
Koneoppimisesta (ML) ja Laatutaulusta (SPC) – Hallitsetko riskiä vai parannatko laatua?
Tekoäly (AI, Artificial Intelligence) ja koneoppiminen (ML, Machine Learning) on tuomassa uuden sivun ja uudet mahdollisuudet laadunvarmistukseen, ohjaukseen, parannukseen ja riskin hallintaan.
Älykäs valmistus (SM, Smart Manufacturing)) on aloittanut uuden aikakauden, jossa teknologisia innovaatioita käytetään valmistusprosesseissa. Tämän seurauksena prosessit monimutkaistuvat nopeasti. Monet perinteisten laadunohjauksen menetelmät, tekniikat ja myös paradigmat, hyväksytyt laatuopit- ja toimintamallit, eivät enää pysty käsittelemään uusien valmistustapojen seurauksia ja niiden synnyttämiä virheitä. Nyt AI ja ML yhdessä pystyvät ratkaisemaan uusia ongelmia mm. rakentamalla moniulotteisia ennustemalleja tuotteen ja palvelun prosessista saatavasta suorasta havainto- ja mittausdatasta. Tämä on uutta! Tämä on uusi mahdollisuus!
Sisältö:
- Johdanto
- Koneoppiminen ja taulu
- Klassinen laatutaulu
- Korrelaatio ja kausaliteetti
- Ennustava malli Minitabilla
- Ennustava malli osana koneoppimista (Machine Learning)
- Koneoppimisen keskeiset sovellukset valmistuksessa
- Esimerkki sovellutuksesta – Laatutaulu
- Ennustemallin valinta ja laskenta
- Yhteenveto
- Lähteet
1. Johdanto
Tilastollisella oppimisella on jo nyt keskeinen rooli monilla tieteen, rahoituksen ja teollisuuden aloilla. Voimme Six Sigmalla (DoE) rakentaa mallin erityisellä tavalla kerätystä datasta (esim. ortogonaalimatriisi), mutta nyt koneoppiminen mahdollistaa mallin tekemisen suoraan ja välittömästi prosessin poikkeamien havaintodatasta.
Tässä esimerkkejä oppimisongelmista/1/):
- Ennusta (predict), saako sydänkohtauksen vuoksi sairaalaan joutunut potilas toisen sydänkohtauksen. Ennusteen tulee perustua kyseisen potilaan demografisiin tietoihin, ruokavalioon ja kliinisiin mittauksiin.
- Ennusta (predict) osakkeen hinta 6 kuukauden kuluttua yrityksen suorituskykymittareiden ja taloudellisten tietojen perusteella.
- Ennusta (predict) diabeetikon verensokerimäärää henkilön veren infrapunaspektrin perusteella.
- Ennusta (predict) eturauhassyövän riskitekijät kliinisten ja demografisten muuttujien perusteella.
…
- Ennusta (predict), onko valmistuva tuote hyvä tuotannon aikana kerätyn poikkeamatiedon perusteella.
- Ennusta (predict) reklamaation todennäköisyys valmistuvalle tuotteelle tuotannosta kerätyn datan perusteella.
- Ennusta (predict) tuotannon läpimenoaika tuotannon prosessi- ja asetusaikojen, varastotasojen, keskeneräisen työn ja virhe- ja korjaustietojen perusteella.
Oppimisen tieteellä (science of learning) on keskeinen rooli uudessa tilastotieteessä, tiedonlouhinnassa ja tekoälyssä, ja se liittyy Teollisuus 4.0:n ja Laatutekniikan Laatu 4.0:n. Teollisuus 4.0 ja Laatu 4.0 tarkoittaa Teollisuus 4.0 -teknologioiden, kuten tekoälyn, esineiden internetin (IoT) ja big datan, soveltamista laadunhallintaan.
Laatu 4.0 on neljäs aalto laatuliikkeessä (1. Tilastollinen laadunohjaus (SQC/SPC), 2. Kokonaisvaltainen laadunhallinta (TQM), 3. Six Sigma (≈ DoE), 4. Laatu 4.0 (≈ ML). Laatu 4.0 laatufilosofia perustuu aiempien filosofioiden tilastollisille ja johtamisperiaatteille lisättynä sen tuomat uudet ajatukset. Se hyödyntää teollista big dataa (IBD, Industrial Big Data) ja tekoälyä ratkaistakseen kokonaan uudenlaisia ratkaisemattomia teknisiä ongelmia. Laatu 4.0 paradigma perustuu empiiriseen oppimiseen, empiiriseen tiedonhankintaan sekä reaaliaikaiseen tiedon tuottamiseen, keräämiseen ja analysointiin älykkäiden päätösten mahdollistamiseksi. Uutta laadunohjausta kutsutaan Oppivaksi laadunohjaukseksi (Learning Quality Control, LQC)/2/.
Havaintodatan ennustemallit (predective models) paljastavat, mitkä pienet satunnaiset havaitut valmistus- tai palvelutekijämuutokset, prosessimuutokset, (≈empiirinen data) ovat yhteydessä lopputuotteen tai palvelun pienten muutosten kanssa. Yhteyttä kuvataan termillä korrelaatio. Malli kertoo, mihin input tekijöihin (x) pitäisi keskittyä, jotta tuotteesta tai palvelusta Y tulee hyvä. Mallilla voi varmistaa ja ohjata laatua, hallita riskiä ja edesauttaa parannusta. Koneoppimismalleja käytetään automaattiseen vian tai virheen tunnistukseen, ennakoivaan kunnossapitoon ja reaaliaikaiseen prosessien optimointiin. Koneoppimisesta on tulossa valmistuksen ja palvelun laadunvarmistuksen uusi kulmakivi SQC/SPC:n ja lopputarkastuksen rinnalle tai jopa sen sijaan. Miksi tarkastaa ja valita hyvät huonoista, jos prosessissa oleva tuote- tai palveluvirta kuvaa/ennustaa lopputuloksen ilman epävarmaa ja kallista tarkastusta! Miksi kärsiä asiakasvalituksista ja reklamaatioista, jos ne ”tiedetään”, voidaan ennustaa, jo prosessimuutoksista välittömästi!
Mallin tekemiseen tarvitaan vain prosessista oikein kerättyä havaintodataa kuten ”laatutauluissa”, joita olen esitelty artikkeleissa /3, 4, 5, 6, 7, 8/ ja/tai laatutaulua käsittelevässä kirjassamme /9/. Laatutaulu sinänsä on vanha, mutta sen data ja datarakenne on mitä oivallisin koneoppimisen vaatimaan raakadataan. Erilaiset sensorit ja automaattiset anturit (esim kamerat, mittaus- ja kosketusanturit) ja/tai työntekijät voivat kerätä suoraan poikkeamadatan (≈ virheen ilmenemismuoto x) tuote- ja palveluvirrasta (suoraan tuotteesta) valmistusprosessin aikana. Poikkeama suunnitelmasta/speksistä voidaan ilmaista joko hyvä/huono (attribuutti) tai mittaamalla vaatimuksia vastaan (variaabeli) tai näiden yhdistelmänä. Tällöin käsitellään yksittäistä tuote-/palveluaihiota. Toinen mahdollisuus on koota päivän tulokset keskiarvoiksi tai lukumääriksi. Dataa voi tulla paljon!
Tästä datasta ja tähän liittyvästä ulostuloista voidaan tehdä monia erilaisia malleja opettamalla ”kone”, softa. Tätä kutsutaan koneoppiseksi (ML). Voidaan kysyä esimerkiksi, mitkä pienet poikkeamat tuote- tai palveluaihioissa (komponenteissa valmistuksen aikana) korreloivat valmiisiin hylättyihin tai hyviin tuotteisiin/palveluihin. Samoin voidaan selvittää läpimenoon, tuotantomäärään, saantoon, reklamaatioihin, asiakasvalituksiin liittyviä korrelaatioita muutaman mainitakseni. Oletus tietysti on, että tuotteilla tai palveluilla tai ryhmällä on jäljitystunnus kuten ihmisellä sotetunnus.
Oikeastaan minkä tahansa ilmiön Y ennustemalli voidaan luoda, jos on mahdollista kerätä muuttujadataa x (jatkuvaa ja/tai luokiteltua dataa) kyseisen Y:n suhteen taulukkomuotoon. Matemaattisesti ilmaistuna etsimme funktiot f-yhtälöön Y=f(xi). Käytän tietoisesti sanaa korrelaatio vaikuttamisen sijaan. Nämä kaksi käsitettä ovat osin eri asioita. Korrelaatio koskee ”tätä päivää” ja kausaliteetti, vaikuttaminen, ”huomista”. Korrelaatio toteaa yhteyden. Kausaliteetin olemassaolo mahdollistaa huomisen muuttumisen, parannuksen. Korrelaatio voi ilmaista kausaliteetin tai ei ja kausaliteetti voi ilmetä korrelaationa tai ei. Molemmille voidaan tehdä ennusteita.
2. Koneoppiminen ja taulu
Koneoppimismalli luodaan fyysisen taulun tai taulumuotoon kerätyn tietokantadatan avulla. Data voidaan kerätä suoraan tuote- tai palveluaihion poikkeamista (≈virheen ilmenemismuoto) tai tuote- ja palveluaihiota muokkaavista prosessin muutoksista tai näiden yhdistelmistä.
Esimerkiksi jos ajat autolla vaikkapa Lahdesta Helsinkiin. Haluat mallintaa matka-ajan Y=f(x). Auton reitin/paikan/matkan voi mitata GPS-signaalista esim. 1 min välein eli n. 60 paikkatietoa (saraketta/matka ja Y (aika). Ajat tämän reitin 200 kertaa tai mittaat 200 autosta. Saat ”taulun”, jossa on 60 + 1 saraketta ja 200 riviä. Dataa yhteensä 12200 kpl. (Huom: dataa voi kerätä myös muista tekijöistä kuin edetystä matkasta; sää, vireystila jne.) Tästä voi tehdä koneoppimismallin.
Vaihtoehtoisesti voisit tehdä kokeellisen DoE-parannusmallin, kuten Matti Pesonen on artikkelin esimerkissä näyttänyt. Katso esimerkki artikkelista: Kokeellinen oppiminen.
Todennäköisesti käytät kuitenkin tiekarttoja tai modernimmin kysyt ehkä matka-ajan Google Maps -sovellutuksesta vai navigaattorilta … mutta tämä on eri asia kuin DoE tai koneoppimismalli (ML). Kartat ja navigaattori tarjoavat deduktiivisen mallin, joka mahdollistaa optimoinnin, valinnan parhaasta reitistä. Katso artikkeli ja esimerkki /10/.
Ensimmäinen on tuote-/palvelukohtainen mittaus ja koneoppimismalli (ML), joka perustuu välittömään prosessissa syntyvään dataan (poikkeamiin). Siinä mukaan tulee sinun yksilöllinen ajotapasi. Toinen tapa mallintaa on DoE-malli, joka mahdollistaa parantamisen. Siinä teet tietoisia, etukäteen suunniteltuja muutoksia reittiin ja muihin tekijöihin. Kolmas malli on deduktiivinen malli, jossa ennustaminen tapahtuu ennalta asetettujen tie nopeuksien ja matkojen perusteella.
Taulua voidaan käyttää minkä tahansa koneoppimismallin luontipohjaksi. Tauluun kerätään prosessissa havaittuja poikkeamia joko tuote-/palvelukohtaisesti tai kaikkien prosessissa kulkevien tuotteiden ja palvelujen summalukuna tai keskiarvona (esim. kpl/päivä, keskiarvo 12,3 mm/päivä).
Taulun datankeräysrakenne on yleinen analyysirakenne, jota kaikki ohjelmistot suosivat. Dataa käytetään joko riveittäin, sarakkeittain. Minitab 22 laskee sarakkeittain. Taulu voisi siis olla ”Laatutaulu”, ”Läpimenotaulu”, ”Tuotantomäärätaulu”, ”Tuotteen lujuustaulu”, ”Asiakastyytyväisyystaulu”, ”Myyntitaulu”, ”Sydänsairaustaulu” tai yleensä mikä tahansa ulostulon tavoitetaulu, joka halutaan mallintaa (ennustaa) välittömästä prosessidatasta.
Taulun kerätään tuotteen, tuotesarjan, palvelun edetessä erilaista parametritietoa x – jatkuvaa ja/tai luokiteltua-, joiden uskotaan korreloivan (olevan yhteydessä) esim. laatuun, läpimenoon, läpimenoaikaan, tuotantomäärään, tuotteen lujuuteen, kustannuksiin, asiakasvalituksiin, sairauksiin jne. tuote-/henkilö-, päivä-, viikko- tai kuukausitasolla.
Esimerkkinä lääketieteellisestä sovellutuksesta on sairaus esim. sydänsairaus (No, Yes), joka halutaan ennustaa ihmisistä (=tuotteesta/palvelusta) mitattujen poikkeavien veri- ja terveystietojen perusteella. Minitab-esimerkki CART-analyysistä https://support.minitab.com/en-us/minitab/help-and-how-to/statistical-modeling/predictive-analytics/how-to/cart-classification/before-you-start/example-of-cart-classification/ Taulukossa osa Minitab-worksheetille kerätyistä datoista ”Sairauden ennustamistaulu”.
Taulukko 1. Minitab-data sydänsairauteen mahdolliset tekijät x ja sydänsairaus ei/on. Osa tekijöistä on jatkuvia ja osa diskreettejä, laadullisia muuttujia. (Minitab) Esimerkkiä käsitellään Minitab-kursseillamme tarkemmin.
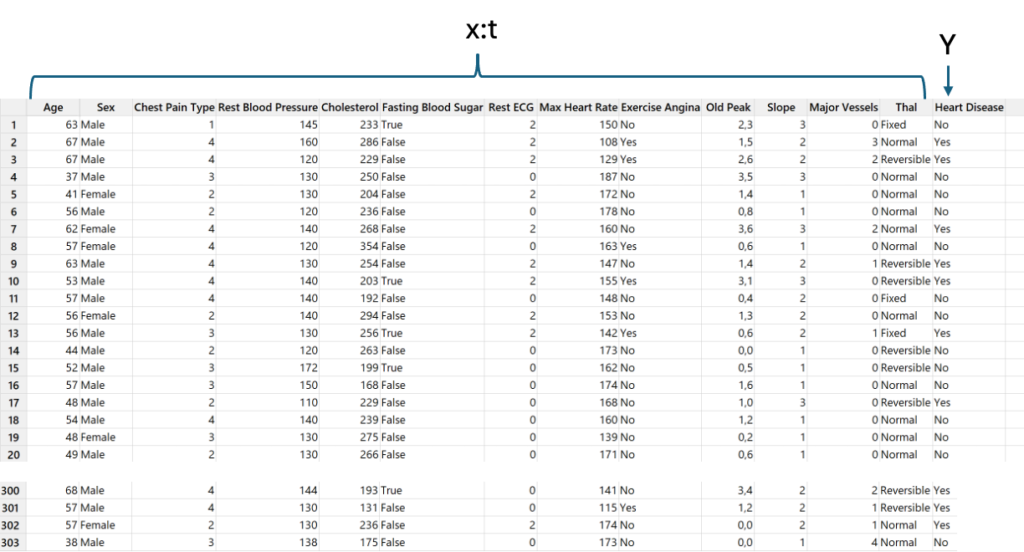
Myös yksittäisen koneen tai (palvelu)prosessin osalta voidaan kerätä koneen mittareissa olevia käyntiarvoja x (parametri), palvelun olosuhdemuuttujia (parametri) ja mitata samanaikaisesti vastaavien yksittäisten tuotteiden/palveluiden ulostuloja Y joko onnistuminen, epäonnistuminen (0, 1) tai mitattavalla suureella (m, kg, tyytyväisyys 1-5 jne). Näiden x:n ja Y:n välille voidaan muodostaa (Minitab laskee ja valitsee) koneoppimismallin. Dataa olisi oltava 30-200 riviä, mieluimmin >2000, jotta tietokone/ohjelma voidaan opettaa ja opetettu malli testata datalla. Erillisiä parametrejä voi olla ≈ 5-100 ja jopa enemmän.
3. Klassinen laatutaulu
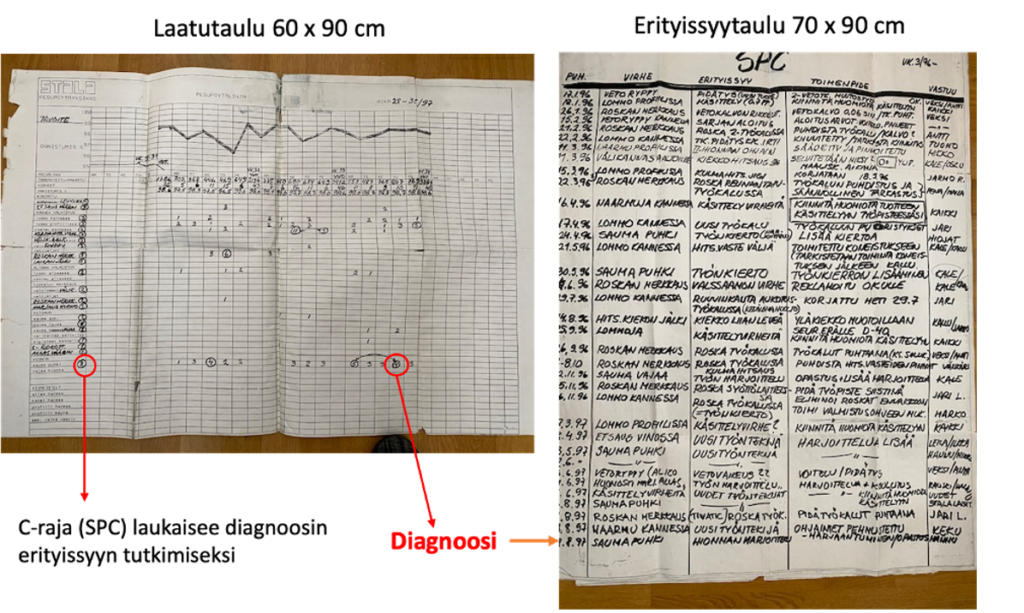
Laatutaulussa on konkreettisesti kuvattuna tuotteen poikkeamia, joita työntekijät ovat havainneet ja löytäneet prosessivirrassa kulkevasta tuoteaihiosta. Kutsun näitä virheen ilmenemismuodoiksi. Tässä on esimerkkinä pesupöytien valmistusprosessi. (Kuva 1) Datalla on sama rakenne, kuin Koneoppimisen datankeräystaulukoissa. Katso artikkelisarja Laatutauluista/3,4,5,6,7,8/ ja/tai Laatutaulua käsittelevästä kirjastamme/9/.
Laatutauluissa painopiste on ollut 1980-luvulta asti erityissyyanalyysi (SPC), koska muuta tehokasta analyysiä ei ollut käytettävissä. Analyysi tapahtuu poikittain ajansuuntaan (disagregation). Analyysi perustuu poikkeamien suuruuteen ja aikajärjestykseen. Tutkitaan aikastabiilisuutta! Koneoppimisessa analyysi tapahtuu pitkittäin datan suuntaan (stratification). Datan aikajärjestys ei vaikuta. Tutkitaan korrelaatiota. Tähän asti laatutaulun ”koko” dataa ei ole voitu analysoida. Nyt koneoppiminen mahdollistaa koko datan analysoinnin – erityissyyt ja satunnaissyyt.
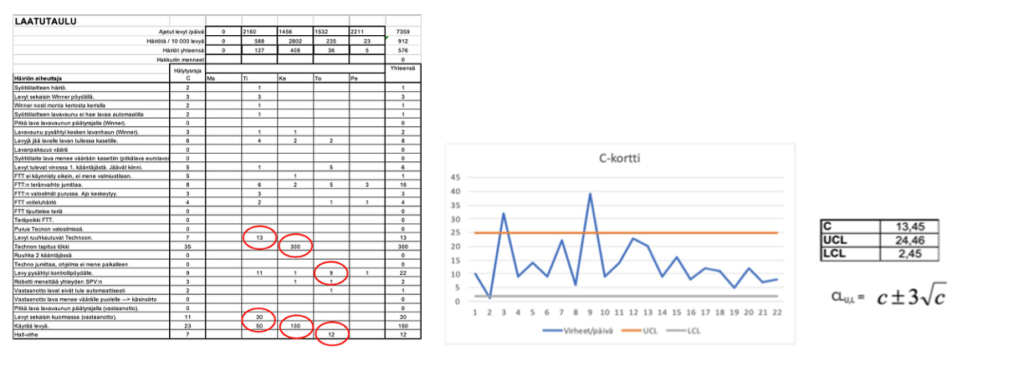
SPC-analyysin tarkoituksena oli ja on erotella korrelaatio kausaliteetista ja helpottaa erityisesti kausaliteetin (≈juurisyy) löytymistä prosessista. Löydetty kausaliteetti, juurisyy, ilmaistaan erityissyytaulussa. Tämän kausaalianalyysin keksi tri Walter A. Shewhart vuonna 1924/14/, kuten olen useissa SPC:tä ja Laatutaulua koskevissa artikkeleissa esittänyt ja käytännössä koetellut 40 vuoden ajan. Tarkemmat tulokset kirjassamme ja artikkelisarjassa.
Laatutaulun keskeisin kritiikki on kohdistunut kysymykseen: Miksi emme ole tutkineet kaikkia virheitä, poikkeamia, hukkia, jotka tuote- ja palveluaihioista, prosessivirrasta, havaitaan? Eikö kaikki virheet pidä tutkia ja tehdä korjaava toimenpide? Miksi yleensä teemme tällaisen joidenkin mielestä turhan ja ”työlään” jaon? Kritiikin vasta-argumentteja ei läheskään kaikki hyväksy. Luonnontieteellinen fakta kuitenkin on, että lähellä keskiarvoa olevien poikkeamien (± 3 sigmaa) juurisyitä (kausaali) ei voida suoraan datasta päättää, vain korrelaatiot. Koneoppimisella yhdessä SPC:n kanssa voidaan tuotteen ja palvelun syntymekanismista luoda korrelaatio- ja kausaalitekijät. Tästä muodostuu uusi laadun paradigma, Oppiva laadunohjaus (LQC). Korrelaatioilla ohjataan ja varmistetaan ja kausaalitekijöillä parannetaan. Satunnaisesta vaihtelusta kausaalitekijät löytyvät DoE:lla (Lean Six Sigma)!
Koneoppimisen datavaatimus on, että siinä ei saisi olla erityissyitä. Siksi koneoppiminen tarvitsee tuekseen SPC:n takaamaan x:n, parametrien stabiilisuuden. Koneoppimisen malli on korrelaatiomalli, jolla ohjaaminen onnistuu. Mallilla ei voi parantaa/muuttaa. Jos näin tehdään, se johtaa epästabiilisuuden kasvamiseen ja tilanteen huononemiseen, peukalointiin eli tampering-ilmiöön (Deming). Virheet ja reklamaatiot kasvavat. Korrelaatiot saattavat kyllä joskus johdattaa meidät todellisten syiden löytämisen polulle. Syyrakenne, todellinen vaikuttaminen, voidaan löytää vain satunnaistetuilla kokeilla/16,17/.
4. Korrelaatio ja kausaliteetti
Laadunohjauksen ja parannuksen ongelman ydin ja vastaus on havaintodatan ja kokeellisen datan perimmäisen luonteen sekoittaminen toisiinsa.
- Havaintodata johtaa korrelaatioiden/assosiaatioiden tunnistamiseen ja nykytilan ennustemalliin (ML) ja mahdollistaa tietoisen riskijohtamisen. Havaintojen perusteella voit arvioida nykytilan riskiä ja mitä tuleman pitää, mutta et muuta. Voit yrittää hallita riskiä – sääennuste kertoo, pitääkö sateenvarjo ottaa mukaan, jotta ei kastu! Voit ohjata omaa kastumistasi!
- Satunnaistettu kokeellinen data (DoE) (≈rationaalinen data) johtaa ”piilossa” olevan kausaliteettirakenteen ja tärkeimpien kausaliteettien löytämiseen ja ohjaavaan malliin (prescriptive model) ja edelleen suorituskyvyn parannukseen, kun teet halutun muutoksen. Voit optimoida mallilla tulevaisuutta ja laatia analyyttisen ennusteen muutoksen kausaalivaikutuksesta.
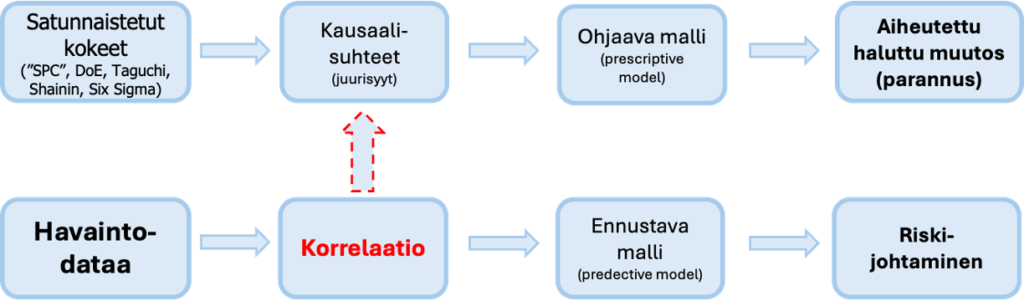
Kuva artikkelista/20/: ”Correlation to Causality”. Artikkelin case käsittelee kausaliteetin etsimisestä 3D-kappaleen tulostusprosessissa syntyvän tuotteen lujuuden optimointiin. 53:sta parametristä vain 3 osoittautui merkittäväksi kausaalitekijäksi, joilla voi lujuutta muuttaa/optimoida! Muut ovat korrelaatioita. Aika tyypillinen suhde 3/53 = 5,6 % syyehdokkaista, parametreista on kausaalitekijöitä, joilla parannus onnistuu. Suosittelen tutustumaan artikkeliin ja sen antamiin viitteisiin!
Muistathan: Jäätelönsyönti korreloi hukkumisiin – lopettamalla jäätelönsyönti, hukkumiset vähenevät! Pariisin haikaranpesien määrä korreloi vastasyntyneiden määrään. Siis haikarat tuovat lapset! Haikaranpesiä rakentamaan. Ethän usko sokeasti korrelaatioihin.
SPC (laatutaulu) kuuluu satunnaistettujen datojen ryhmään, koska se perustuu rationaaliseen näytteenottoon ja datan aikajärjestys säilyy. SPC ei ole varsinainen satunnaistettu suunniteltu koe (DoE), vaan eräänlainen välimuoto. SPC keksittiin vuonna 1924 ja R. A. Fisher loi kokeet vuonna 1935. SPC:ssä luodaan ohjausrajat historiadatasta. Rajat, ”koe” asetetaan tuleville datoille. Tavallaan tapahtuu ”kokeellista” testausta ja analysointia. Jos testi osoittaa rajan ylityksen tai alituksen, muutoksen takana (tai hyvin lähellä) on kausaliteetti/juurisyy ja interventio onnistuu. Kuvan 2 ”yläriviä” olemme käsitelleet lukuisissa artikkeleissamme.
Siis mitä voimme tehdä prosessista syntyvälle havaintodatalle, siis sille osalle, jossa ei ole erityissyitä? Onko data hyödytöntä ja täysin analysoimatonta? Vastaus on ja ei. Jokainen tuntee loton ja on nähnyt TV:stä yksinkertaisen lottokoneen, joka synnyttää viikoittain havaintodataa. Tästä ei voi analysoimalla luoda hyödyllistä ennustavaa mallia, joka kertoisi seuraavan viikon oikean rivin, vaikka tuntisimme pallon pyörähdysajan, suunnan, arpojien nimet, valaistuksen ja muut x:t. Mutta ehkä sinun oma prosessisi ei ole niin hyvin rakennettu kuin lottokone. Se saattaa mahdollistaa ennustavan mallin rakentamisen Minitabin uudella Predictive Analytics Module -valikolla.
5. Ennustava malli Minitabilla
Vuonna 2021 Minitab tilasto-ohjelmaan tuli Predictive Analytics Module -valikko, jolla koneoppimismallin vaatimia algoritmejä voi ajaa. ML-algoritmeja on yli 200 eri tarkoituksiin ja lisää luodaan koko ajan. Ala on voimakkaan kehityksen alla.

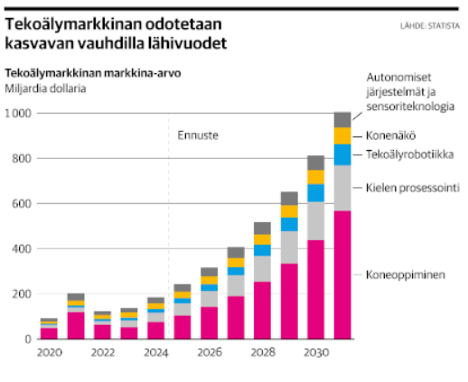
Kehitystä kuvaa Kauppalehdessä 18.9.2025 esitetty tekoälyn markkinoiden kehitys. Suurin kasvava osuus on Koneoppimisella (ML). Kielimallien (AI) markkinat ennustetaan paljon pienemmiksi.
6. Ennustava malli osana koneoppimista (Machine Learning)
Ennustavan mallin eli korrelaatiomallin luominen tuotantoprosessin havaintodatasta on ollut haastavaa näihin päiviin asti. Tilastosoftat eivät ole aikaisemmin tukeneet mallin rakentamista ja laskentaa kuin regressiomallien osalta. Olen yrittänyt käyttää regressiomalleja 1980-90 -luvuilta asti, mutta lähes aina tuloksena on, että mallia ei voi luoda. Regressio ei usein onnistu datassa olevien vahvojen outlierien (≈erityissyiden) ja korrelaatioiden vallitessa. Nämä ja muutkin ongelmat voidaan kiertää luokittelu- ja puuanalyysillä. Huom: satunnaistetuissa kokeissa (DoE, Taguchi) ongelmat kierretään ortogonaalimatriiseilla/16, 17/.
Ensimmäiset askeleet luokitteluun perustuvien mallien luonnissa loi tri L. Breiman vuonna 1984 ja edistyneemmät algoritmit 2010-luvulla. Vuonna 2021 Minitab-ohjelmistoon tuli mallin rakentamisessa tarvittavat algoritmit: mm. CART Classification ja CART Regressio puumallit, TreeNet, Random Forrest, MARS ja automaattinen parhaan mallin valinta (Discover Best Model). Katso kuva 3 valikko.
Koneoppimismallit voidaan jakaa kolmeen (neljään) ryhmään: ohjattu oppiminen (supervised) ja ohjaamaton oppiminen (unsupervised) ja näiden muunnelmia kuten puoliohjatut (semi-supervised) ja vahvistusoppivat(reinforsement) mallit/18/. Puoliohjatut mallit ovat yleistymässä. Niitä käytetään usein tekoälysovelluksissa (autot). Ohjattu oppiminen tarvitsee ulostulon Y, kun taas ohjaamattomassa oppimisessa ei ole ulostuloa. Ohjaamattomien (unsupervised) mallien tarkoituksena ei ole luokitella, ennustaa tai arvioida tulevaa liiketoimintatapahtumaa. Taulukossa 2 lueteltuna joitain ohjatun ja ohjaamattoman oppimisen malleja.
Taulukko 2. Ohjatun ja ohjaamattoman oppimisen malleja/18/.
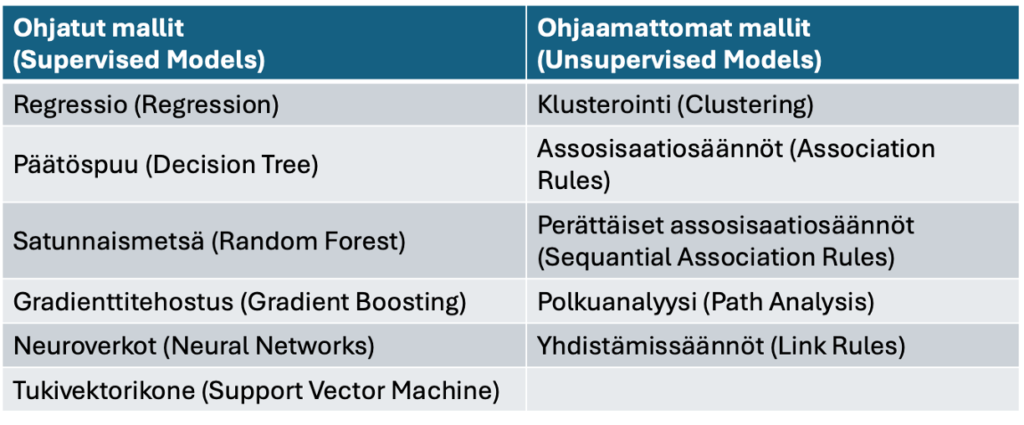
Kuvassa 5 Minitabin koneoppimisen roadmap valintapuu ja edellä mainitut ohjatun oppimisen mallit paitsi Tukiverkkokone ja ohjaamattomista työkaluista Minitab tarjoaa Faktori Analyysin, Pääkomponentti-analyysin, Klusterianalyysin ja K-Keskiarvoklusteroinnin.
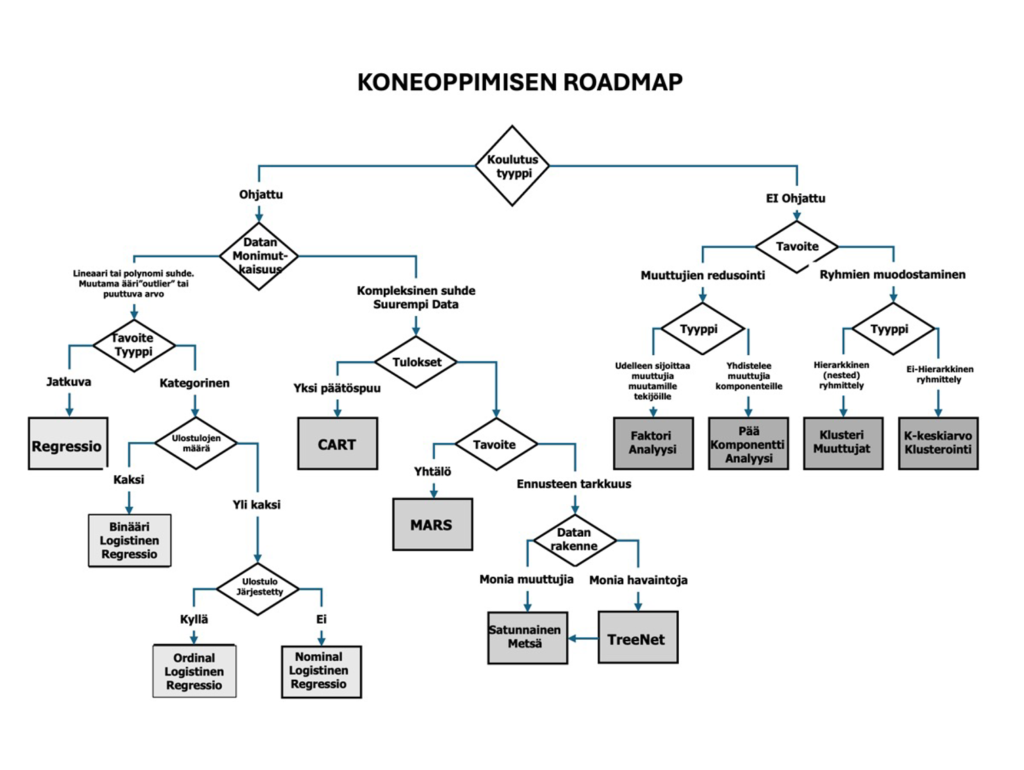
Mallivalintapuussa 5 ohjatut mallit voidaan luokitella neljään pääryhmään:
- Regressio (Regressio) – käytetään nominaalitavoitteiden ennustamiseen (esim 0, 1; kyllä, ei) tai jatkuvien arvojen arvioimiseen. Inputtien (x:t) ja tavoitteen (Y) välisille suhteille ei ole oletuksia. Regressio perustuu regressioanalyysiin.
- Päätöspuu (CART, Classification and Regression Trees) – käytetään nominaali tavoitteiden ennustamiseen (esim 0, 1; kyllä, ei) tai jatkuvien arvojen arvioimiseen. Inputtien (x:t) ja tavoitteen (Y) välisille suhteille ei ole oletuksia. CART perustuu päätöspuuhun.
- Satunnainen metsä (Random Forest ) – käytetään nominaalitavoitteiden ennustamiseen (esim 0, 1; kyllä, ei) tai jatkuvien arvojen arvioimiseen. Syötteiden (x:t) ja tavoitteen (Y) välisille suhteille ei ole oletuksia. Satunnaismetsämalli perustuu useisiin riippumattomiin päätöspuumalleihin, jotka lasketaan samasta datasta. Random Forest on ensemble-menetelmä, joka rakentaa useita päätöspuita. Ennusteet tehdään laskemalla keskiarvo tuloksista tai käyttämällä enemmistöpäätöstä kaikista puista.
- Gradienttitehostus (TreeNet ) – käytetään nominaali tavoitteiden ennustamiseen tai jatkuvien arvojen arvioimiseen. Syötteiden (x:t) ja tavoitteen (Y) välisille suhteille ei ole oletuksia. Gradienttitehostus perustuu päätöspuumallien sarjaan. Gradienttitehostuksen, Stochastic Gradient Boosting, kehitti Jerome Friedman vuonna 1999.
- ”Neuroverkko”malli (MARS, Multivariate Adaptive Regression Splines) – käytetään nominaali tavoitteiden ennustamiseen tai jatkuvien arvojen arvioimiseen. Tämä malli perustuu epälineaaristen moninkertaisten regressioiden lineaariseen yhdistelmään. Useiden syötteiden ja piilotettujen neuronien yhdistelmä mahdollistaa mallin ottaa huomioon syötteiden ja tavoitteen väliset epälineaarisuudet.
7. Koneoppimisen keskeiset sovellukset valmistuksessa/19/
Koneoppimisen sovellutukset ovat vasta nyt muotoutumassa teollisuudessa. Data- ja pankkiteollisuudessa (internet) koneoppimismalleja käytetään jo laajasti erilaisten datahuijausten estämiseen. Kauppalehden 22.8.2025 artikkelin ”Isoja säästöjä teollisuudelle” mukaan tekoälyllä voidaan tehostaa prosesseja 5-10% ja päästöjä jopa 30 %.
- Ennakoiva Laadunohjaus: Koneoppimisella voidaan analysoida mm. tuotannossa syntyvää poikkeamadataa (Laatutaulu) ja kohdistaa toimet oikeisiin ja vaikuttaviin poikkeamiin. Koneoppiminen analysoi tehokkaasti vaikeasti analysoitavaa asiakasvalitus ja reklamaatiodataa. Konenäöllä voi automatisoida monenlaisia kohteita mm. visuaalisia tarkastuksia, havaita viat tarkemmin ja nopeammin kuin ihmistarkastajat, mikä johtaa parempaan tuotteiden laatuun ja pienempään hukkaan.
- Tuotantoprosessin optimointi: Koneoppimisalgoritmit voivat analysoida valtavia määriä dataa pullonkaulojen tunnistamiseksi, tuotantoaikataulujen optimoimiseksi ja tehtaan yleisen tehokkuuden ja läpimenon parantamiseksi (Tehdasfysiikka). Voit laittaa tuotantodatan ”töihin”!
- Toimitusketjun hallinta: Koneoppiminen auttaa ennustamaan kysyntää, ennakoimaan ja hallitsemaan varastotasoja ja optimoimaan logistiikkaa varmistaen tavaroiden ja resurssien sujuvan ja tehokkaan virtauksen.
- Ennakoiva huolto: Analysoimalla koneiden antureista saatua dataa koneoppiminen voi ennustaa, milloin laitteet todennäköisesti vikaantuvat, mikä mahdollistaa aikataulun mukaisen huollon ennen vikaantumista ja minimoi siten kalliit seisokkiajat.
- Kysynnän ennustaminen ja kuluttajakeskeinen valmistus: Analysoimalla markkinatrendejä ja ostomalleja koneoppiminen antaa valmistajille mahdollisuuden ennustaa kysyntää, mikä johtaa parempaan tuotesuunnitteluun ja reagoivampaan tuotantoon kuluttajien tarpeiden täyttämiseksi.
- Energiankulutuksen hallinta: Koneoppiminen voi analysoida energiankäyttömalleja optimointimahdollisuuksien tunnistamiseksi, mikä auttaa vähentämään sähkölaskuja ja pienentämään tehtaan hiilijalanjälkeä.
- Parannettu ihmisen ja robotin yhteistyö: Koneoppiminen voi parantaa ihmisen ja robotin vuorovaikutuksen turvallisuutta ja tehokkuutta tehtaan lattialla, mikä johtaa parempiin työoloihin ja lisääntyneeseen tuottavuuteen.
- Tuotesuunnittelu ja -kehitys: Koneoppiminen voi analysoida tuotantoprosessin tietoja tuotesuunnittelun tueksi, mikä auttaa minimoimaan mahdolliset viat ja parantamaan tuotteen yleistä laatua.
Koneoppimisen (ML) edut valmistuksessa
- Parantunut tuotteen laatu: Automatisoitu tarkastus ja prosessien optimointi johtavat vähemmän virheisiin ja korkeampaan tuotteiden laatuun.
- Lisääntynyt tehokkuus ja tuottavuus: Reaaliaikainen data-analyysi ja automatisoitu päätöksenteko johtavat tehokkaampaan toimintaan.
- Alentuneet kustannukset: Seisokkien, jätteen ja energiankulutuksen minimointi johtaa suoraan merkittäviin kustannussäästöihin.
- Lisääntynyt läpivirtaus: Tuotantoaikataulujen optimointi ja pullonkaulojen tunnistaminen auttavat valmistajia skaalaamaan tuotantoaan.
- Parempi turvallisuus ja kestävyys: Parempi prosessinohjaus ja energianhallinta edistävät turvallisempaa ja ympäristöystävällisempää valmistusympäristöä.
8. Esimerkki sovellutuksesta – Laatutaulu
Tuotanto- ja palveluprosessien aikana voidaan kerätä tuotteisiin kohdistunutta parametri- ja poikkeamadataa, joita yleisesti merkitään x:nä. Vastaavasti voidaan kerätä näihin datoihin liittyvää erilaista ulostulodataa Y. Sekä x:t että Y:t voivat olla jatkuvia tai diskreettejä parametri- tai poikkeamadataa. Koneoppimismalleilla voidaan luoda parametrien ja poikkeamadatojen avulla ennustemalli. Korrelaatiomalli ennustaa, mitä sillä hetkellä tai tulevaisuudessa tapahtuu. Korrelaatioennustemalli mahdollistaa kuitenkin erilaisten tehostavien tai parantavien valintojen tekemisen. Huom: Jos halutaan aidosti parantaa tai muuttaa prosessia, tarvitaan kausaalimalli ja satunnaistettu koedata (SPC, DoE, Six Sigma, Shainin, Taguchi jne.) Katso kuva 2.
Tarkastellaan Laatutaulu-artikkeleissa ja Laatutaulu-kirjassamme esiintyvää laatutaulua. Tauluun on kerätty työntekijöiden päivittäin havaitsemia poikkeamia x – virheen ilmenemismuoto – tuotekomponenteissa ja valmistuvassa tuotteessa. Mitatut arvot on myös muutettu hyvä/huono -asteikkoon eli lukumääräksi.
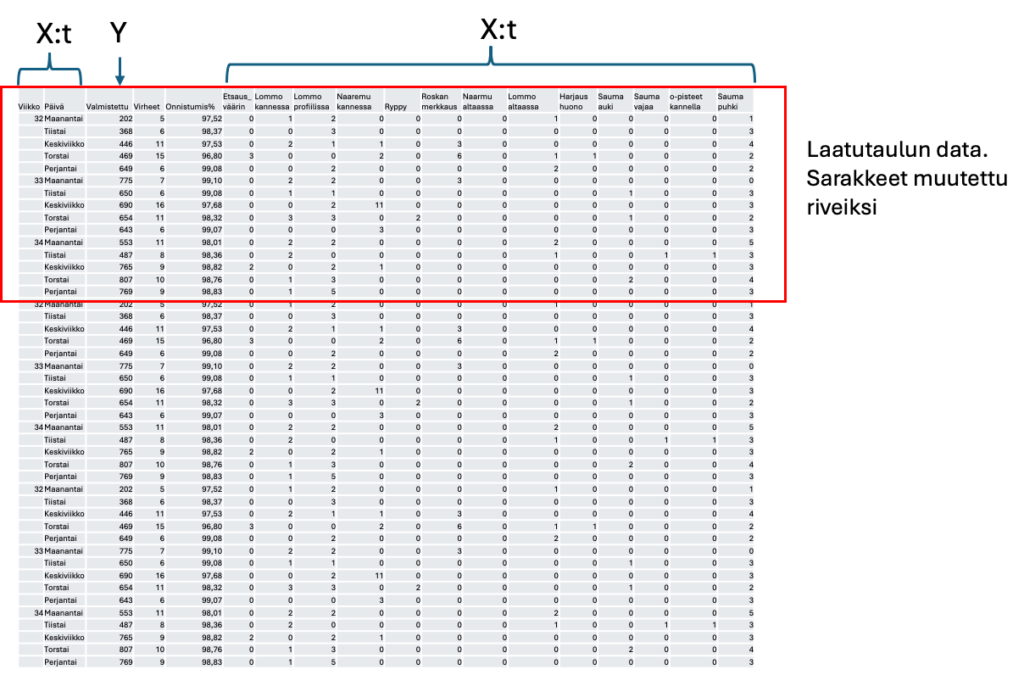
Laatutaulussa aika kulkee vaakatasossa ja sarakkeet muodostavat ajan. x-parametrit (tässä virheiden ilmenemismuoto) on vasemmassa laidassa. Y- tuotantomäärä) on ylin rivi.
Haluan esimerkkinä selvittää, mikä yhteys on tuotantomäärän Y ja virheiden ilmenemismuotojen määrien x välillä eli yhtälön Y=f(x). Kuinka paljon virheet ”verottavat” kapasiteettia? Voisiko virheet poistamalla kasvattaa tuotantomäärää? (Reklamaatioiden ja valitusten määrien (Y) välille voitaisiin vastaavalla tavalla luoda yhteys. Kuukausittaiset tiedot reklamaatioista on olemassa, mutta ilmenneiden virheiden kuukausittaisia ilmenemismuotoja ei ole säilytetty, joten analyysiä ei voi tehdä.)
Minitab laskee sarakkeittain, joten laatutaulussa olevan datan on käännettävä niin, että rivit muutetaan sarakkeiksi. Koska taulussa on 3 viikon eli 15 päivän data, käytän samoja datoja 3 kertaan, jotta laskenta onnistuu. Näin saan 45 dataa (riviä). Näin ei tietysti normaalisti tehdä, vaan kerätään aidosti kaikki data. Taulukossa 3 data käännettynä ja kerrattuna.
Taulukko 3. Laatutaulun data on käännetty Minitab-ohjelman vaatimaan sarakemuotoon.
9. Ennustemallin valinta ja laskenta
Kopioin laatutaulun käännetyn ja (tässä erityistapauksessa) kolminkertaistetun datan Minitab-worksheetille ja etsin mallin. Valitsen Predictive Analysics Module -> Automated Machine Learning -> Discover Best Model (Continuous Response)

Valitsen Y: Valmistettu ja jatkuvat muuttujat (virheiden ilmenemismuodot) ja ei jatkuvat muuttujat päivä ja viikko… ja OK. Kuva 7 oikea puoli.
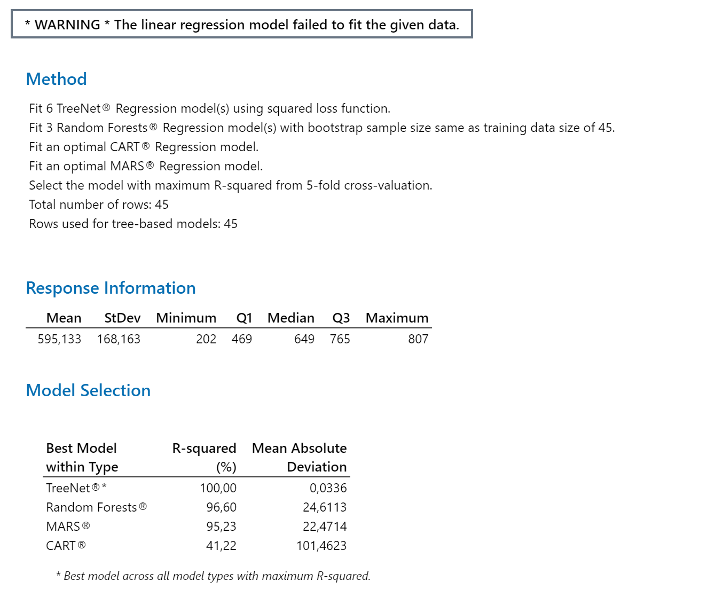
Ohjelma varoittaa, että tästä datasta ei voi tehdä regressiomallia. Niin tavanomaista! Tähän olen törmännyt viimeiset 30 vuotta. Mutta ei huolta, nyt muut mallit onnistuvat. Malli voidaan valita R-squared % (maksimin perusteella). Minitab luo jokaiselle mallille lukuisia eri malleja. Kuva 8.
Mallintajan tehtävänä on valita (Minitabin ohjaamana) paras malli. Tähän tietysti tarvitaan vähän koulutusta tai itseopiskelua! Algoritmeissa on useita mallintarkistusmenetelmiä, joita käytetään. Nyt kun data on kerrattu, en esittele ja käytä näitä. Valitsen malliksi MARS* mallin, jossa R-Squarred on 95,23 %. (Valinta tässä on lähinnä esimerkillinen).
MARS* malli
Minitab antaa MARS regressioyhtälöksi valmistusmäärälle ja havainnollisen kuvan siitä, mitkä tekijät ovat tärkeimpiä vaikuttajia. Malli muodostuu tässä 14:sta vektorista BF1-BF14.
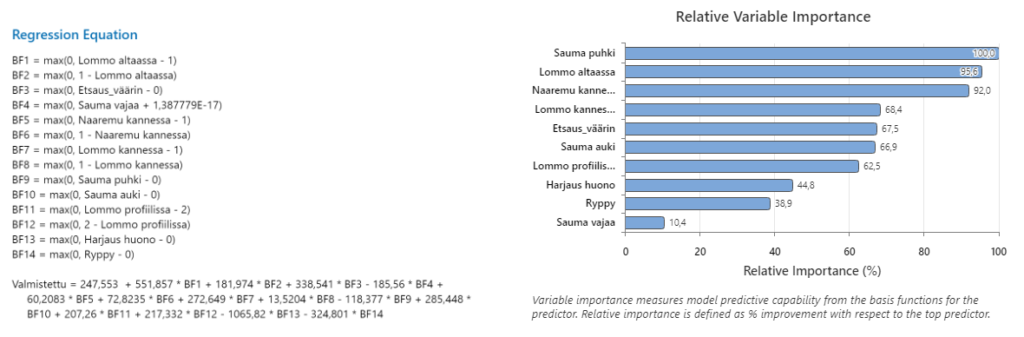
Maksimoidakseen tuotannon määrän, on tuotantojohtajan erityisesti kiinnitettävä huomiota Sauma puhki, Lommo altaassa ja Naarmu kannessa. Näin myös aikanaan tehtiin. Lukuisia kokeita ja Green Belt -töitä kohdistettiin näihin virheiden ilmenemismuotoihin – vetotyökaluihin, saumahitsaukseen jne.. Haettiin koneista ja laitteista kokeilla kausaalitekijöitä.
MARS-malli mahdollistaa ennustamisen (predict) ja optimoida asetusarvot. Yleensä mallit mahdollistavat vain ennustamisen.
Alkuperäinen kysymys oli, kuinka paljon enemmän tuotantoa tulisi, jos virheet olisivat poissa? Tuotannon keskiarvo oli 595 kpl/päivä.
Optimoidaan malli ”Responce optimizer” -algoritmilla. Malli antaa ennusteeksi 1080 kpl/päivä. Kasvu keskiarvoon 595 kpl/päivä on 81 % ja parhaimpaan päivään 807 kpl/päivä 34 %. Ei mitään pieniä parannuksia!
Tämän laatutaulun luomisen aikana keskusteltiin tuotantokapasiteetin lisäämisestä. Tämä johti uusien koneiden ja laitteiden ja myös henkilöstöä hankitaan. Jos edellä oleva malli (laajempi 2-3 kk) olisi ollut käytettävissä, ehkä kapasiteettilisäystä tai osaa olisi harkittu osana laadunparannusta. Yleensä yrityksille on paljon edullisempaa poistaa tuotanto ja palvelulinjoista virheet ja vähentää poikkeamat tuotteissa ja palveluissa. Yleisesti laatukustannusten osuus on 25 – 45 %. yritysten jalostusarvosta. Tähän asti ongelma on ollut, ettei palvelu- ja tuotantoprosessien malleja ole voitu tehdä datasta ja kun näin on ollut, dataakaan ei ole osattu kerätä oikealla tavalla (Laatutaulu). Esimerkiksi vikojen vaikutus on usein jäänyt puheen tasolle.
Antti Piirainen on esittänyt simuloidun Koneoppimismallin läpimenosta artikkelissa ”Analyyttisen ongelmanratkaisun kolme mallia – Osa 4”/13/.
Yhteenveto
Tekoäly ja Koneoppiminen (ML) mahdollistaa uuden tavan analysoida tuotanto- ja palveludataa. Uusi tapa käynnistää uuden vaiheen laatuteknologiassa – Laatu 4.0 ja LQC:n . Tähän asti tuotannosta ja palveluprosesseista tullut data on ollut lähes mahdotonta tai ainakin vaikeaa analysoida ”kokonaisuutena”. Regressiomallit ovat kaatuneet erityissyihin ja korrelaatioihin.
Kokeiden tekeminen ja ortogonaalimatriisien käyttö on erityisesti palvelualueella koettu ongelmalliseksi ja eettisesti tai muuten mahdottomaksi. Usein kuitenkin koe (DoE) onnistuu kyllä, mutta sitä vierastetaan. Miten olisi, jos aluksi kerättäisiin ”Laatutaulu” muodossa normaalia tuotanto- ja palveludataa ongelmallisista tai parannusta vaativista ulostulojen (Y) mahdollisista korreloivista (≈ vaikuttavista) tekijöistä suoraan tuotteesta/palvelusta. Tämä onnistuu kaikissa yrityksissä. Tästä datasta voidaan laatia analyyttinen korrelaatiomalli, joka mahdollistaa dataan perustuvan riskijohtamisen ja ohjaamisen ja kaiken lisäksi erityissyyt voidaan tunnistaa ja poistaa (=parantaa). Ehkä myös tulevaisuudessa päästään eroon tehottomasta ja kalliista lopputarkastuksesta ja reklamaatioista ja asiakasvalituksista! Seuraava askel on parannusmallien (kausaali) harkitseminen ja aidot kokeet, Six Sigma. Korrelaatioissa saattaa olla siemen myös kausaliteettien tunnistamiseen, joilla todellinen muutos voidaan tehdä ja tälle muutokselle ohjaava ennuste. Lean Six Sigma luo tähän hyvät edellytykset, koska Six Sigma rakentuu vahvasti ortogonaalimallien (DoE, Taguchi) ja kausaalisuuden varaan.
Lähteet:
- Trevor Hastie, Robert Tibshirani, Joerome Friedman: The Elements of Statistical Learning – Data Mining, Inference, and Prediction, Secon edition (2017)
- Carlos A. Escobar, Ruben Morales-Menendes: Machin Learning in Manufacturing – Quality 4.0 and the Zero Defects Vision (2024)
- Artikkeli: Tilastollinen ymmärrys ja käyttö (Osa 0), 2024
- Artikkeli: Laatutaulu – Osa 1: virheet ja hukka (Osa 1), 2024
- Artikkeli: Laatutaulu – Osa 2: kehitysvaiheet I-II (Osa 2), 2024
- Artikkeli: Laatutaulu – Osa 3: kehitysvaiheet III-VI (Osa 3), 2025
- Artikkeli: Laatutaulu – Osa 4: luominen, tiedon keruu ja käyttöönotto (Osa 4), 2025
- Artikkeli: Laatutaulu-Osa 5: Poikkeamatietojen analysointi (Osa 5), 2025
- Eero E. Karjalainen, Tanja Karjalainen: Laatutaulu – Tehokas menetelmä laadunohjaukseen ja parannukseen, 2024
- Artikkeli: Analyyttisen ongelmanratkaisun kolme mallia – Osa 1, 2025
- Artikkeli: Analyyttisen ongelmanratkaisun kolme mallia – Osa 2, 2025
- Artikkeli: Analyyttisen ongelmanratkaisun kolme mallia – Osa 3, 2025
- Artikkeli: Analyyttisen ongelmanratkaisun kolme mallia – Osa 4, 2025
- Walter A. Shewhart: Economic Control Of Quality Of Manufactured Product, 1931
- Artikkeli: Kausaliteetti-syy on ehto parannukselle, 2020
- Artikkeli: Muutanko yhtä tekijää vai useita tekijöitä? OFAT vai DoE?, 2013
- Artikkeli: Seulontakokeiden tehokas käyttö: joitakin käytännön kokemuksia, 2024
- DR Carlos Andre Reis Pinheiro and Mike Patetta: Introduction to Statistical and Machine Learning Methods for Data Science (2021)
- https://www.netsuite.com/portal/resource/articles/erp/machine-learning-in-manufacturing.shtml
- Marta Rotari, Murat Kulahci: Correlation to Causality; Quality Engineering 37:1, 162-172 (2024)

Tutustu kurssitarjontaamme!



Tilaa uutiskirje
Liity postituslistalle ja saat uusimmat artikkelit suoraan sähköpostiisi.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.
Liittymällä postituslistalle hyväksyt Quality Knowhow Karjalainen Oy:n tietosuojaselosteen ja Quality Knowhow Karjalainen Oy voi lähettää sinulle ajankohtaisia artikkeleita, videoita sekä tietoa ja tarjouksia kursseista, kirjoista sekä ohjelmistoista.
Tämä lomake on suojattu Google reCAPTCHA:lla. Lue tietosuojaseloste ja käyttöehdot.