaliteetti-syy on ehto parannukselle – mitä se on?/6/. R. A. Fisher pystyi kehittämään menetelmän, jossa erityistä dataa (DoE) voidaan käyttää luotettavan ja ennustavan mallin luomiseen, jolla voidaan myös todistettavasti parantaa tuottavuutta (/6/ kuva 6. Viljojen satoisuuden kasvaminen 200-300 % muutamassa vuosikymmenessä on ihme vuosituhansien muutaman prosentin kasvuun verrattuna).
Havaintodatan käyttäminen koneoppimisessa ei ole aivan yksinkertaista. Datan keräämiseksi ja mallin luomiseksi on kehitetty LQC-ongelmanratkaisuprosessi (IODLR-prosessi), jolla pyritään välttämään datan luomisen ja keräyksen virheitä ja mahdollistamaan ja tehostamaan ja havaintodatan käyttöä. Tätä voi verrata koesuunnittelun (DoE) yhteydessä käytettävään Lean Six Sigma DMAIC-prosessiin ja parannusmalliin.
3. Havaintodata ja kokeellinen data
Havaintodataa kerätään jonkin ilmiöön (Yi) ymmärtämiseksi tarkkailemalla ja mittaamalla ilmiön synnyttämää prosessiailman havainnoijan suoraa puuttumista tutkittavien ja mahdollisesti vaikuttavien muuttujien, parametrien (XI:nä), asetuksiin ja keräämistapaan. Xin:t ovat yleensä satunnaisia havaintodatoja. Tarkoituksena on ymmärtää ja määrittää funktio Yi:n ja xin:ien välinen funktio Yi=f(xin) eli malli. Yi:n ja xin välisiä yhteyksiä f kuvaa jokainen taulukon rivi. (Kuva 5)
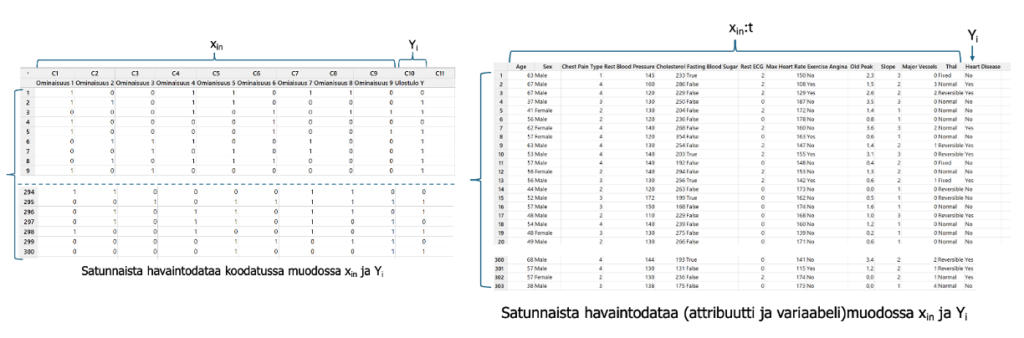
Kuvassa 5 on yhdeksän (n=9) ominaisuuden xin luokiteltua havainto- ja ulostulo dataa Yi, jossa i=300 rivien määrä. Taulukossa a) on luokiteltu/koodattu 1= hyvä ja 0 = viallinen. Nämä attribuuttiominaisuustilat on havaittu(luokiteltu). Oikeanpuoleisessa kuvassa b) on todellinen esimerkki sydänsairauden mahdollista havaituista tekijöistä xni ja sydänsairaus Yi ei/on. Osa tekijöistä on jatkuvia (ei luokiteltuja) ja osa diskreettejä, laadullisia luokiteltuja muuttujia. Tämä on tyypillistä koneoppimisen ja SPC/laatutaulun yhteydessä kerättävää havaintodataa. Data voi olla myös x:n ja Y:n osalta variaabelidataa (ei luokiteltua mittausdataa)! Tätä rakennetta kutsutaan järjestetyksi (strukturoiduksi) dataksi. Data muodostuu jäljitetystä tietueesta.
Laadunohjauksessa/-valvonnassa kerättävän havaintodatan syynä on voinut olla tuotteen/palvelun ja niiden osien ominaisuuksista x:ien ja Y datan saaminen Laatutaulua/SPC-ohjauskortteja varten/10/ tai muihin valvontatarkoituksiin (prosessivalvonta). Yleensä ohjauksessa ja valvonnassa data on jollain tavalla luokiteltu. Jotkut tuotantokoneet keräävät mittaus, ohjaus ja säätödataa automaattisesti ilman luokittelua koneen tietokantaan. Tämän tietokannan yhdistäminen ulostuloihin Yi (osa, tuote, reklamaatio jne), jota halutaan selittää ja mallintaa, saattaa kuitenkin puuttua (jäljitysmerkinnät). Tällöin tietysti datalla ei voi selittää, mallintaa Y:n käyttäytymistä.
Keräämisessä voidaan käyttää monenlaisia tekniikoita manuaalisesta kynä-paperimenetelmästä erilaisiin prosessitekniikan mittareihin ja älykkäisiin antureihin, jotka on liitetty suoraan dataverkkoon tai internetin välityksellä. Kaikkia prosesseja voi havainnoida ja kerätä suoraa havaintodataa ja luoda jäljitettävyys!
3.1. Havaintodatan määrä ML-malliin
Kuinka paljon tarvitaan havaintodataa koneoppimismalliin (ML)? Tarkkaa määrää ei voida sanoa toisin kuin kokeellisessa datassa, jossa koesuunnitelma (matriisi) määrittää kerättävän datarivien määrän.
Peukalosääntöjä koneoppimisen datamäärään:
- 10x sääntö: Perussääntönä on, että tietojoukossa on vähintään kymmenen kertaa enemmän rivejä kuin ominaisuuksia (sarakkeita, xn). Esimerkiksi kuvan 5 sydäninfarktidatassa on 9 ominaisuutta ja dataa 303 riviä. Siis vähemmän kuin peukalosääntö kertoo – 9×10=900! Toimii kuitenkin.
- Absoluuttiset minimit: Vaikka mallin voi teknisesti rakentaa hyvin pienellä tietojoukolla, jopa 10-30 rivillä, se ei todennäköisesti ole kovin tarkka.
- Yksinkertaiset mallit: Yksinkertaisissa tehtävissä (esim. päätöspuut, lineaarinen regressio) yli 100 riviä saattaa riittää mallinnuksen aloittamiseen.
- Monimutkainen/syväoppiminen (DL): Neuroverkkojen tai monimutkaisten tehtävien kohdalla usein mainittu minimi on 1 000–5 000 kuvaa kategoriaa kohden.
Rivien (datan) määrään vaikuttavat tekijät:
- Mallin monimutkaisuus: Yksinkertaisemmat mallit (kuten päätöspuut tai logistinen regressio) tarvitsevat paljon vähemmän dataa kuin syväoppimismallit (neuroverkot).
- Datan laatu: Korkealaatuinen, puhdas ja edustava data on tärkeämpää kuin pelkkä määrä. Pieni, puhdas tietojoukko voi olla tehokkaampi kuin massiivinen ja kohinainen datamassa.
- Datan monimuotoisuus: Jos datasi on hyvin vaihtelevaa, tarvitset enemmän rivejä kaikkien skenaarioiden ja mallien kuvaamiseen.
- Ominaisuuksien määrä: Useampi ominaisuus vaatii yleensä enemmän rivejä ylisovituksen välttämiseksi. Liika datan määrä aiheuttaa kuitenkin varianssivirheen ja toisaalta liika ominaisuuksien määrä bias-virheen. Näiden välillä on bias-varianssi kompromissi.
3.2. Koedatan määrä DoE-malliin
Kokeellista dataa (Y) kerätään, kun tutkittavaa järjestelmää tai ilmiötä (xin) on manipuloitu jonkin tietyn säännön mukaisesti (Lean Six Sigma projektissa DoE). Tämä sääntö määrittelee suunnitellun datan määrän ja käytön (analyysitapa). Xin:t on tällöin asetettu säännön mukaan. Xin:t ovat asetusarvoja, ei havaintoja. Sen sijaan Yi:t ovat havaintoarvoja.
Kokeellinen data siis sisältää tyypillisesti kontrolloitujen kokeiden (DoE) käytön, joissa yhtä tai useampaa muuttujaa (xin) asetetaan ja tuloksia (yhtä tai useampaa) (Yi) havaitaan ja mitataan tämän tai näiden manipulointien xni:n ”tahdissa”. Kokeessa voi myös olla osa tekijöistä (x) havaintodataa (kovarianssi) ja osa kokeellista dataa (asetuksia). Edellytyksenä siis on, että kokeen tekijä voi ”asettaa” xin:t haluttuun arvoon tai halutun arvon alueelle.
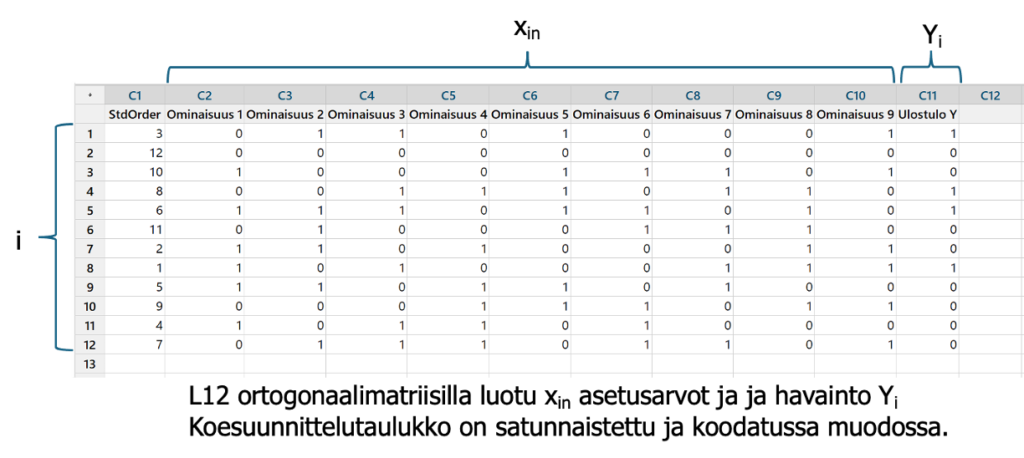
Kuvassa 6 on kokeellista dataa (DoE), jossa on yhdeksän (n= 9) parametria ja ulostulo Yi, i=12 riviä (ortogonaalimatriisi L12 satunnaisessa järjestyksessä). Parametrit on ”asetettu” keinotekoisesti 1 (viallinen) ja 0 (hyvä) silloin, kun valittu koesuunnitelma on niin vaatinut ja lopputulos (Yi) on mitattu/arvioitu hyväksi tai vialliseksi. Xinasetukset voivat olla myös attribuutti- ja variaabeliasetuksia. Ortogonaalimatriisit ja muut koesuunnitelmat löytyvät koesuunnittelun lähdekirjoista tai softan (Minitab 22) valikosta (kuva 7), jossa on luetteloita erilaisia matriiseja ja koesuunnitelmia, jotka voi tulostaa eri muodoissa.
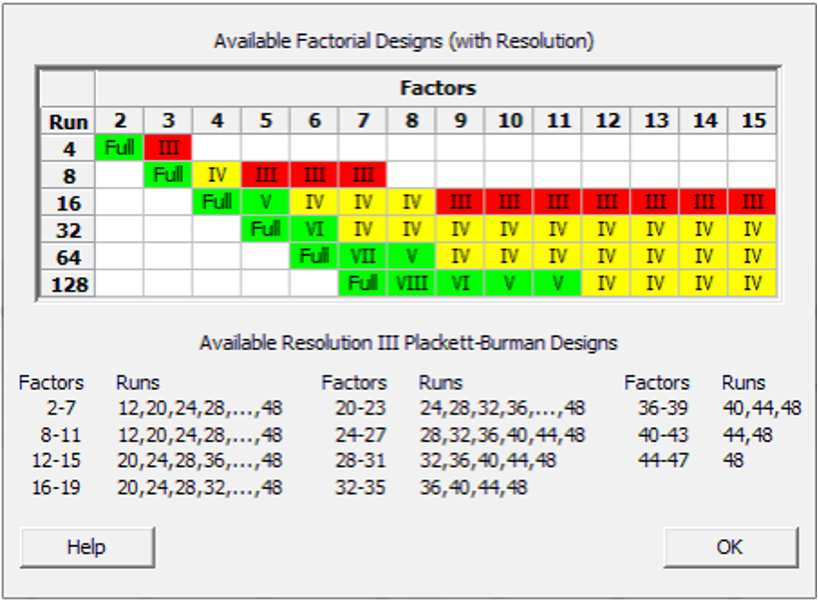
Datan rivien (run) ja sarakkeiden (factors, parameters) määrän ilmaisee käytetty matriisi (L4, L8, L12, L16, L20, L36 jne). Esimerkiksi 9 tekijää (factors) voidaan mallintaa lukuisilla eri matriiseilla (L12, L16, L32, L64, L128). Roomalaiset numerot ilmaisevat kokeen resoluutiota eli kykyä määrittää keskinäisvaikutuksia. Tarkemmin valinnasta DoE (Six Sigma) kursseilla.
On kuitenkin lukuisia tilanteita, joissa näitä asetuksia ei voida toteuttaa kaikille x:lle fyysisten, kemiallisten, eettisten, taloudellisten tai muiden syiden estäessä. Kukaan ei tietoisesti tee sydäninfarktikoetta (aseta tekijöitä) niin, että potilas voisi kuolla! Tällöin ainoa mahdollisuus on yrittää käyttää havaintodataa (Kuva 5). Yleinen tapa (joskin huono!) on muuttaa yhtä tekijää kerralla OFAT-kokeessa (One Factor at Time). Perusteluni, miksi ei pitäisi käyttää OFAT-koetta, artikkeli: Muutanko yhtä tekijää vai useita tekijöitä? OFAT vai DoE?.
Molempia datamuotoja voidaan analysoida ja muodostaa malli Minitab 22 -valikoilla Stat->DoE ja Predictive Analytics Modules->Predictive algoritmit. Mitä valikoita käytetään? Vastaus tähän on tulosten oikeellisuudessa ja käyttökelpoisuudessa. Jos havaintodataa (kuva 5) analysoidaan DoE-valikolla virhe voi olla suurempi kuin analysoitaessa Minitab Predectivity Analytics Modul:lla.
Molempia datatyyppejä (havainto ja koedata) voidaan käyttää koneoppimismallinnuksessa ennustavien mallien kouluttamiseen. Kokeellista dataa suositaan usein, jos sitä on saatavilla, koska tällöin dataan on mahdollista vaikuttaa enemmän ja koska tämän tyyppinen data voi auttaa selvittämään muuttujien välisiä syy-seuraussuhteita, juurisyitä, korrelaatioiden sijaan. Tarvittava datamäärä, laskentateho, juurisyiden selvittämisen mahdollisuus, mallin tarkkuus ja monet muut seikat puoltavat koedatan käyttöä. Mutta, jos koetta (≈ Lean Six Sigma prosessilla luodaan parannusmalli) ei voi tehdä, valinta on havaintodata (≈LQC prosessi).
Havaintodatan kanssa työskenneltäessä jokainen ominaisuus (xin) ja näiden ominaisuuksien mahdollisesti aikaansaama(t) ulostulot Yi on arvioitava (annotoitava ja ”puhdistettava”) tekniikan tai fysiikan näkökulmasta ennen koulutusprosessia, sen varmistamiseksi, että ei opita virheellistä mallia. Usein koneoppimisessa ”haravoidaan” tekijöitä paljon. Edellisessä artikkelissa (osa 2) oli esimerkkinä Chevrolet Volt akkujohtimen ultraäänihitsaus, jossa oli 54 x:ää ja 2 Y:tä (lujuus ja johtavuus). Koulutusjoukko 18 495 – mukaan lukien 20 epäilyttävää. Tästä muodostuu taulukko, jossa on 56 saraketta ja 18495 riviä eli yhteensä 1 milj. dataa, jotka kaikki on käytävä läpi, ennen kuin koulutus voi tapahtua. Tämä esimerkki on vaativa! Näin suureen datajoukkoon jouduttiin, jotta epäilyttäviä virheitä olisi riittävästi (>10). Tässä 20 eli 0,1 % joka oli ultraäänihitsauksen lähtötaso.
Vaikka kokeiden suunnittelu (DoE) ja koneoppiminen (ML) pyrkivät molemmat ymmärtämään syötteiden (x) ja tuotosten Y välisiä suhteita eli muodostamaan malli, ne eroavat perustavanlaatuisesti toisistaan lähestymistavassa – tiedonkeruussa ja mallinnuksen monimutkaisuudessa ja mallin luonteessa.
Koneoppimismalli on malli ”tässä ja nyt”, joka voi stabiilissa tilanteessa säilyä huomiseen. Data on tuotteen ominaisuusdataa (charasteristic, feature) esimerkiksi ihmisestä mitattuja veriarvoja ja muita mittaustuloksia, jolla voi ennustaa, antaa prognoosin, ihmisen hyvinvointitilasta nyt.
Koesuunnittelumalli on malli ”tässä ja huomenna”, joka voi stabiilissa tilanteessa pysyä muuttumattomana tai sisältää suunnitellun muutoksen, jota kutsutaan ”huomisen” parannukseksi. Koesuunnitteludata on yleensä prosessin parametridataa (parameter) esimerkiksi huoneilman laatua, saasteita, lämpötilaa, kosteutta jne., joilla voi ennustaa ihmisen hyvinvointitilan huomenna.
Yleensä on vaikeaa tietää, mitkä tuotteen ja palvelun valmistusvaiheen ominaisuudet vaikuttavat ”tarkasti” valmiin tuotteen tai palvelun lopullisiin ominaisuuksiin. Tähän antaa ”tarkemmin” vastauksen (prognoosin) koneoppimismalli YML=f(xo). Samoin on vaikea tietää, mitkä prosessiparametrit vaikuttavat ja/tai muuttavat ”tarkasti” tuotteen tai palvelun valmistuksen aikaisiin ominaisuuksiin ja edelleen tuotteen lopullisiin ominaisuuksia. Tähän antaa ”tarkemman” vastauksen/ennusteen) koesuunnittelumalli YDOE=f(xp).
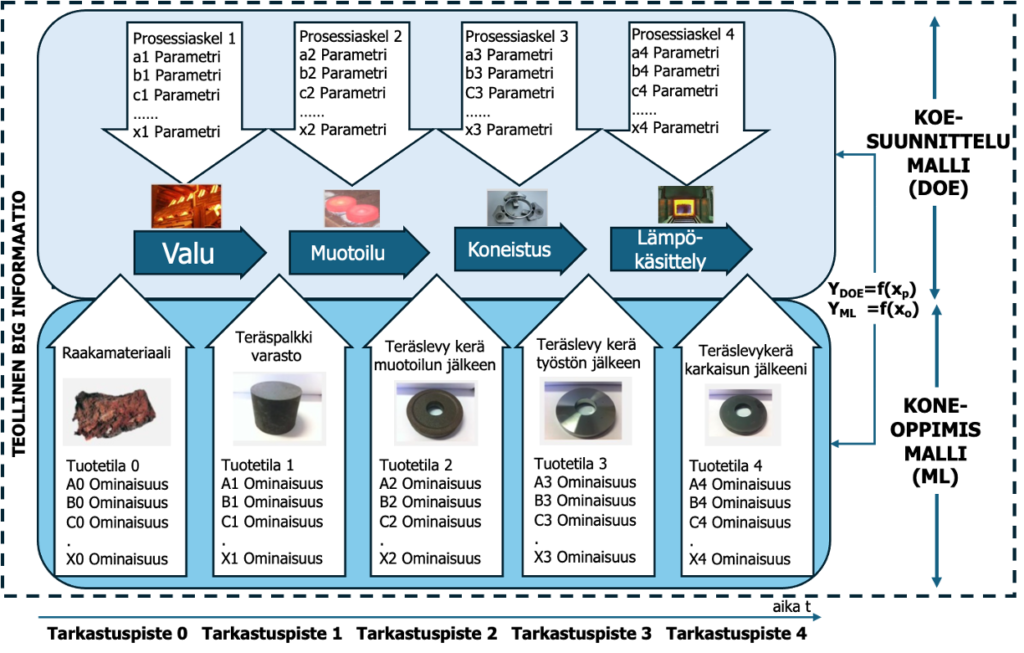
Tuotteen piirteet ovat ominaisuuksia (feature, characteristic) ja mitataan tuotteista (tuote/palvelutila). Näiden muutoksista luodaan koneoppimismalli. Prosessin piirteet ovat parametrejä (prosessitila). Näitä käytetään koesuunnittelussa, koska prosessitilan voi asettaa. Joissain tapauksissa ominaisuudet ovat samoja kuin prosessin parametrit. (Kuvan teräksen valmistusprosessi on esimerkki, joka voidaan korvata omalla tuote- tai palveluprosessilla.)/11/
Ulostulon Y jakaminen (osiointi) tapahtuu koesuunnittelussa ortogonaalimatriisin tai muun datakeräyksen ennakkoehdon mukaisesti yleensä regressioanalyysillä, kun taas koneoppimisessa käytetään puupohjaisia osiointimenetelmiä, gini, entropia tai MSE-analyysejä.
4. Koneoppimismalli ja luokittelu- ja regressiosovellutukset
Koneoppimismallit (ML) ovat yleensä puupohjaisia malleja, joissa päätöspuut rakennetaan ”rekursiivisen osituksen” tai ”ylhäältä-alas induktiojaon” avulla. Menetelmissä käytetään ns. ahnasta (greedy search) algoritmia, jolla data jaetaan toistuviin pienempiin osioihin, yhtenäisiin datajoukkoihin, kunnes pysäytyskriteeri täyttyy (kuva 9). Puupohjaisissa algoritmeissa (kuten päätöspuissa CART, TreeNet tai satunnaismetsissä RF) jakaminen on prosessi, jossa solmu (node) jaetaan kahteen tai useampaan alisolmuun, jotta tulos on datan osalta homogeenisempi (puhtaampi).
Jakokriteerit: Algoritmit käyttävät matemaattisia mittareita (gini, entropia ja/tai MSE) määrittääkseen ”parhaan” jaon kussakin solmussa. (Minitabissa valikosta voi valita jakotavan.)
- Gini-epäpuhtaus: Mittaa, kuinka usein satunnaisesti valittu elementti nimetään väärin. Italialainen tilastotieteilijä Corrado Gini kehitti Gini-kertoimen ja julkaisi sen vuonna 1912 artikkelissaan Variabilità e mutabilità (englanniksi: Variability and mutability).
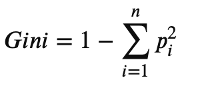
pi on luokan i todennäköisyys
- Entropia/informaation voitto (Gain): Mittaa epäjärjestyksen tai epävarmuuden vähenemistä jakamisen jälkeen. Amerikkalainen matemaatikko ja insinööri Claude Shannon esitteli ensimmäisen kerran ”informaatioentropian” käsitteen uraauurtavassa artikkelissaan ”A Mathematical Theory of Communication” vuonna 1948.
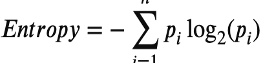
pi on luokan i todennäköisyys
- Varianssin minimointi (regressio): Käytetään regressiopuissa datan jakamiseen tavalla, joka minimoi neliövirheen.
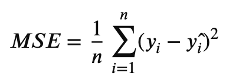
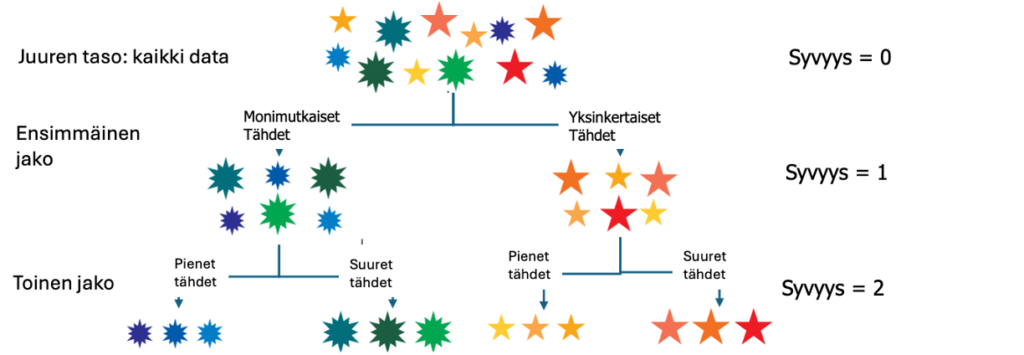
Kuvassa 9 on juurisolmussa (root node) oleva tähtien ”sotku” jaetaan värien mukaan kahtia. Solmussa 2 tähdet jaetaan edelleen koon mukaan kahtia. Lopputulos on neljän muuttujan tulos, joita kutsutaan lehdiksi (leafs) tai päätesolmuksi (terminal node).

Koneoppimisprosessi (algoritmi) noudattaa yleensä seuraavia vaiheita:
- Juurisolmun valinta: Koko koulutusdata (training data) alkaa juurisolmuna.
- Parhaan jaon arviointi: Algoritmi testaa kaikki käytettävissä olevat ominaisuudet ja mahdolliset jakopisteet (esim. määrittääkseen, mikä niistä erottelee datan parhaiten kohdemuuttujan mukaan.)
- Jakamiskriteerin soveltaminen: Löytääkseen ”parhaan” jaon algoritmit käyttävät matemaattisia mittareita puhtauden taiepävarmuuden mittaamiseen:
a) Gini-epäpuhtaus: Mittaa, kuinka usein satunnaisesti valittu elementti merkittäisiin väärin.
b) Tiedonlisäys (entropia): Mittaa epävarmuuden tai ”satunnaisuuden” vähenemistä jaon jälkeen.
c) varianssin minimoimiseksi. Keskimääräinen neliövirhe (MSE) varianssin minimoimiseksi: Käytetään tyypillisesti regressiopuissa numeeristen ulostulojen yhteydessä - Rekursiivinen jakaminen: Data jaetaan haaroihin ja sisäisiin solmuihin. Tämä prosessi toistetaan jokaiselle uudelle solmulle.
- Lehtisolmujen saavuttaminen: Jakaminen pysähtyy, kun ”pysäytysehto” täyttyy, kuten puun maksimisyvyyden saavuttaminen, liian vähän näytteitä jäljellä jakamista varten tai kun lisäjakaminen ei lisää ennustusarvoa. Näitä lopullisia solmuja kutsutaan lehtisolmuiksi, ja ne sisältävät lopullisen ennusteen.
- Karsinta (valinnainen): Kun puu on täysin kasvanut, voidaan ”karsinta” poistaa oksat, jotka tarjoavat vähän ennustusvoimaa, mikä auttaa estämään ylisovitusta.
Algoritmin suorittaminen vaatii tuhansia laskutoimituksia. Tässä sen salaisuus! Algoritmi ”päihittää” ihmisen kokemuksen perusteella ilmaiseman selityksen (luokittelun, mallin) asialle. Jokainenhan voi sanoa mille tahansa asialle, mistä asioista esimerkiksi vika tai virhe johtuu tai mitkä tekijät parantavat! Eikö vain. Malli tämäkin. Valitettavasti tämä on usein virheellisempi ja vähemmin totuudenmukainen kuin ML:n laskentamalli! ML-laskenta ei siis välttämättä ole oikea, mutta se on oikeampi kuin ammattilaisen väittämä, jos LQC-prosessi on oikein toteutettu! Tästä asiasta käydään kiivasta keskustelua esim. hoiva-, terveyspalveluiden tai Kela-korvausten lain- ja asetustenmukaisuusluokittelussa. Uskomus ihmisen ”luomuna” tekemään mallin oikeellisuuteen on lujassa!
Puupohjaisia ML-malleja voidaan käyttää kahteen tarkoitukseen: regressioon ja luokitteluun. Luokittelussa ulostulo (Y) ilmaistaan, mitataan huono (viallinen), hyvä -asteikolla (1, 0). Malli vastaa, mitkä havaintotekijät, ennustajat (x) luokittelevat ulostulon 1:ksi tai 0:ksi ja vastauksena syntyy luokittelumalli. Malli muodostuu puun alimmasta tasosta ”lehdistä” ja niiden lasketusta esiintymistodennäköisyydestä/osuudesta. Kuvassa 9 ”syvyys 2” ja kuva 10.
Jos ulostulo (Y) on jokin arvo, mitta, silloin kyseessä on regressio-ongelma. Vastauksena syntyy regressiopuumalli, joka kertoo mitkä havaintotekijät ja niiden keskinäiset korrelaatiot saavat aikaan arvon.
- Luokittelu-ongelma: Esimerkiksi hitsausprosessissa haluamme ennustaa, onko hitsauksen laatu (Y) hyvä vai huono, kun tutkittavia tekijöitä, ennustajia (x) ovat mitatut kaarijännitteet, langansyöttönopeudet, hitsausnopeudet jne. Vastauksena on luokittelumalli. Luokittelun ytimenä on, kuinka luokittelu tapahtuu. Käänteisesti mallista voidaan päätellä, mitkä tekijät korreloivat ja vaikuttavat viallisen hitsauksen syntyyn.
- Regressio-ongelma: Hitsausprosessissa voidaan myös ennustaa hitsauspalon (Y) leveyden ja korkeuden (mitan) annetuista ennustavista syötetyistä prosessiparametreista (x), kuten mitatusta kaarijännitteestä, langansyöttönopeudesta, hitsausnopeudesta jne. Vastauksena syntyy regressiopuumalli. Käänteisesti voimme myös ennustaa ja optimoida prosessiparametrit (x), jotka johtavat haluttuihin palon leveys- ja korkeusmittoihin (Y).
Laatutekniikassa on tunnistettu LQC:lle seuraavia koneoppimisen regressio ja luokitteluongelmien sovellutuksia: 1) viallisten osien havaitseminen, 2) tapahtumien ennustaminen prosessin alkupään datan perusteella, 3) tarkastuksen automatisointi, 4) parametrien optimointi ja 5) ihmisen älykkyyden laajentaminen.
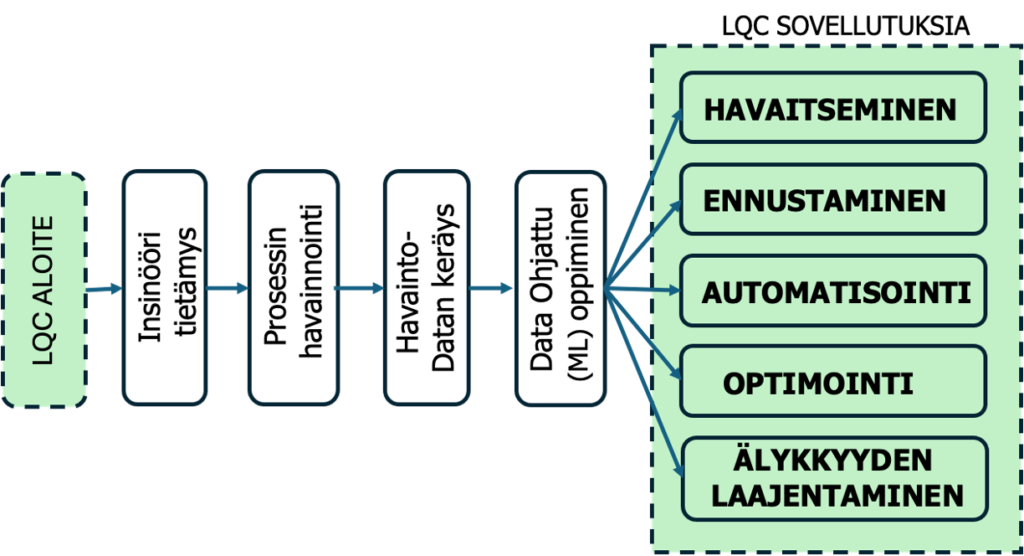
- Havaitseminen (Luokittelu): Sovelluksessa kehitetään koneoppimismalli viallisten osien havaitsemiseksi ulostulossa Y. Valmistuksen aikaiset poikkeavat osat ja prosessiarvot (x) havaitaan ja tunnistetaan ja opetetaan MLA:lle (Machine Learning Algoritm) suhteessa Y:n. MLA oppii hyvälaatuiset ja vialliset signaalit (x:t) ja käyttää koulutettua luokittelijaa signaalien havaitsemiseksi reaaliaikaisesti ulostulossa Y.
- Ennuste (Luokittelu, Regressio): Sovelluksessa kehitetään malli tulevien tapahtumien ennustamiseksi prosessin alkuvaiheessa havaitun datan perusteella. Tyypillisesti linjalla havaitsemattomat merkittävät poikkeamat nimellisarvosta leviävät ja vahvistuvat loppupäässä, mikä aiheuttaa laatuun liittyviä ja vaikeasti korjattavia ongelmia lopullisessa kokoonpanossa. Regressioluokittelumalli ennustaa varhaisista prosessin ongelmista ja mahdollisista kertyvistä loppupään ongelmista. Niiden korjaaminen myöhemmin on kallista ja aikaa vievää, koska keskeneräisten tai valmiiden tuotteiden määrä voi olla liian suuri.
- Automaatio (Luokittelu): Tätä sovellusta varten kehitetään malli korvaamaan monotonisia ja triviaaleja tehtäviä, kuten objektien tunnistusta. Yleensä ihmistarkastajat suorittavat visuaalisia laaduntarkastuksia (luokitteluja hyvä, viallinen) tuotantolinjalla. Nämä valvontajärjestelmät ovat usein alttiita käyttäjien luontaisille ennakkoluuloille ja väsymykselle, jotka johtuvat tehtävän toistuvasta luonteesta; siksi niiden tarkkuus valmistuksessa on noin 80 % [251]/14/.
- Optimointi (Regressioluokittelu): Sovellusta varten kehitetään malli koneen parametrien optimoimiseksi. Optimoidut parametrit saattavat parantaa prosessin suorituskykyä ja laatua. Huomaa kohdassa 2 mainitut Douglas Montcomeryn virhepäätelmät. Parametriyhdistelmiä on äärettömän monta. MLA:ta käytetään input parametrien ja prosessin lopputuloksen välisten lineaaristen ja epälineaaristen suhteiden oppimiseen. Lopullinen malli voidaan kehittää perinteisillä tilastollisilla menetelmillä, kuten vastepintamenetelmää (RSM, DoE)
- Ihmisen älykkyyden laajentaminen (Luokittelu, regressio): Sovellusta varten kehitetään luokittelumalli herkkyysanalyysien suorittamiseksi. MLA oppii monimutkaiset lineaariset ja epälineaariset suhteet riippumattomien muuttujien ja kiinnostuksen kohteena olevien muuttujien välillä. Tämän jälkeen ML malli koulutetaan niin, että mallilla voidaan nopeuttaa vianetsintää. Datan systemaattinen laskennallinen analyysi mahdollistaa älykkyyden luomisen kaikilla valmistuksen osa-alueilla. Älykkyys ilmenee strategisina toimina, ennusteina, optimointeina, simulaatioina sekä älykkäänä valvontana ja ohjauksena. Valmistusprosesseja seurataan reaaliajassa, mikä mahdollistaa oikea-aikaiset säädöt ja toimenpiteet tuotteen laadun hallitsemiseksi. Lisäksi data tukee virheellisten toimintaolosuhteiden juurisyiden nopeaa diagnosointia.
Seuraavaksi käsitellään tarkemmin LQC yhtä sovellutusta, joka koskee havaintodataan liittyvään luokitteluun ja sen käyttöön laadunohjauksessa ja valvonnassa.
5. Binäärisen luokittelijan kehittäminen tarkastuksen tehostamiseksi
Perinteisesti laadunohjaus/-valvonta on luottanut vahvasti ihmisen suorittamaan tarkastukseen ja tilastollisiin menetelmiin. Neljäs teollinen vallankumous on tuonut monimutkaisempia ja vaativampia tuotteita ja paljon havaintodataa. Tämä muutos on kyseenalaistanut nykyisen tarkastuksen/luokittelun suorituskyvyn estää virheiden etenemisen prosessissa ja edelleen valumisen asiakkaille. Pelkkä tuotteen ”osittainen” luokittelu 20-40 %:n oikeellisuudella hyviin ja huonoihin ei riitä!
Laatu 4.0 aloite tuo tarkastukseen koneoppimisella luodun binääriluokittelijan tehostamaan toimintaa ja vähentämään tarkastusvirheitä (tarkastuksen oikeellisuus >95 – 99,9%). Tarvitaan avuksi prosessissa tapahtuvien muutoksien antamaa ennusteluokittelua.
Laadunohjaus ja -valvonta on kehitetty tunnistamaan vialliset/huonot materiaalit, osat, prosessivaiheet ja tuotteet/palvelut. Se on siis vastapaino tuotannolle, joka on keskittynyt tuottamaan mahdollisimman tehokkaasti tuotteita – hyviä ja huonoja. Tämä asetelma aiheuttaa organisaatiossa voimakkaan ristiriidan organisaatioiden välille. Tuotanto tuottaa ja tarkastus hylkää samat tuotteet! Tyypillisesti virheellisesti hylättyjä on 20 – 30% (α-virhe). Tämä tulee esille erityisesti monimutkaisten ja vaativien osien ja tuotteiden osalta, jos tarkastus ja hylkäys ei tukeudu faktaan. LQC lisää hylkäykseen ja hyväksymiseen faktapohjaa ja objektiivisuutta ja saattaa pudottaa virheellisten hylkäysten määrän lähelle 0 % – ja lisätä tuotantomäärää 20-30%:a. Lisää osassa 4.
Molemmat toiminnot – tuotanto ja tarkastus – ovat tilastollisia tapahtumia, joihin liittyy tilastollinen epävarmuus. Tämä epävarmuus, jos sitä ei tiedosteta, synnyttää tämän ristiriidan. Ristiriita ilmenee erityisesti silloin, kun organisaatio ei ole selvittänyt tarkastuksen oikeellisuutta faktapohjalta; määrittänyt tarkastuksen α- ja β- virhettä, sekaannusmatriisia. Sekaannusmatriisi on keskeinen työkalu suunniteltaessa binääriä laadun luokittelua, LQC.
5.1. Miten binäärinen laatuluokittelija toimii?
Binäärisen luokittelijan kehittäminen alkaa datan luomisella ja keräämisellä linjan työntekijöiltä, eri antureista, kameroista tai muista valmistusprosessiin integroiduista laitteista. Nämä datat sisältävät useita ominaisuuksia, kuten virheen ilmenemismuotoja, mittoja, lämpötiloja, paineita, kosteuksia ja abstraktimpia ”mittauksia”, kuten kuvia tai signaaleja.
Jokainen datanäyte ja sitä vastaava valmis osa/tuote merkitään joko ”hyväksi” tai ”vialliseksi” ennalta määritettyjen kriteerien perusteella. Datanäytteet tai osa voidaan myös mitata ja käyttää tätä mittausarvoa opetettaessa ”tietokonetta”. Tätä prosessia kutsutaan annotoinniksi.
Merkittyjen (label) tietojen (tietueiden) avulla koulutetaan tietokoneelle/softalle binääristä luokittelumallia, tyypillisesti käyttäen koneoppimisalgoritmeja. Koulutuksessa tarvittavien tietueiden määrää ei voi tarkkaan sanoa – sadoista tuhansiin tietueisiin (≈10xominaisuuksien määrä). ML algoritmit oppivat tunnistamaan datasta malleja, jotka vastaavat kahta luokkaa (1 ja 0). Esimerkiksi hitsausprosessissa energiaa mittaavan anturin tehosignaali voi esittää eri muotoja, kun hitsaus on hyvä verrattuna siihen, kun se on viallinen.
Kun malli on koulutettu, se voi ennustaa, antaa prognoosin, uusien tehtävien osien/tuotteiden laadun reaaliaikaisen datan perusteella ja luokitella jokaisen kohteen joko ”hyväksi” tai ”vialliseksi” opetetun mallin perusteella.
5.2. Luokittelijan ulostulomittari Y ja sekaannusmatriisi
Laatuongelmien binäärisessä luokittelussa positiivinen tulos li= 1 viittaa vialliseen osaan/tuotteeseen ja negatiivinen tulos (0) hyvälaatuiseen osaan/tuotteeseen.

Laatuluokitteluun liittyy sekaannusmatriisi (confusion matrix) ja totuustaulukko (taulukko 1 ja 2), jolla kuvataan luokittelijan ennustekyvyn todennäköisyyttä. Luokittelussa tulos voi sekaantua kahdella tavalla virheellisiin tuloksiin (α- ja β-virhe).
Taulukko 1. Sekaannusmatriisi eli confusion matrix luokittelijan (kaavan) mukaan

- Tosi negatiivinen (hyvä) (TN= True Negative; TH= Tosi Hyvä): Se viittaa hyvälaatuiseen kohteeseen, jonka luokittelija on ennustanut oikein.
- Tosi positiivinen (viallinen) (TP=True Positive; TV= Tosi Viallinen): Se viittaa vialliseen kohteeseen, jonka luokittelija on ennustanut oikein.
- Väärä positiivinen (hyvä) (VP= False Positive; VH= Virheellinen Hyvä): Se viittaa hyvään kohteeseen, jonka on virheellisesti ennustettu vialliseksi. Tilastollisesta näkökulmasta tyypin I eli a-virhe kertoo VH:n todennäköisyyden.
- Väärä negatiivinen (viallinen) (FN= False Negative; VV= Virheellinen Viallinen): Viittaa vialliseen tuotteeseen, jonka on virheellisesti ennustettu olevan hyvä. Tilastollisesta näkökulmasta tyyppi II eli b-virhe kertoo VV:n todennäköisyyden.
Taulukko 2. Totuustaulukko (sekaannusmatriisi) ilman luokittelija merkintöjä negatiivinen, positiivinen. Taulukossa suom. ja eng. lyhenteet

Alfa- ja betavirheet (α ja β) ovat tärkeitä. α-virhe- tai väärien positiivisten prosentti kuvaa luokittelijan tehokkuutta viallisten kohteiden havaitsemisessa. Sitä vastoin β-virhe- tai väärien negatiivisten prosentti kuvaa luokittelijan likinäköisyyttä vähemmistöluokan havaitsemisessa.
Tuotanto pyrkii minimoimaan α-virheen β kustannuksella luokittelemalla ”kaiken” mahdollisen hyväksi ja laaduntarkastus pyrkii minimoimaan β-virheen α-virheen kustannuksella tulkitsemalla ”kaiken” mahdollisen virheelliseksi. Katso taulukko 1 ja kuva 9.
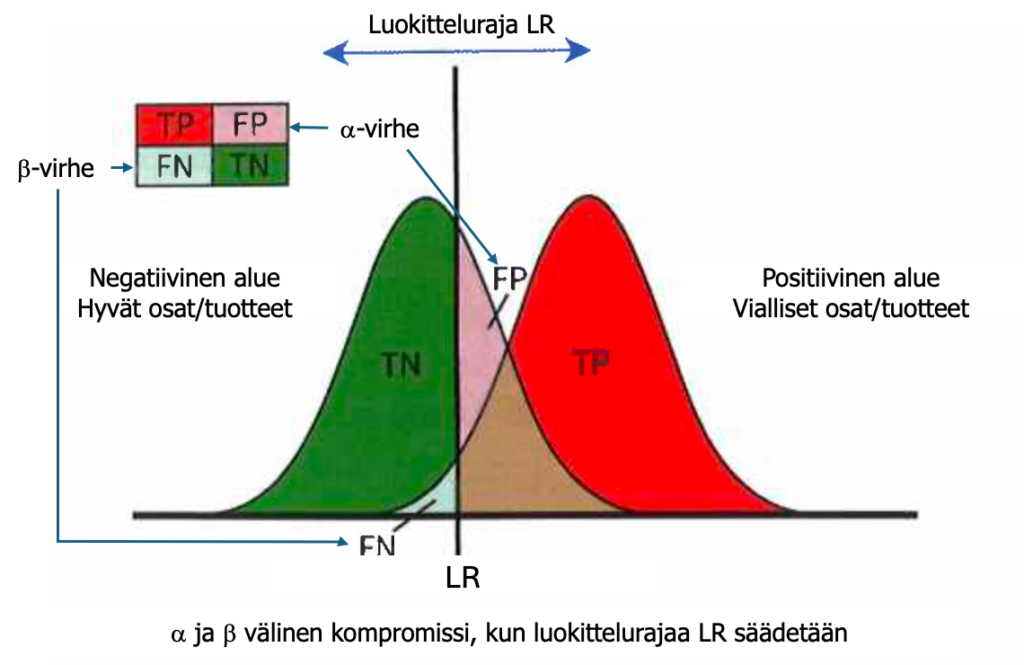
Sekä hyvien että huonojen osien/tuotteiden vikajakaumat ovat osittain päällekkäin (kuva 12). Näiden jakaumien erottaminen toisistaan tapahtuu luokittelurajalla (LR). Luokittelurajan paikka (ja sen epämääräisyys, mittausvirhe) muodostaa kompromissin, jota kuvataan sekaannusmatriisilla ja α- ja β-virheprosenteilla. Luokittelurajaa ja sen vaihtelua muuttamalla voidaan vaikuttaa merkittävästi hyvien ja huonojen keskinäisiin suhteisiin.
Riippuu yrityksestä ja sen omaksumasta laatupolitiikasta, miten asiakkaille meneviin virheisiin suhtaudutaan. Autoteollisuus asettanut Nolla-virhe tavoitteen eli FN≈β=0! Tarkoittaa, että hyvien ja huonojen ”väliin” muodostetaan turvavyöhyke ja hyväksytään suurempi α-virhe. Vertaa autoteollisuuden erilaiset automallien takaisinvedot ja tarkastukset!
Eri tutkimusten mukaan vain n. 10 % tarkastuksista on automaattisia ja 90 % tarkastuksista on manuaalisia/visuaalisia. Näiden manuaalisten/visuaalisten tarkastusten oikeellisuus on n. 40 – 80 %, jopa huonompi. Tästä on raportoitu lukuisissa Six Sigma -raporteissa ja myös kirjassani s. 156/9/, jossa totean ”Tarkastusprosessin hyväksymisprosenttia (oikeellisuutta) on vaikea nostaa yli 30 – 40 %”. Viittaan myös tutkimukseen, jossa Hitchiner pystyi luomaan tarkastusprosentin, jossa valukappaleiden oikeellisuus saatiin nosemaan n. 20%:sta lähellä 70 % :a.
5.3. LQC-prosessi/2/
LQC ongelmanratkaisu voidaan kuvata viidellä vaiheella – Tunnista, Havaitse, Data, Opi, Suunnittele uudelleen tai yksityiskohtaisemmin 7-vaiheella – Tunnista, Aavista (havaitse), Löydä data, Opi datasta, Ennusta, Suunnittele uudelleen, Opi uudelleen; Identify, Acsensorize (Observe), Discover Data, Learn Data, Predict, ReDesign, ReLearn (IADLPR2).
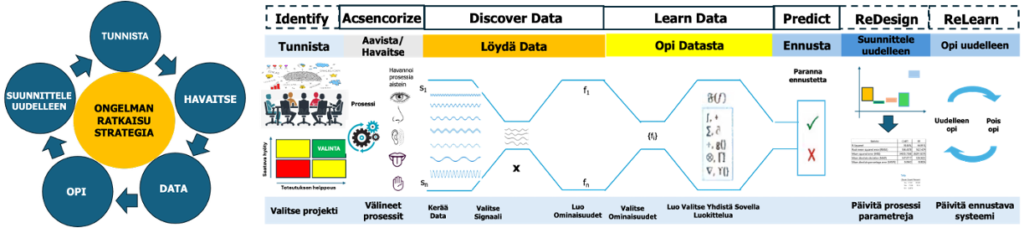
5.3.1. Tunnista: valitse projekti (Identify)
LQC:n ja Laatu 4.0 -projektin onnistuminen riippuu ensisijaisesti johdon kyvystä tunnistaa ja valita arvokkaita/vaikuttavia projekteja, joilla on onnistumisen todennäköisyys suuri. Tämän haasteen ratkaisemiseksi on kehitetty 18 kysymyksen lista, josta voi muodostaa painotetun projektipäätösmatriisin. Matriisi noudattaa Lean Six Sigmasta tuttua mallia.
Seuraavassa kysymykset, joita voi painottaa eri projekteille 0, 1, 3, 9 ja laskea summat yhteen kullekin projektiehdokkaalle. Mitä suurempi painotettu summa, sitä parempi projekti.
- Voidaanko ongelma muotoilla binääriseksi luokitteluongelmaksi?
- Mikä on projektin kannattavuus?
- Ovatko ennustajaominaisuudet x käytettävissä?
- Ovatko ennustajaominaisuudet tallentaneet kaikki vaihtelun lähteet?
- Ovatko ennustajaominaisuudet vahvasti yhteydessä projektin taustalla olevaan fysiikkaan?
- Ovatko koulutusdata (eli otoskoko) riittävän suuria?
- Käyttäytyykö järjestelmä kaoottisesti?
- Ovatko laatumerkit (hyvä, viallinen) käytettävissä?
- Jos laatumerkkejä ei ole, kuinka kauan niiden luominen kestää?
- Voidaanko takuutietoja käyttää?
- Onko projekti linjassa tiimin kokonaisstrategian ja asiantuntemuksen kanssa?
- Kuinka vaikeaa ratkaisun toteuttaminen olisi tehtaan dynamiikan ja rajoitusten (esim. jaksoaikojen) kannalta?
- Mikä on yrityksen/tehtaan vaatimusten (eli a, b virhettä)) kannalta ongelman ratkaisemisen todennäköisyys?
- Kuinka kauan se kestäisi?
- Ovatko koneoppimismenetelmät sopivampia kuin muut perinteiset tilastolliset laadunohjausmenetelmät?
- Koska ennustaminen ei välttämättä tarjoa tietoa syy-seuraussuhteista, onko mitään arvoa ennustamisessa ilman syy-seuraussuhdetta?
- Voiko tämä projekti hyödyntää/mahdollistaa useampia projekteja?
- Ottaen huomioon tietotekniikan, liiketoimintatiedon ja kuvailevien tilastojen projektien luonteen, edistääkö tämä projekti oppimista, tukeeko se automaattisia päätöksiä ja ohjausta?
Kysymyssarjan painotetun arvon lisäksi käytetään nelikenttäanalyysiä: Takaisinmaksu – Vaikeus

Koneoppimisella luotu LQC luokittelija antaa uuden mahdollisuuden luoda tarkastus, jonka oikeellisuus on ”dekadin” parempi kuin manuaali/visuaalisessa tarkastuksessa erityisesti niiden osien/ tuotteiden osalta, joita ei voida ”rikkomatta” tarkastaa ja niiden, jotka ovat monimutkaisia ja sisältävät hyperparametrisiä vikatiloja. Tästä seuraa suoraan vähemmin asiakasreklamaatioita, asiakasvalituksia ja takuukustannuksia.
Kuvassa (15) luokittelusäännön kehitysprosessi tuotannon ulkopuolella (offline) ja suora soveltaminen (online) kuvassa.
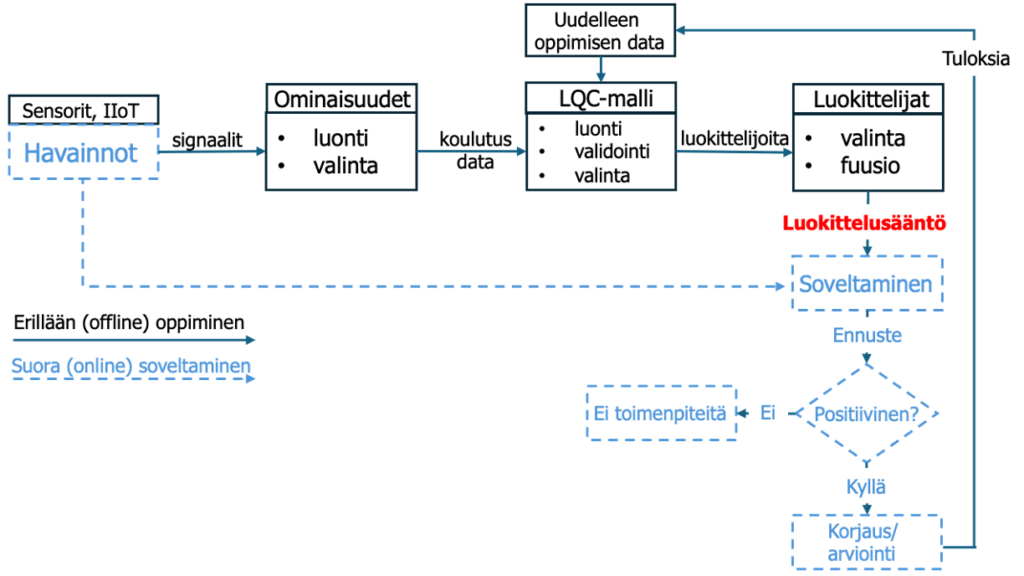
Luokitteluprosessin tuloksena syntyy sääntö, jolla virheelliset tuotteet erotellaan tuotantovirrasta. Yritys voi painottaa haluamallaan tavalla α ja β virheiden osuutta LQC-mallissa.
5.3.2. Havaitse, aavista, aksonerisoi: välineet, prosessit (Observe, Ascencorize)
Tämän vaiheen päätavoitteena on luoda kyky havainnoida tuoteominaisuutta prosessissa. LQC ehdottaa järjestelmän aksonerisointia (eli havainnointia) raakadatan tuottamiseksi. Arviointi edellyttää kaikkien saatavilla olevien tietovirtojen listaamista, joita prosessista on saatavissa tai joita prosessille on mahdollista saada, jota ei ole vielä otettu käyttöön.
Vaiheen päätavoitteena on myös määrittää ihmiset ja laitteet, joita voidaan käyttää tiedon tuottamiseen, ja määritellä tiedonsiirron tietoliikenneprotokollat.
Mitä dataa prosessi voisi tuottaa ja miten viestintä toteutetaan. Tämä vaihe esiintyy myös SPC:n ja laatutaulujen yhteydessä arvioitaessa tuotteen stabiilisuutta. Mistä saada ohjauskortteihin dataa, joka ilmaisee epästabiilisuuden? Mistä saada muuttujadataa, joka ennustaisi luokittelijan tilan?
Ensimmäinen ratkaisu on kysyä linjan/prosessin työntekijöiltä, missä ja mitä virheitä/poikkeamia olette havainneet valmistusprosessin aikana tehtävissä osissa/tuotteissa/palveluissa? Todennäköisesti nämä poikkeamat ovat tärkeitä, koska työntekijät ovat ne huomanneet. Kuvaan Laatutaulua käsittelevässä kirjassa/10/ ja artikkelissa: Laatutaulu – Osa 4: luominen, tiedon keruu ja käyttöönotto – teoriasta käytäntöön poikkeaminen keräys- ja merkitsemisprosessia (label) tarkemmin. Jos prosessin muuttujat eivät ole ihmisaistien mitta-alueella, on käytettävä erilaisia herkempiä mitta-antureita. Oleellista on myös, että poikkeamat merkitään tuotenumeron tai vastaavan alle. X:t on voitava jäljittää Y mukaan.
Laatutauluissa virheen ilmenemismuotojen (=ominaisuus, feature) alle työntekijät keräävät poikkeamia, mutta laatutaulumenettelyssä ei ole jäljitettävyyttä Yi:stä xi:n, koska laatutaulujen luomishetkellä (1986) ei ollut mitään tilastollista analyysimenetelmää kuten nyt koneoppimismalli. Tämä kaikki tai osittain voidaan tehdä erilaisilla antureilla ja mittalaitteilla. Anturit lisäävät järjestelmän monimutkaisuutta, laskenta- ja arkistointikuormitusta. Siksi on välttämätöntä tehdä harkittu anturivalinta. Jotkut havaittavat fyysiset ominaisuudet, kuten mitat, virta, jännite, lämpötila, paine jne., voidaan havaita suoraan. Ei-havaittavat ominaisuudet voitaisiin päätellä havaittavien mittausten yhdistelmästä, kuten pehmeissä antureissa. Parhaat anturit ja päättelymenetelmät ovat sellaisia, joilla on maksimaalinen ero signaali- ja kohina-aliavaruuksien välillä ja riittävä erottelukyky.
Kerätty data voidaan usein siirtää langattomasti, jos kaistanleveysvaatimus on riittävän pieni. Aidosti langaton anturi on kuitenkin sellainen, jossa on joko sisään-rakennettu energialähde tai joka voi kerätä energiaa. Kerätyn datan tulisi olla siirrettävissä käyttämällä avoimia standardiprotokollia.
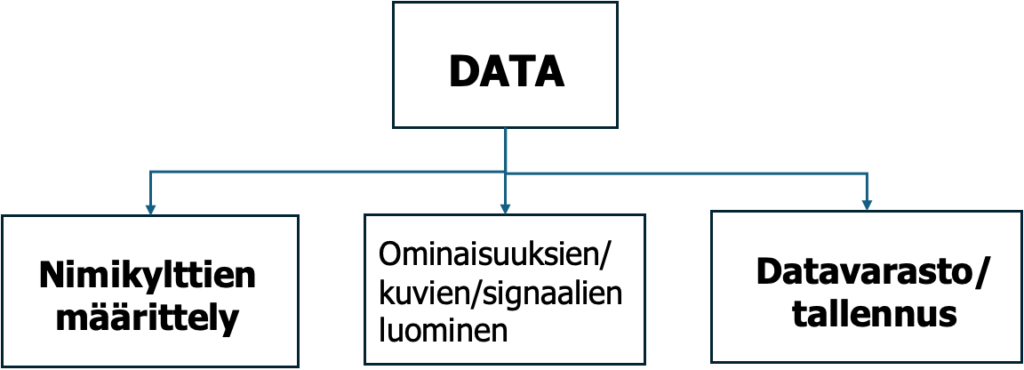
5.3.3. Data: kerää data, valitse signaali, luo ominaisuudet (Discover Data)
Tämä vaihe sisältää ominaisuuksien (feature), signaalien tai kuvien luomisen ja kunkin näytteen merkitsemisen (label, nimikyltti).
Ominaisuudet luodaan, data merkitään ja kerätään nimikylttien (label) alle. Katso kuva 5. Ominaisuuksien suunnittelu on yksi koneoppimisen tärkeimmistä vaiheista. Kuva 17.
5.3.4. Opi: valitse ominaisuudet, luo valitse yhdistä sovella luokittelua (Learn)
Luokittelijan kehittämisessä datasta oppiminen on päätavoite Tämä toiminta sisältää useiden luokittelijoiden (algoritmien) kouluttamista ja testaamista. Algoritmit kehittyvät voimakkaasti ja niitä on valtavasti erilaisiin käyttötarpeisiin. Satunnaistetut metsät (RF) on hyvä lähtökohta, joka on Minitabissa. Esittelin sitä osassa 2. Luokittelija käyttää reaaliaikaista havainnointidataa, joilla se projisoi jokaisen valmistetun tuotteen 1:ksi tai 0:ksi (viallinen, hyvä). Tästä yhteydestä luodaan malli y=f(x).
Valmistuksesta peräisin olevan datan binääriseen laatuluokitteluun liittyy useita haasteita: (1) hyperulotteiset ominaisuusavaruudet (2) erittäin epätasapainoinen data (viallisten luokkien määrä < 1 %), (3) numeeristen ja kategoristen muuttujien sekoitus (eli nominaalinen, ordinaalinen tai dikotomiset), (4) erilaiset tekniset asteikot, (5) epätäydelliset datajoukot ja (6) aikariippuvuus.
Seuraavassa käsitellään edellä olevia ongelmia kolmessa ryhmässä: (1) esikäsittely, (2) luokittelijan kehittäminen ja (3) käyttöönottohaasteet.
5.3.4.1. Esikäsittely
Ominaisuuksien (feature) luomisen jälkeen seuraa datan esikäsittely, jossa data puhdistetaan ja parannetaan (annotointi). Tyypilliset työkalut ja menettelyt:
- Tutkiva data-analyysi: luokkajakauma-analyysi, ominaisuusjakauma ja parittainen analyysin sekä poikkeavien arvojen (erityissyiden) tunnistaminen jne. auttavat kehittämään tehokkaan datajoukon ja oppimisstrategian.
- Numeerisen datan muuntaminen: useimmat ML algoritmit toimivat vain numeerisen datan kanssa. Siksi on tärkeää kehittää strategia kategoristen muuttujien käsittelemiseksi eli koodata ne numeeriseen muotoon.
- Puuttuvien tietueiden analysointi: On tärkeää ymmärtää puuttuvan datan mekanismi, jotta puuttuvaa dataa voidaan käsitellä tehokkaasti. Rivien tai sarakkeiden poistaminen on laajalti käytetty lähestymistapa puuttuvien datojen yhteydessä. Tätä menetelmää ei suositella, jos poistettujen tietueiden osuus ei ole hyvin pieni (<5 %). Puuttuvien tietueiden imputointi on parempi lähestymistapa. Imputointi tarkoittaa tilastotekniikan prosessia, jossa keinotekoisia arvojen lisäämistä ja puuttuva data korvataan arvatuilla/arvioiduilla arvoilla.
- Ominaisuuksien valinta: Poista epäolennaiset ja tarpeettomat ominaisuudet. Tämä parantaa yleistämistä, helpottaa tiedonkeruuta ja tiedon poimintaa, lyhentää laskenta-aikaa ja pienentää dimensionaalisuuden vaikutusta.
5.3.4.2. Luokittelijan kehittäminen
Tämän vaiheen päätavoitteena on kehittää luokittelija. Tämä toiminta sisältää useiden ML-luokittelijoiden kouluttamisen ja testaamisen. ML-algoritmeja on suuri joukko. Näiden joukosta pyritään löytämään paras algoritmi. Minitab tarjoaa yleisen työkalun Minitabin koneoppimis algoritmien vertaamisen ja valintaan. Näistä osassa 1.
5.3.4.3. Käyttöönoton haasteet
ML-algoritmin koulutuksen aikana luodut sisäiset ratkaisut/mallit ovat usein ylioptimistisia, koska ratkaisut luodaan tiukasti kontrolloiduissa olosuhteissa. Nämä olosuhteet eivät todennäköisesti ole täysin edustavia tehdasympäristölle. Malli voi ylisovittaa koulutusdataa (eli oppia virheellisiä kuvioita), mikä johtaisi alhaiseen yleistyssuorituskykyyn. Tästä syystä pilottiajot ovat välttämättömiä harhattoman yleistyssuorituskyvyn saavuttamiseksi.
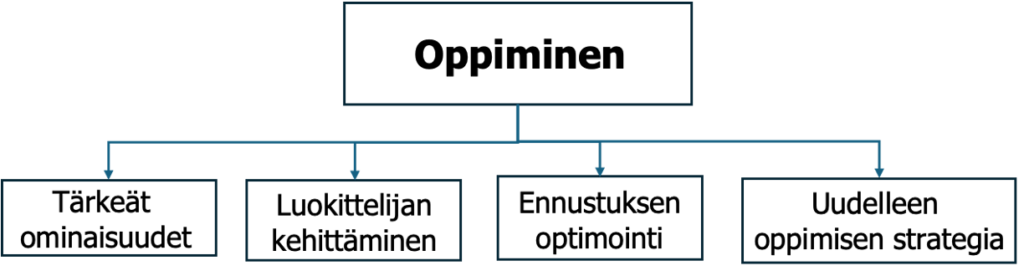
5.3.5. Ennusta (Predict)
Ennustuksen optimointi on tämän vaiheen päätavoite. Kun monipuolinen joukko luokittimia on kehitetty, seuraava luonnollinen askel on tutkia erilaisia yhdistelmämenetelmiä ennustuksen parantamiseksi. Lukuisia erilaisia mittareita on kehitetty algoritmien suorituskyvyn arvioimiseksi. Osassa 2 oli taulukko (taulukko 4), jossa akkuliuskojen malleja on tarkasteltu.
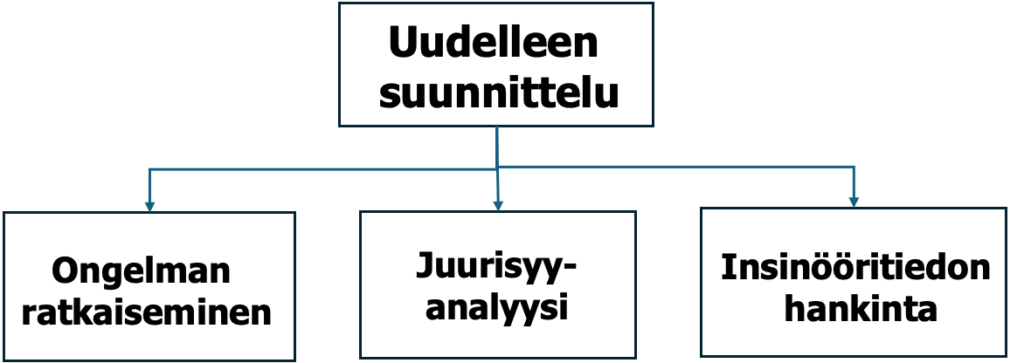
5.3.6. Suunnittele uudelleen (ReDesign)
Empiirinen tiedonhankinta on tämän vaiheen päätavoite. Onko luokittelija tulosten perusteella suunniteltava uudelleen? Tuotannosta ja asiakkailta saadut tulokset esitetään suunnittelutiimille analysoitavaksi ja tulkittavaksi. Ryhmä tutkii, onko luokittelijan suorituskyky riittävä asetettuihin tavoitteisiin. Tuote/palvelu, olosuhteet ja ympäristö on saattanut muuttua.
5.3.7. Opi uudelleen (ReLearn)
Uudelleenoppimisstrategian kehittäminen on tämän vaiheen päätavoite. Ensimmäinen kehitetty käytettävän malli on vasta alkua, koska malli yleensä heikkenee käyttöönoton jälkeen. Uusi malli on kehitettävä ”jatkuvan parantamisen” periaatteella.
6. Joitain luokittelijan sovellutuksia
Laadun tarkastuksia tehdään laajalti ennen tuotantoa, sen aikana ja sen jälkeen. Tarkastus ovat edelleen erittäin riippuvaisia ihmisen kyvyistä luokitella oikein.
Binäärisen luokittelijan kehittämisen tarkoituksena on reaaliaikaisen prosessidatan käyttö prosessien automaattiseen seurantaan ja hallintaan, eli virheiden tunnistamiseen ja poistamiseen. Tämä on uusi idea ja myös mahdollisuus.
Tällä tekoälyn ja koneoppimisen sovelluksella voidaan merkittävästi parantaa tarkastuksen/luokittelun suorituskykyä ja samalla automatisoida tuotantoa. Perustavoitteena on oppia tarkastajien suorittama toistuva, yksinkertainen käsite, mikä on hyvä tuote ja mikä huono. Tämä tehtävä muotoillaan binääriseksi luokitteluongelmaksi ja edelleen ennustavaksi malliksi.
6.1. Vikojen ennaltaehkäisy
LQC:tä voidaan käyttää vikojen ennustamiseen ennen niiden ilmenemistä tai niiden havaitsemiseen niiden syntymisen jälkeen. Tähän on käytetty erilaisia laatutekniikan juurisyyanalyysejä – 8D, A3, 5 Miksi jne. Kaikille näille tyypillistä on, että ”parannusideat” luodaan ja keksitään datan sijaan.
LQC:lla ideat haetaan luokittelijan luoman mallin avulla havaintodatasta. Näiden kahden eri menetelmän vertailusta ei ole näyttöä. Sen sijaan on näyttö kokeellisen datan (DoE, Six Sigma) ja ideoihin perustuvien juurisyymenetelmien välillä. Kokeellisen datan etu on murskaava!
Binääriluokittelua käytetään vikamallien tunnistamiseen prosessidatasta, samalla kun normaali malli pidetään stabiilina. Jos vikamalli havaitaan (eli luokittelija tuottaa positiivisen tuloksen), se käynnistää tekniset toimet tilanteen korjaamiseksi. Johtopäätösten perusteella voidaan aikatauluttaa huoltoa, muuttaa prosessiparametreja tai tarkastaa raaka-aine-eriä.
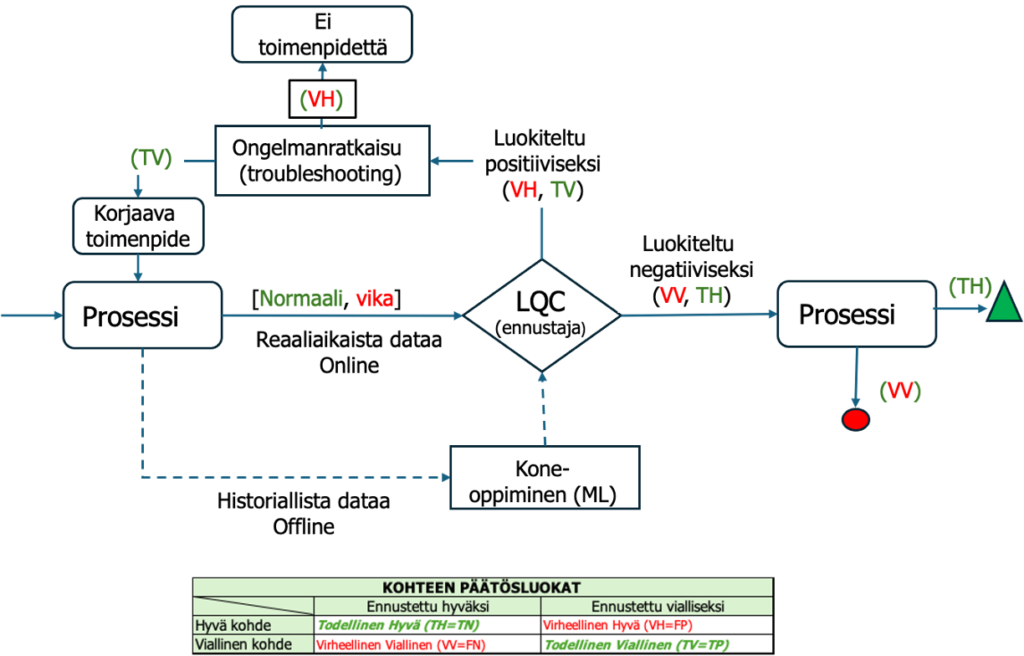
6.2. Luokittelijalla (tekoälyllä) tehostettu SPC/SQC kohde- ja lopputarkastus
Tilastollisesti hallinnassa olevassa prosessissa käytetään LQC:tä havaitsemaan ne muutamat vialliset (VV), joita SPC/SQC-järjestelmä ei havaitse, jotta voidaan luoda käytännössä virheettömiä prosesseja.
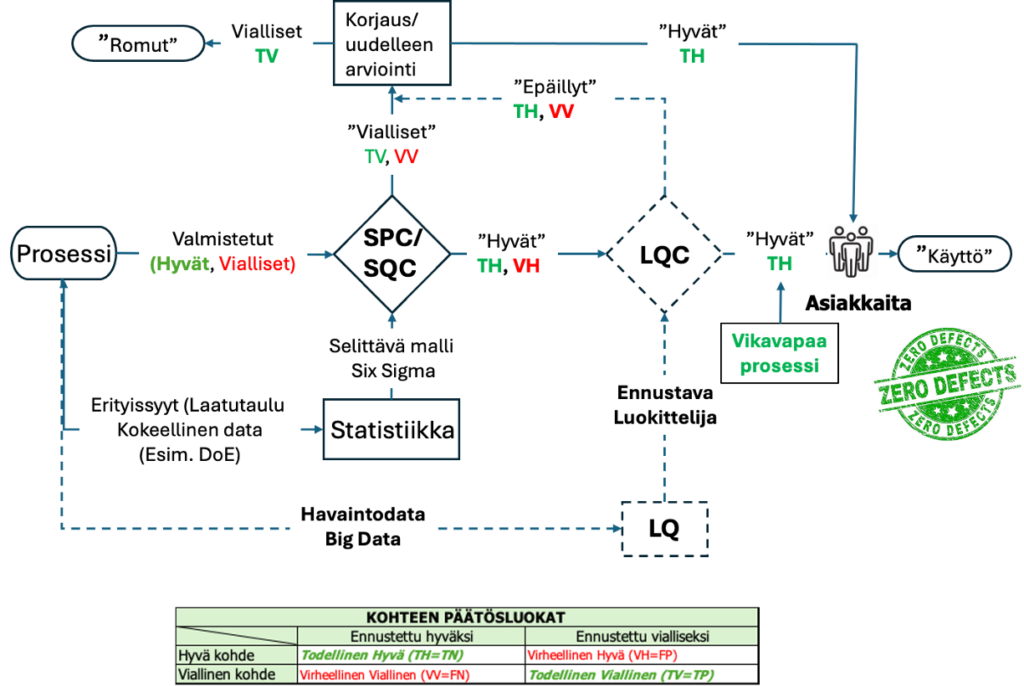
Kuva kuvattuna lajittelijalla (LQC) varmistettu SPC/SQC -tarkastus. Myös manuaali-/visuaalitarkastusta voidaan varmentaa LQC:llä. LQC ennustaa jokaisen tuotteen prosessissa tapahtuvien poikkeamien, ominaisuuksien (virheiden ilmenemismuotojen) perusteella. LQC mahdollistaa poikkeaman korrelaatiosyyn ennustamisen (ongelmanratkaisu)!
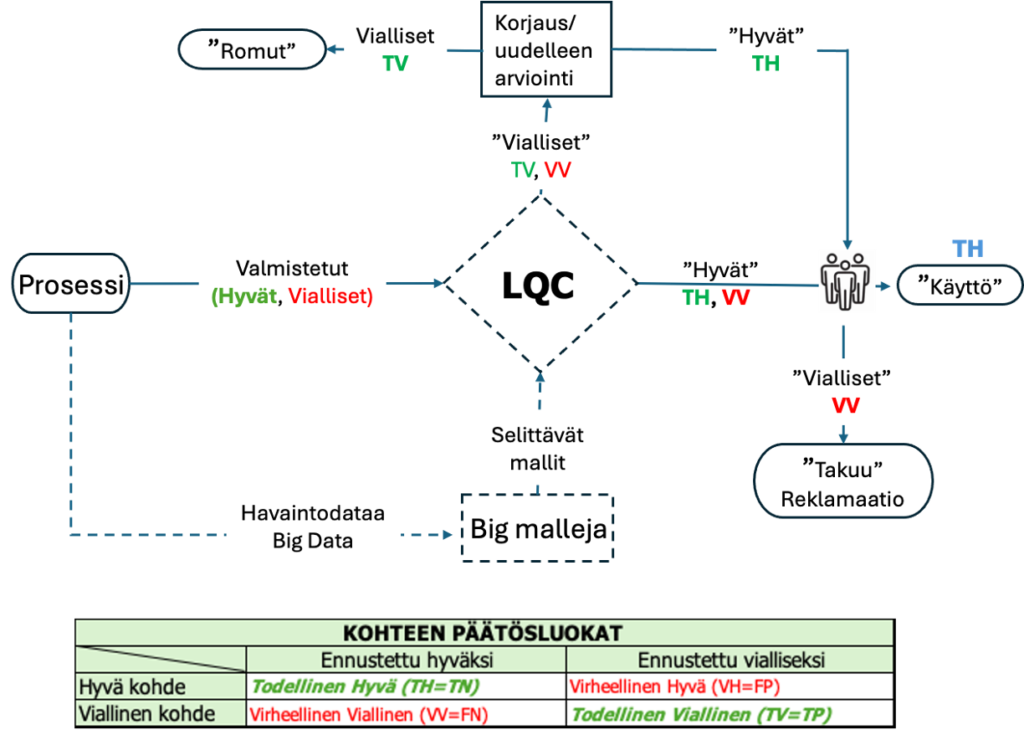
6.3. Luokittelijalla (LQC) totutettu laadunvalvonta ja ohjaus
Teollisuudessa on lukuisia sovellutuskohteita, joissa toimii vain luokittelija. Tyypillisiä on ei-rikkovat testit ja kohteet, joita ei voida tarkastaa ilman että tuote tuhoutuu. Toinen luokka on tuotteet, joita tarkastetaan näyteperusteella. Esimerkkinä vaikkapa erilaiset juomat, pakatut elintarvikkeet, jotka valmistuvat suljetuissa astioissa – viinit, konjakit, valmisruuat ja muut vastaavat. Ratkaisuksi jää tehokkaan prosessiluokittelijan luominen, jos halutaan varmistaa (ennustaa) jokainen tuote eikä vain erää, josta otetaan ehkä tilastollinen näyte. Tällöin tietysti on luotava järjestelmä, joka kerää prosessidatan jokaisesta valmistuvasta tuotteesta jäljitettävyysdatan.
Luokittelija mahdollistaa myös automatisoida tarkastustoiminnan. Tarkastuksen (luokittelun) tehokkuus määrittää lopullisen tarkastuksen tuloksen ja paljonko se ”vuotaa” viallisia/virheellisiä tuotteita asiakkaille.
7. Yhteenveto
Yli 30 vuotta sitten kehitetty Lean Six Sigma -ohjelman on ollut edelläkävijä massatuotettujen tuotteiden laatufilosofialle. Nykyään Lean Six Sigma Black Belt ja Green Belt -sertifioidut tutkijat ja insinöörit ratkaisevat monimutkaisia juurisyyongelmia kaikilla liiketoiminta-alueilla. Vaikka Lean Six Sigma -filosofia on edelleen välttämätön, se ei voi tehokkaasti/vaikuttavasti vastata joihinkin teollisen Big Datan aiheuttamiin haasteisiin.
Laatu 4.0 on seuraava luonnollinen askel laadun kehityksessä. LQC-ongelmanratkaisu laajentaa datakenttää havaintodataan ja luo prosessin koneoppimiselle (ML). Esimerkiksi LQC:n soveltaminen binääriseen luokittelijaan on erityinen sovellutus, jolla voidaan parantaa merkittävästi tarkastusvaiheiden ja lopputarkastuksen oikeellisuutta käyttämällä prosessista saatua havaintodataa ennustamaan, onko tuote viallinen vai hyvä.
Kuten artikkelista ilmenee, Laatu 4.0 on mallinnustekniikka, joka perustuu empiiriseen havaintodataan. Se on eräänlainen DoE/Lean Six Sigmaan laajennus koedatasta havaintodatan reaaliaikaiseen analysointiin.
Tämä artikkeli tarjoaa vision siitä, miten Laatu 4.0 -aloite käynnistetään ja mihin LQC:tä voi käyttää ja mihin erityinen sovellutus, luokittelija, perustuu.
Seuraavassa artikkelissa syvennän edelleen oppikokonaisuutta – Laatu 4.0 – Master Black Belt, Black Belt, Green Belt ja Yellow Belt -koulutus ja sen rakenne.
Varhaiset tekoälyn ja koneoppimisen – Laatu 4.0 – soveltajat ovat niitä, jotka johtavat tulevaisuuden yrityksiä!
Lähteet:
- Eero E. Karjalainen, Artikkeli: Laatu 4.0 ja Lean Six Sigma 2.0 (2018)
- Carlos A. Escobar, Ruben Morales-Menendes: Machine Learning in Manufacturing – Quality 4.0 and the Zero Defects Vision (2024)
- Avigdor Zonnenshain, Ron S. Kenett: Quality 4.0—the challenging future of quality engineering, Quality Engineering (2020)
- Carlos Alberto Escobar Diaz: Beyond DMAIC: Leveraging AI and Quality 4.0 for Manufacturing Innovation in the Fourth Industrial Revolution, Quality Magazine (2024)
- Douglas C. Montgomery: Exploring observational data, Quality Reliability Engineering (2017)
- Eero E. Karjalainen, Artikkeli: Kausaliteetti-syy on ehto parannukselle – mitä se on? (2020)
- Soumyadeep Saha: Understanding Decision Trees: Algorithms, Splits, and Interpretability, Medium (2025)
- Guillaume Coqueret, Tony Guida Machine Learning for Factor Investing R Version (2020) (Tree-based methods (https://www.mlfactor.com/trees.html)
- Eero E. Karjalainen, Tanja Karjalainen: Lean Six Sigma 2.0 ja laatuteknologia (2020)
- Eero E. Karjalainen, Tanja Karjalainen: Laatutaulu – Tehokas menetelmä laadunohjaukseen ja parannukseen (2024)
- Wuest, T., Irgens, C., & Thoben, K.-D. An approach to monitoring quality in manufacturing using supervised machine learning on product state data. Journal of Intelligent Manufacturing (2014)
- Eero E. Karjalainen, Artikkeli: Koneoppimisesta (ML) ja Laatutaulusta (SPC) – Osa 1 (2026)
- Eero E. Karjalainen, Artikkeli: Laatu 4.0 – Oppivalla laadunohjauksella (LQC) parempaan laatuun – Osa 2 (2026)
- See JE: Visual inspection reliability for precision manufactured parts, Human Factors, 2015.

Tutustu kurssitarjontaamme!


Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.